 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenbo Wang
NeuSDFusion: A Spatial-Aware Generative Model for 3D Shape Completion, Reconstruction, and Generation
Mar 27, 2024
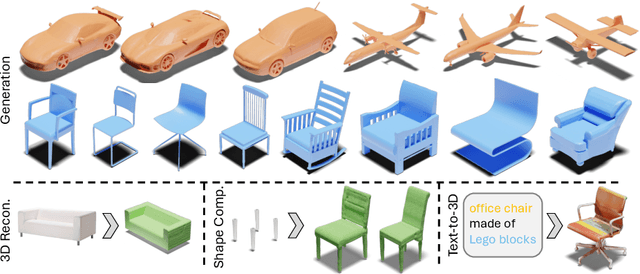
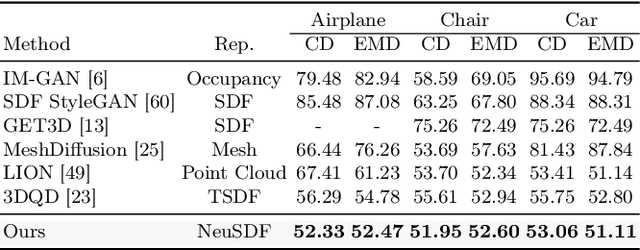

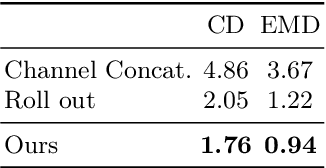
3D shape generation aims to produce innovative 3D content adhering to specific conditions and constraints. Existing methods often decompose 3D shapes into a sequence of localized components, treating each element in isolation without considering spatial consistency. As a result, these approaches exhibit limited versatility in 3D data representation and shape generation, hindering their ability to generate highly diverse 3D shapes that comply with the specified constraints. In this paper, we introduce a novel spatial-aware 3D shape generation framework that leverages 2D plane representations for enhanced 3D shape modeling. To ensure spatial coherence and reduce memory usage, we incorporate a hybrid shape representation technique that directly learns a continuous signed distance field representation of the 3D shape using orthogonal 2D planes. Additionally, we meticulously enforce spatial correspondences across distinct planes using a transformer-based autoencoder structure, promoting the preservation of spatial relationships in the generated 3D shapes. This yields an algorithm that consistently outperforms state-of-the-art 3D shape generation methods on various tasks, including unconditional shape generation, multi-modal shape completion, single-view reconstruction, and text-to-shape synthesis.
BlockFusion: Expandable 3D Scene Generation using Latent Tri-plane Extrapolation
Jan 31, 2024We present BlockFusion, a diffusion-based model that generates 3D scenes as unit blocks and seamlessly incorporates new blocks to extend the scene. BlockFusion is trained using datasets of 3D blocks that are randomly cropped from complete 3D scene meshes. Through per-block fitting, all training blocks are converted into the hybrid neural fields: with a tri-plane containing the geometry features, followed by a Multi-layer Perceptron (MLP) for decoding the signed distance values. A variational auto-encoder is employed to compress the tri-planes into the latent tri-plane space, on which the denoising diffusion process is performed. Diffusion applied to the latent representations allows for high-quality and diverse 3D scene generation. To expand a scene during generation, one needs only to append empty blocks to overlap with the current scene and extrapolate existing latent tri-planes to populate new blocks. The extrapolation is done by conditioning the generation process with the feature samples from the overlapping tri-planes during the denoising iterations. Latent tri-plane extrapolation produces semantically and geometrically meaningful transitions that harmoniously blend with the existing scene. A 2D layout conditioning mechanism is used to control the placement and arrangement of scene elements. Experimental results indicate that BlockFusion is capable of generating diverse, geometrically consistent and unbounded large 3D scenes with unprecedented high-quality shapes in both indoor and outdoor scenarios.
${S}^{2}$Net: Accurate Panorama Depth Estimation on Spherical Surface
Jan 14, 2023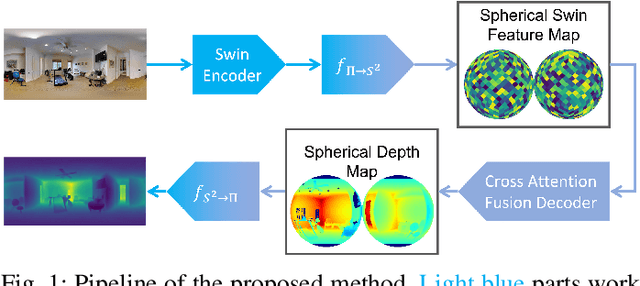

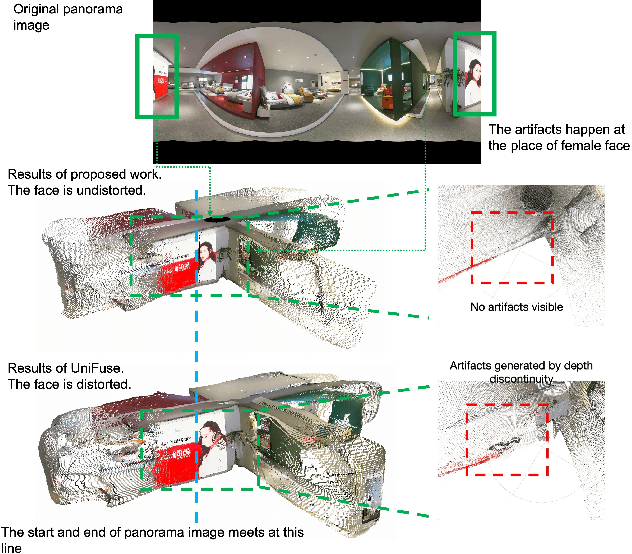
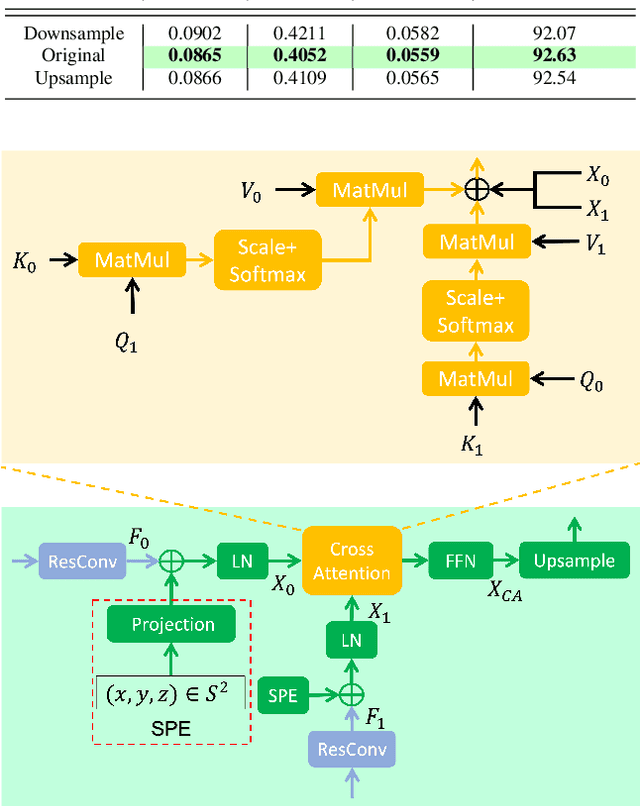
Monocular depth estimation is an ambiguous problem, thus global structural cues play an important role in current data-driven single-view depth estimation methods. Panorama images capture the complete spatial information of their surroundings utilizing the equirectangular projection which introduces large distortion. This requires the depth estimation method to be able to handle the distortion and extract global context information from the image. In this paper, we propose an end-to-end deep network for monocular panorama depth estimation on a unit spherical surface. Specifically, we project the feature maps extracted from equirectangular images onto unit spherical surface sampled by uniformly distributed grids, where the decoder network can aggregate the information from the distortion-reduced feature maps. Meanwhile, we propose a global cross-attention-based fusion module to fuse the feature maps from skip connection and enhance the ability to obtain global context. Experiments are conducted on five panorama depth estimation datasets, and the results demonstrate that the proposed method substantially outperforms previous state-of-the-art methods. All related codes will be open-sourced in the upcoming days.