 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSanjeev Khudanpur
On Speaker Attribution with SURT
Jan 28, 2024
The Streaming Unmixing and Recognition Transducer (SURT) has recently become a popular framework for continuous, streaming, multi-talker speech recognition (ASR). With advances in architecture, objectives, and mixture simulation methods, it was demonstrated that SURT can be an efficient streaming method for speaker-agnostic transcription of real meetings. In this work, we push this framework further by proposing methods to perform speaker-attributed transcription with SURT, for both short mixtures and long recordings. We achieve this by adding an auxiliary speaker branch to SURT, and synchronizing its label prediction with ASR token prediction through HAT-style blank factorization. In order to ensure consistency in relative speaker labels across different utterance groups in a recording, we propose "speaker prefixing" -- appending each chunk with high-confidence frames of speakers identified in previous chunks, to establish the relative order. We perform extensive ablation experiments on synthetic LibriSpeech mixtures to validate our design choices, and demonstrate the efficacy of our final model on the AMI corpus.
Enhancing Code-switching Speech Recognition with Interactive Language Biases
Sep 29, 2023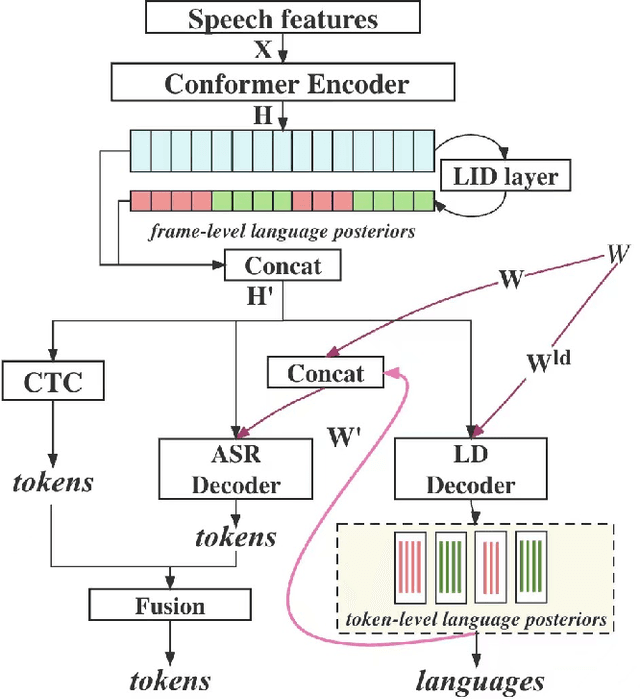

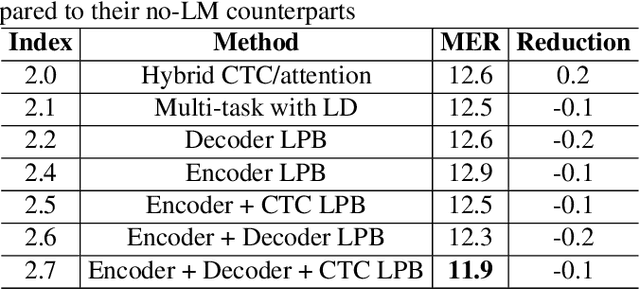
Languages usually switch within a multilingual speech signal, especially in a bilingual society. This phenomenon is referred to as code-switching (CS), making automatic speech recognition (ASR) challenging under a multilingual scenario. We propose to improve CS-ASR by biasing the hybrid CTC/attention ASR model with multi-level language information comprising frame- and token-level language posteriors. The interaction between various resolutions of language biases is subsequently explored in this work. We conducted experiments on datasets from the ASRU 2019 code-switching challenge. Compared to the baseline, the proposed interactive language biases (ILB) method achieves higher performance and ablation studies highlight the effects of different language biases and their interactions. In addition, the results presented indicate that language bias implicitly enhances internal language modeling, leading to performance degradation after employing an external language model.
Speech collage: code-switched audio generation by collaging monolingual corpora
Sep 27, 2023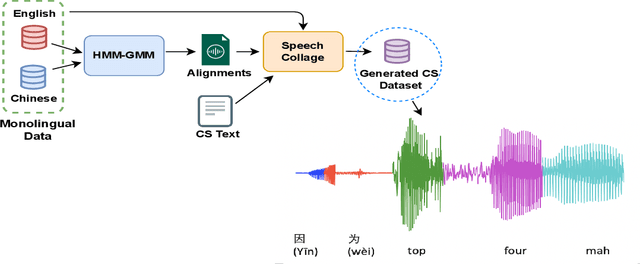
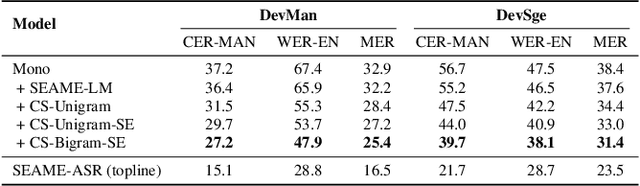
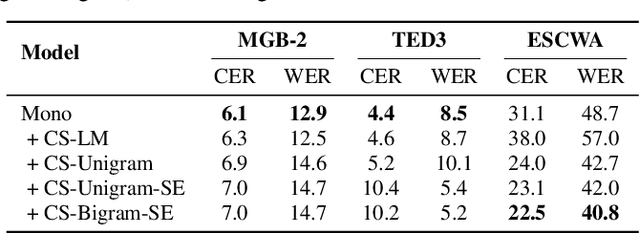
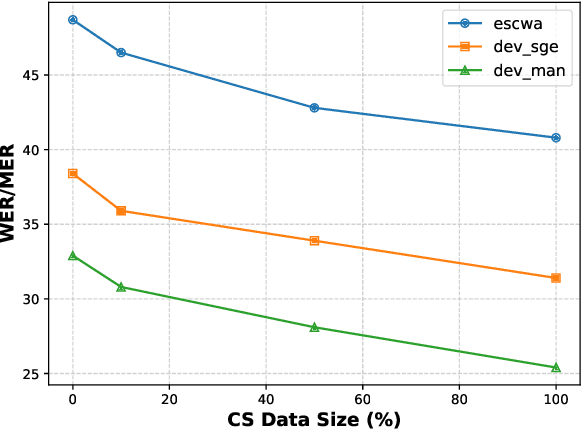
Designing effective automatic speech recognition (ASR) systems for Code-Switching (CS) often depends on the availability of the transcribed CS resources. To address data scarcity, this paper introduces Speech Collage, a method that synthesizes CS data from monolingual corpora by splicing audio segments. We further improve the smoothness quality of audio generation using an overlap-add approach. We investigate the impact of generated data on speech recognition in two scenarios: using in-domain CS text and a zero-shot approach with synthesized CS text. Empirical results highlight up to 34.4% and 16.2% relative reductions in Mixed-Error Rate and Word-Error Rate for in-domain and zero-shot scenarios, respectively. Lastly, we demonstrate that CS augmentation bolsters the model's code-switching inclination and reduces its monolingual bias.
Enhancing End-to-End Conversational Speech Translation Through Target Language Context Utilization
Sep 27, 2023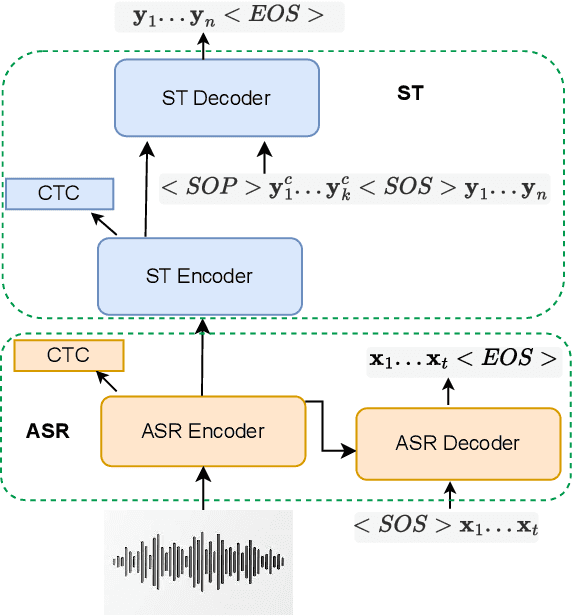
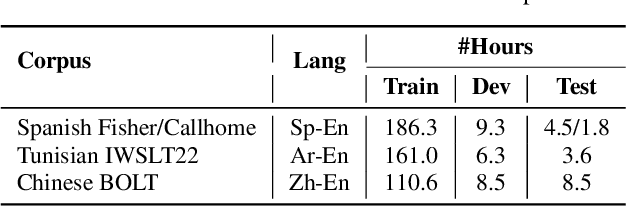
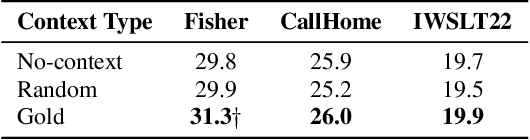
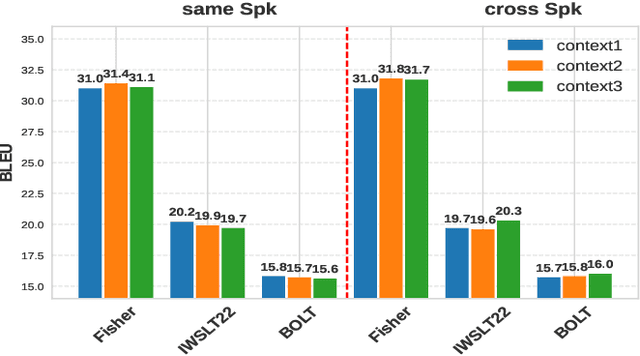
Incorporating longer context has been shown to benefit machine translation, but the inclusion of context in end-to-end speech translation (E2E-ST) remains under-studied. To bridge this gap, we introduce target language context in E2E-ST, enhancing coherence and overcoming memory constraints of extended audio segments. Additionally, we propose context dropout to ensure robustness to the absence of context, and further improve performance by adding speaker information. Our proposed contextual E2E-ST outperforms the isolated utterance-based E2E-ST approach. Lastly, we demonstrate that in conversational speech, contextual information primarily contributes to capturing context style, as well as resolving anaphora and named entities.
Learning from Flawed Data: Weakly Supervised Automatic Speech Recognition
Sep 26, 2023
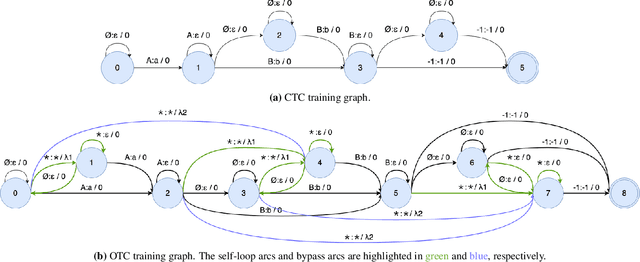
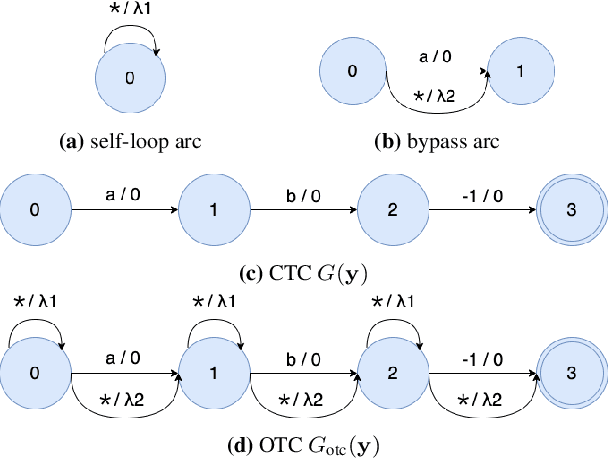

Training automatic speech recognition (ASR) systems requires large amounts of well-curated paired data. However, human annotators usually perform "non-verbatim" transcription, which can result in poorly trained models. In this paper, we propose Omni-temporal Classification (OTC), a novel training criterion that explicitly incorporates label uncertainties originating from such weak supervision. This allows the model to effectively learn speech-text alignments while accommodating errors present in the training transcripts. OTC extends the conventional CTC objective for imperfect transcripts by leveraging weighted finite state transducers. Through experiments conducted on the LibriSpeech and LibriVox datasets, we demonstrate that training ASR models with OTC avoids performance degradation even with transcripts containing up to 70% errors, a scenario where CTC models fail completely. Our implementation is available at https://github.com/k2-fsa/icefall.
The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios
Jul 14, 2023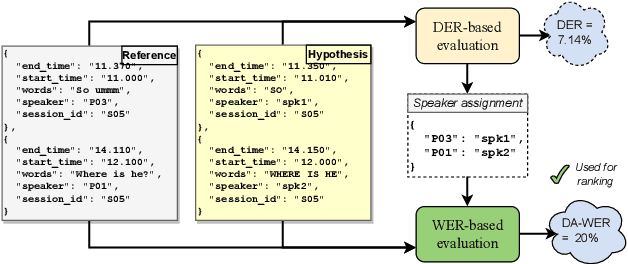
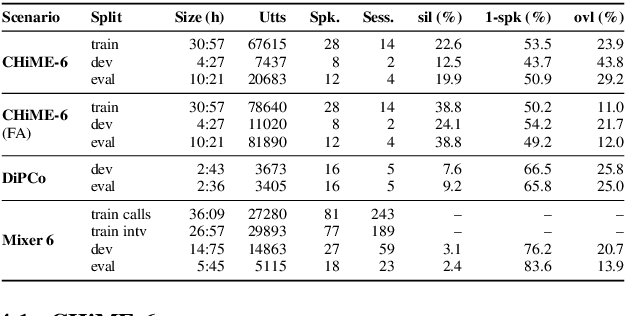
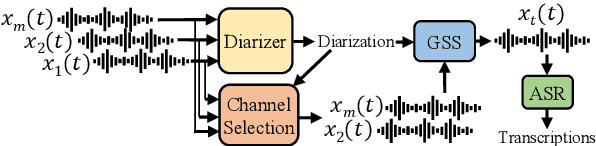
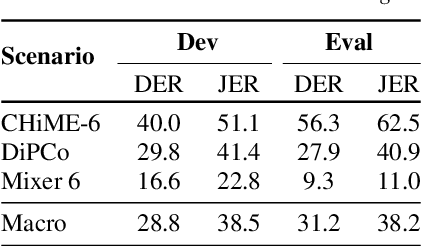
The CHiME challenges have played a significant role in the development and evaluation of robust automatic speech recognition (ASR) systems. We introduce the CHiME-7 distant ASR (DASR) task, within the 7th CHiME challenge. This task comprises joint ASR and diarization in far-field settings with multiple, and possibly heterogeneous, recording devices. Different from previous challenges, we evaluate systems on 3 diverse scenarios: CHiME-6, DiPCo, and Mixer 6. The goal is for participants to devise a single system that can generalize across different array geometries and use cases with no a-priori information. Another departure from earlier CHiME iterations is that participants are allowed to use open-source pre-trained models and datasets. In this paper, we describe the challenge design, motivation, and fundamental research questions in detail. We also present the baseline system, which is fully array-topology agnostic and features multi-channel diarization, channel selection, guided source separation and a robust ASR model that leverages self-supervised speech representations (SSLR).
HK-LegiCoST: Leveraging Non-Verbatim Transcripts for Speech Translation
Jun 20, 2023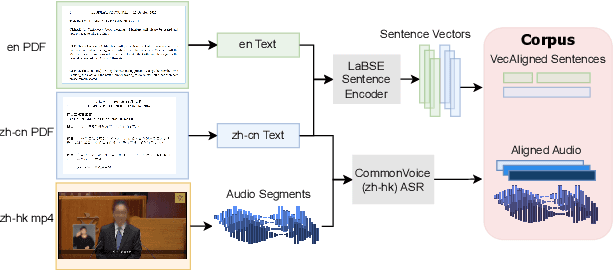
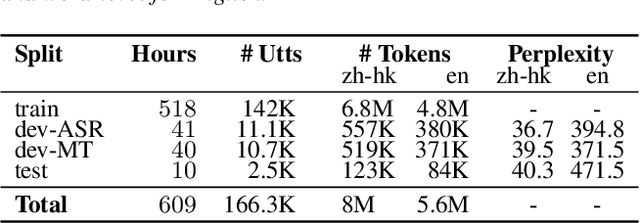
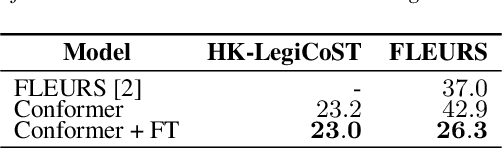

We introduce HK-LegiCoST, a new three-way parallel corpus of Cantonese-English translations, containing 600+ hours of Cantonese audio, its standard traditional Chinese transcript, and English translation, segmented and aligned at the sentence level. We describe the notable challenges in corpus preparation: segmentation, alignment of long audio recordings, and sentence-level alignment with non-verbatim transcripts. Such transcripts make the corpus suitable for speech translation research when there are significant differences between the spoken and written forms of the source language. Due to its large size, we are able to demonstrate competitive speech translation baselines on HK-LegiCoST and extend them to promising cross-corpus results on the FLEURS Cantonese subset. These results deliver insights into speech recognition and translation research in languages for which non-verbatim or ``noisy'' transcription is common due to various factors, including vernacular and dialectal speech.
SURT 2.0: Advances in Transducer-based Multi-talker Speech Recognition
Jun 18, 2023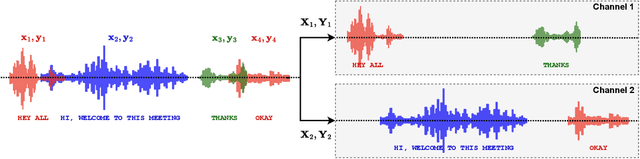

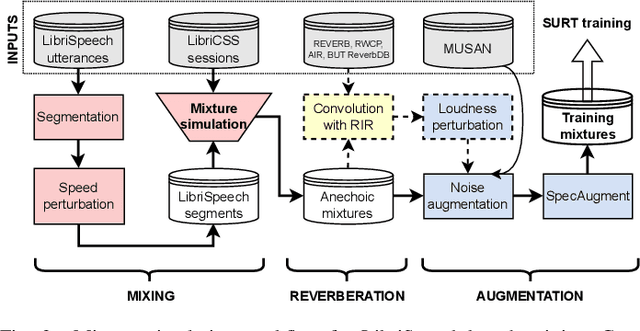
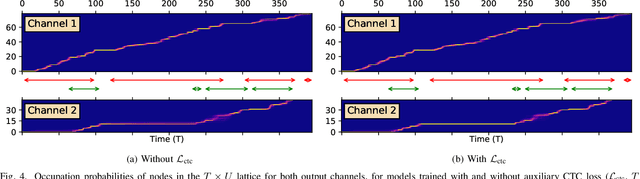
The Streaming Unmixing and Recognition Transducer (SURT) model was proposed recently as an end-to-end approach for continuous, streaming, multi-talker speech recognition (ASR). Despite impressive results on multi-turn meetings, SURT has notable limitations: (i) it suffers from leakage and omission related errors; (ii) it is computationally expensive, due to which it has not seen adoption in academia; and (iii) it has only been evaluated on synthetic mixtures. In this work, we propose several modifications to the original SURT which are carefully designed to fix the above limitations. In particular, we (i) change the unmixing module to a mask estimator that uses dual-path modeling, (ii) use a streaming zipformer encoder and a stateless decoder for the transducer, (iii) perform mixture simulation using force-aligned subsegments, (iv) pre-train the transducer on single-speaker data, (v) use auxiliary objectives in the form of masking loss and encoder CTC loss, and (vi) perform domain adaptation for far-field recognition. We show that our modifications allow SURT 2.0 to outperform its predecessor in terms of multi-talker ASR results, while being efficient enough to train with academic resources. We conduct our evaluations on 3 publicly available meeting benchmarks -- LibriCSS, AMI, and ICSI, where our best model achieves WERs of 16.9%, 44.6% and 32.2%, respectively, on far-field unsegmented recordings. We release training recipes and pre-trained models: https://sites.google.com/view/surt2.
Bypass Temporal Classification: Weakly Supervised Automatic Speech Recognition with Imperfect Transcripts
Jun 01, 2023
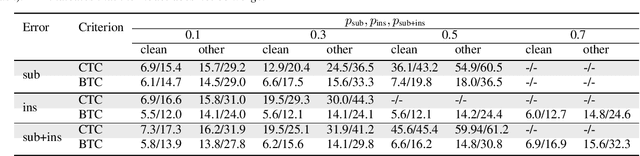
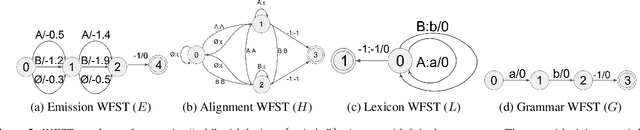
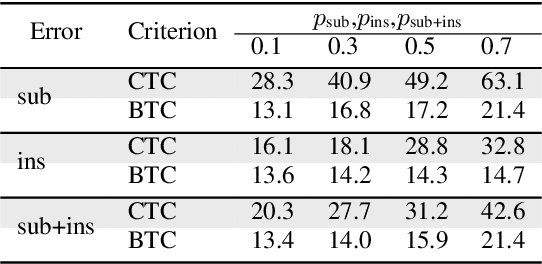
This paper presents a novel algorithm for building an automatic speech recognition (ASR) model with imperfect training data. Imperfectly transcribed speech is a prevalent issue in human-annotated speech corpora, which degrades the performance of ASR models. To address this problem, we propose Bypass Temporal Classification (BTC) as an expansion of the Connectionist Temporal Classification (CTC) criterion. BTC explicitly encodes the uncertainties associated with transcripts during training. This is accomplished by enhancing the flexibility of the training graph, which is implemented as a weighted finite-state transducer (WFST) composition. The proposed algorithm improves the robustness and accuracy of ASR systems, particularly when working with imprecisely transcribed speech corpora. Our implementation will be open-sourced.
MERLIon CCS Challenge Evaluation Plan
May 31, 2023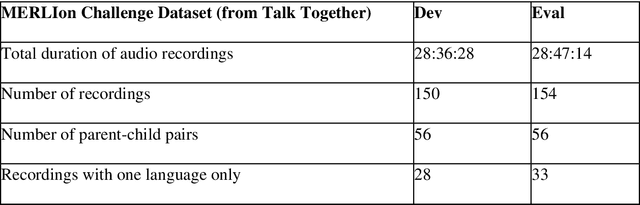
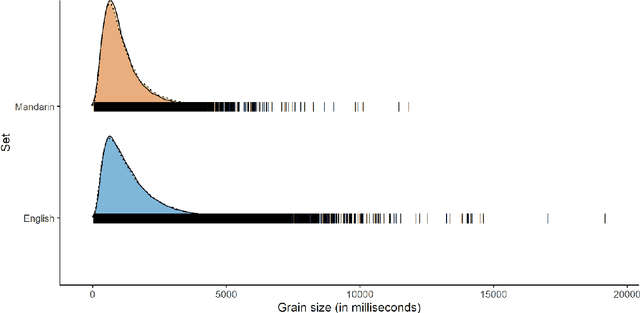
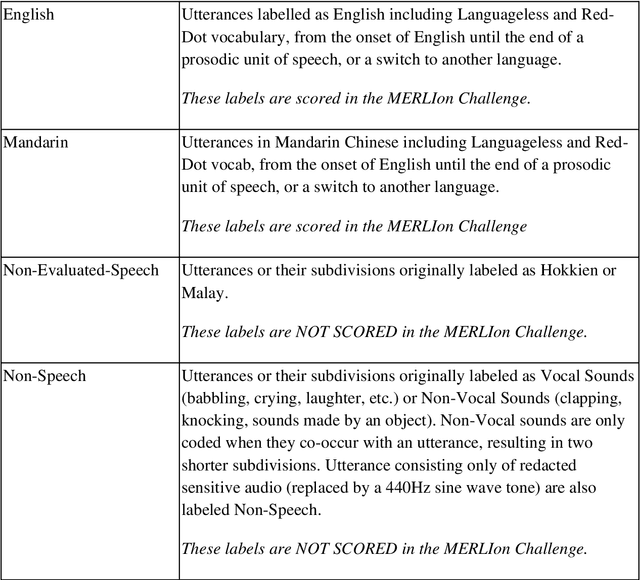
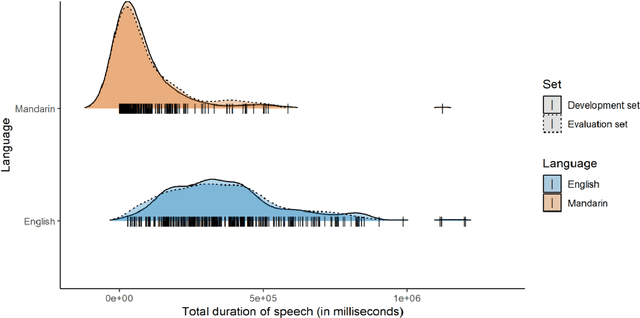
This paper introduces the inaugural Multilingual Everyday Recordings- Language Identification on Code-Switched Child-Directed Speech (MERLIon CCS) Challenge, focused on developing robust language identification and language diarization systems that are reliable for non-standard, accented, spontaneous code-switched, child-directed speech collected via Zoom. Aligning closely with Interspeech 2023 theme, the main objectives of this inaugural challenge are to present a unique first-of-its-kind Zoom videocall dataset featuring English-Mandarin spontaneous code-switched child-directed speech, benchmark the current and novel language identification and language diarization systems in a code-switching scenario including extremely short utterances, and test the robustness of such systems under accented speech. The MERLIon CCS challenge features two task: language identification (Task 1) and language diarization (Task 2). Two tracks, open and closed, are available for each task, differing by the volume of data systems can be trained on. This paper describes the dataset, dataset annotation protocol, challenge tasks, open and closed tracks, evaluation metrics, and evaluation protocol.