 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSen Liang
TIER: Text-Image Encoder-based Regression for AIGC Image Quality Assessment
Jan 11, 2024
Recently, AIGC image quality assessment (AIGCIQA), which aims to assess the quality of AI-generated images (AIGIs) from a human perception perspective, has emerged as a new topic in computer vision. Unlike common image quality assessment tasks where images are derived from original ones distorted by noise, blur, and compression, \textit{etc.}, in AIGCIQA tasks, images are typically generated by generative models using text prompts. Considerable efforts have been made in the past years to advance AIGCIQA. However, most existing AIGCIQA methods regress predicted scores directly from individual generated images, overlooking the information contained in the text prompts of these images. This oversight partially limits the performance of these AIGCIQA methods. To address this issue, we propose a text-image encoder-based regression (TIER) framework. Specifically, we process the generated images and their corresponding text prompts as inputs, utilizing a text encoder and an image encoder to extract features from these text prompts and generated images, respectively. To demonstrate the effectiveness of our proposed TIER method, we conduct extensive experiments on several mainstream AIGCIQA databases, including AGIQA-1K, AGIQA-3K, and AIGCIQA2023. The experimental results indicate that our proposed TIER method generally demonstrates superior performance compared to baseline in most cases.
AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis
Mar 20, 2021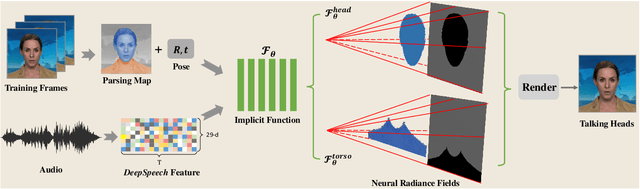
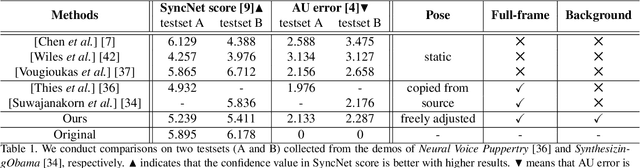
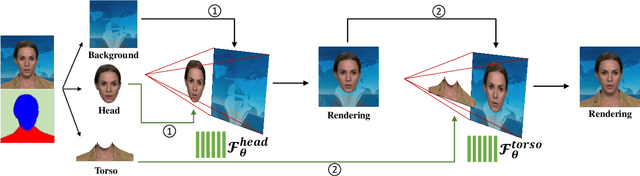
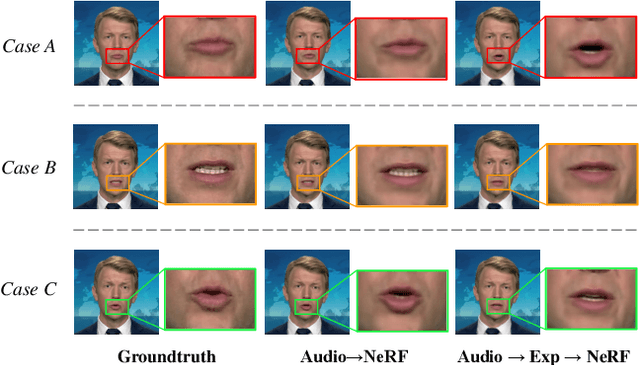
Generating high-fidelity talking head video by fitting with the input audio sequence is a challenging problem that receives considerable attentions recently. In this paper, we address this problem with the aid of neural scene representation networks. Our method is completely different from existing methods that rely on intermediate representations like 2D landmarks or 3D face models to bridge the gap between audio input and video output. Specifically, the feature of input audio signal is directly fed into a conditional implicit function to generate a dynamic neural radiance field, from which a high-fidelity talking-head video corresponding to the audio signal is synthesized using volume rendering. Another advantage of our framework is that not only the head (with hair) region is synthesized as previous methods did, but also the upper body is generated via two individual neural radiance fields. Experimental results demonstrate that our novel framework can (1) produce high-fidelity and natural results, and (2) support free adjustment of audio signals, viewing directions, and background images.
Cross-view Relation Networks for Mammogram Mass Detection
Jul 01, 2019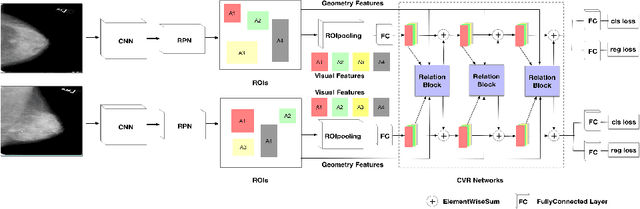
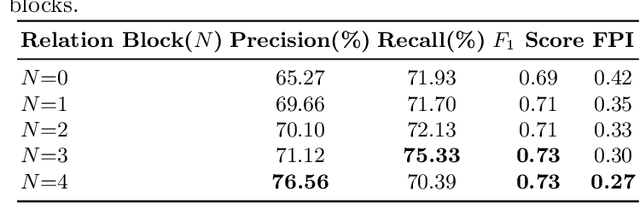
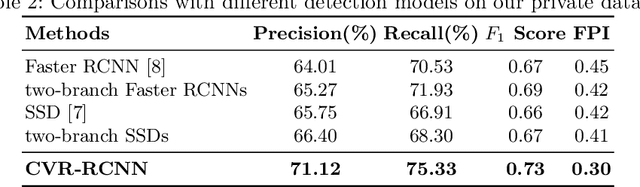
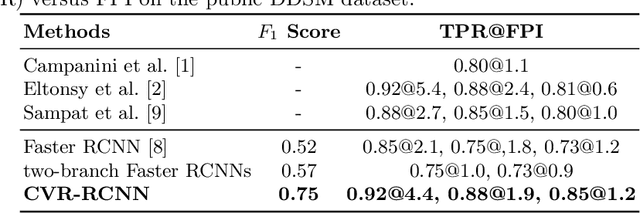
Mammogram is the most effective imaging modality for the mass lesion detection of breast cancer at the early stage. The information from the two paired views (i.e., medio-lateral oblique and cranio-caudal) are highly relational and complementary, and this is crucial for doctors' decisions in clinical practice. However, existing mass detection methods do not consider jointly learning effective features from the two relational views. To address this issue, this paper proposes a novel mammogram mass detection framework, termed Cross-View Relation Region-based Convolutional Neural Networks (CVR-RCNN). The proposed CVR-RCNN is expected to capture the latent relation information between the corresponding mass region of interests (ROIs) from the two paired views. Evaluations on a new large-scale private dataset and a public mammogram dataset show that the proposed CVR-RCNN outperforms existing state-of-the-art mass detection methods. Meanwhile, our experimental results suggest that incorporating the relation information across two views helps to train a superior detection model, which is a promising avenue for mammogram mass detection.
Group-Attention Single-Shot Detector (GA-SSD): Finding Pulmonary Nodules in Large-Scale CT Images
Dec 18, 2018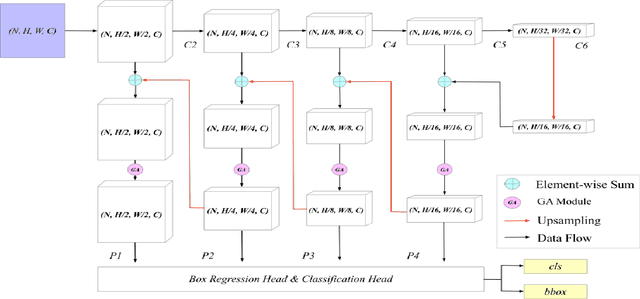
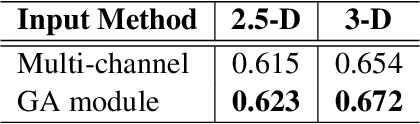
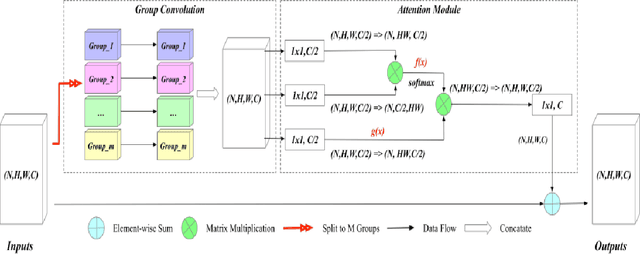

Early diagnosis of pulmonary nodules (PNs) can improve the survival rate of patients and yet is a challenging task for radiologists due to the image noise and artifacts in computed tomography (CT) images. In this paper, we propose a novel and effective abnormality detector implementing the attention mechanism and group convolution on 3D single-shot detector (SSD) called group-attention SSD (GA-SSD). We find that group convolution is effective in extracting rich context information between continuous slices, and attention network can learn the target features automatically. We collected a large-scale dataset that contained 4146 CT scans with annotations of varying types and sizes of PNs (even PNs smaller than 3mm were annotated). To the best of our knowledge, this dataset is the largest cohort with relatively complete annotations for PNs detection. Our experimental results show that the proposed group-attention SSD outperforms the classic SSD framework as well as the state-of-the-art 3DCNN, especially on some challenging lesion types.