 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeokju Cho
Unifying Feature and Cost Aggregation with Transformers for Semantic and Visual Correspondence
Mar 17, 2024
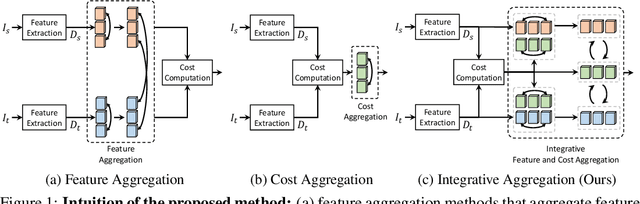
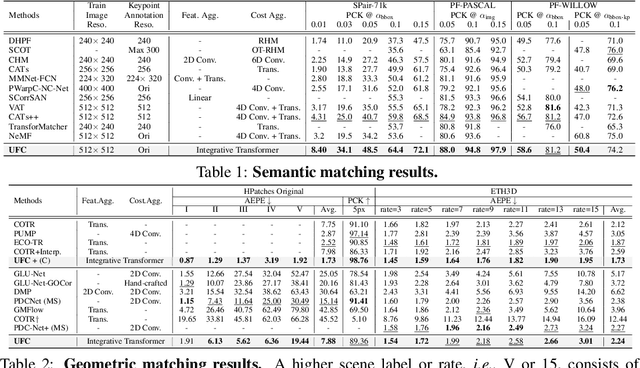


This paper introduces a Transformer-based integrative feature and cost aggregation network designed for dense matching tasks. In the context of dense matching, many works benefit from one of two forms of aggregation: feature aggregation, which pertains to the alignment of similar features, or cost aggregation, a procedure aimed at instilling coherence in the flow estimates across neighboring pixels. In this work, we first show that feature aggregation and cost aggregation exhibit distinct characteristics and reveal the potential for substantial benefits stemming from the judicious use of both aggregation processes. We then introduce a simple yet effective architecture that harnesses self- and cross-attention mechanisms to show that our approach unifies feature aggregation and cost aggregation and effectively harnesses the strengths of both techniques. Within the proposed attention layers, the features and cost volume both complement each other, and the attention layers are interleaved through a coarse-to-fine design to further promote accurate correspondence estimation. Finally at inference, our network produces multi-scale predictions, computes their confidence scores, and selects the most confident flow for final prediction. Our framework is evaluated on standard benchmarks for semantic matching, and also applied to geometric matching, where we show that our approach achieves significant improvements compared to existing methods.
DäRF: Boosting Radiance Fields from Sparse Inputs with Monocular Depth Adaptation
May 30, 2023



Neural radiance fields (NeRF) shows powerful performance in novel view synthesis and 3D geometry reconstruction, but it suffers from critical performance degradation when the number of known viewpoints is drastically reduced. Existing works attempt to overcome this problem by employing external priors, but their success is limited to certain types of scenes or datasets. Employing monocular depth estimation (MDE) networks, pretrained on large-scale RGB-D datasets, with powerful generalization capability would be a key to solving this problem: however, using MDE in conjunction with NeRF comes with a new set of challenges due to various ambiguity problems exhibited by monocular depths. In this light, we propose a novel framework, dubbed D\"aRF, that achieves robust NeRF reconstruction with a handful of real-world images by combining the strengths of NeRF and monocular depth estimation through online complementary training. Our framework imposes the MDE network's powerful geometry prior to NeRF representation at both seen and unseen viewpoints to enhance its robustness and coherence. In addition, we overcome the ambiguity problems of monocular depths through patch-wise scale-shift fitting and geometry distillation, which adapts the MDE network to produce depths aligned accurately with NeRF geometry. Experiments show our framework achieves state-of-the-art results both quantitatively and qualitatively, demonstrating consistent and reliable performance in both indoor and outdoor real-world datasets. Project page is available at https://ku-cvlab.github.io/DaRF/.
CAT-Seg: Cost Aggregation for Open-Vocabulary Semantic Segmentation
Mar 21, 2023

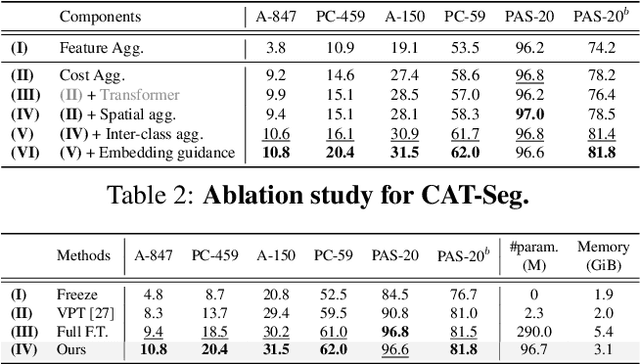

Existing works on open-vocabulary semantic segmentation have utilized large-scale vision-language models, such as CLIP, to leverage their exceptional open-vocabulary recognition capabilities. However, the problem of transferring these capabilities learned from image-level supervision to the pixel-level task of segmentation and addressing arbitrary unseen categories at inference makes this task challenging. To address these issues, we aim to attentively relate objects within an image to given categories by leveraging relational information among class categories and visual semantics through aggregation, while also adapting the CLIP representations to the pixel-level task. However, we observe that direct optimization of the CLIP embeddings can harm its open-vocabulary capabilities. In this regard, we propose an alternative approach to optimize the image-text similarity map, i.e. the cost map, using a novel cost aggregation-based method. Our framework, namely CAT-Seg, achieves state-of-the-art performance across all benchmarks. We provide extensive ablation studies to validate our choices. Project page: https://ku-cvlab.github.io/CAT-Seg/.
DiffFace: Diffusion-based Face Swapping with Facial Guidance
Dec 27, 2022



In this paper, we propose a diffusion-based face swapping framework for the first time, called DiffFace, composed of training ID conditional DDPM, sampling with facial guidance, and a target-preserving blending. In specific, in the training process, the ID conditional DDPM is trained to generate face images with the desired identity. In the sampling process, we use the off-the-shelf facial expert models to make the model transfer source identity while preserving target attributes faithfully. During this process, to preserve the background of the target image and obtain the desired face swapping result, we additionally propose a target-preserving blending strategy. It helps our model to keep the attributes of the target face from noise while transferring the source facial identity. In addition, without any re-training, our model can flexibly apply additional facial guidance and adaptively control the ID-attributes trade-off to achieve the desired results. To the best of our knowledge, this is the first approach that applies the diffusion model in face swapping task. Compared with previous GAN-based approaches, by taking advantage of the diffusion model for the face swapping task, DiffFace achieves better benefits such as training stability, high fidelity, diversity of the samples, and controllability. Extensive experiments show that our DiffFace is comparable or superior to the state-of-the-art methods on several standard face swapping benchmarks.
Neural Matching Fields: Implicit Representation of Matching Fields for Visual Correspondence
Oct 06, 2022



Existing pipelines of semantic correspondence commonly include extracting high-level semantic features for the invariance against intra-class variations and background clutters. This architecture, however, inevitably results in a low-resolution matching field that additionally requires an ad-hoc interpolation process as a post-processing for converting it into a high-resolution one, certainly limiting the overall performance of matching results. To overcome this, inspired by recent success of implicit neural representation, we present a novel method for semantic correspondence, called Neural Matching Field (NeMF). However, complicacy and high-dimensionality of a 4D matching field are the major hindrances, which we propose a cost embedding network to process a coarse cost volume to use as a guidance for establishing high-precision matching field through the following fully-connected network. Nevertheless, learning a high-dimensional matching field remains challenging mainly due to computational complexity, since a naive exhaustive inference would require querying from all pixels in the 4D space to infer pixel-wise correspondences. To overcome this, we propose adequate training and inference procedures, which in the training phase, we randomly sample matching candidates and in the inference phase, we iteratively performs PatchMatch-based inference and coordinate optimization at test time. With these combined, competitive results are attained on several standard benchmarks for semantic correspondence. Code and pre-trained weights are available at https://ku-cvlab.github.io/NeMF/.
MIDMs: Matching Interleaved Diffusion Models for Exemplar-based Image Translation
Sep 23, 2022



We present a novel method for exemplar-based image translation, called matching interleaved diffusion models (MIDMs). Most existing methods for this task were formulated as GAN-based matching-then-generation framework. However, in this framework, matching errors induced by the difficulty of semantic matching across cross-domain, e.g., sketch and photo, can be easily propagated to the generation step, which in turn leads to degenerated results. Motivated by the recent success of diffusion models overcoming the shortcomings of GANs, we incorporate the diffusion models to overcome these limitations. Specifically, we formulate a diffusion-based matching-and-generation framework that interleaves cross-domain matching and diffusion steps in the latent space by iteratively feeding the intermediate warp into the noising process and denoising it to generate a translated image. In addition, to improve the reliability of the diffusion process, we design a confidence-aware process using cycle-consistency to consider only confident regions during translation. Experimental results show that our MIDMs generate more plausible images than state-of-the-art methods.
Integrative Feature and Cost Aggregation with Transformers for Dense Correspondence
Sep 20, 2022



We present a novel architecture for dense correspondence. The current state-of-the-art are Transformer-based approaches that focus on either feature descriptors or cost volume aggregation. However, they generally aggregate one or the other but not both, though joint aggregation would boost each other by providing information that one has but other lacks, i.e., structural or semantic information of an image, or pixel-wise matching similarity. In this work, we propose a novel Transformer-based network that interleaves both forms of aggregations in a way that exploits their complementary information. Specifically, we design a self-attention layer that leverages the descriptor to disambiguate the noisy cost volume and that also utilizes the cost volume to aggregate features in a manner that promotes accurate matching. A subsequent cross-attention layer performs further aggregation conditioned on the descriptors of both images and aided by the aggregated outputs of earlier layers. We further boost the performance with hierarchical processing, in which coarser level aggregations guide those at finer levels. We evaluate the effectiveness of the proposed method on dense matching tasks and achieve state-of-the-art performance on all the major benchmarks. Extensive ablation studies are also provided to validate our design choices.
Cost Aggregation with 4D Convolutional Swin Transformer for Few-Shot Segmentation
Jul 22, 2022



This paper presents a novel cost aggregation network, called Volumetric Aggregation with Transformers (VAT), for few-shot segmentation. The use of transformers can benefit correlation map aggregation through self-attention over a global receptive field. However, the tokenization of a correlation map for transformer processing can be detrimental, because the discontinuity at token boundaries reduces the local context available near the token edges and decreases inductive bias. To address this problem, we propose a 4D Convolutional Swin Transformer, where a high-dimensional Swin Transformer is preceded by a series of small-kernel convolutions that impart local context to all pixels and introduce convolutional inductive bias. We additionally boost aggregation performance by applying transformers within a pyramidal structure, where aggregation at a coarser level guides aggregation at a finer level. Noise in the transformer output is then filtered in the subsequent decoder with the help of the query's appearance embedding. With this model, a new state-of-the-art is set for all the standard benchmarks in few-shot segmentation. It is shown that VAT attains state-of-the-art performance for semantic correspondence as well, where cost aggregation also plays a central role.
CATs++: Boosting Cost Aggregation with Convolutions and Transformers
Feb 14, 2022



Cost aggregation is a highly important process in image matching tasks, which aims to disambiguate the noisy matching scores. Existing methods generally tackle this by hand-crafted or CNN-based methods, which either lack robustness to severe deformations or inherit the limitation of CNNs that fail to discriminate incorrect matches due to limited receptive fields and inadaptability. In this paper, we introduce Cost Aggregation with Transformers (CATs) to tackle this by exploring global consensus among initial correlation map with the help of some architectural designs that allow us to fully enjoy global receptive fields of self-attention mechanism. Also, to alleviate some of the limitations that CATs may face, i.e., high computational costs induced by the use of a standard transformer that its complexity grows with the size of spatial and feature dimensions, which restrict its applicability only at limited resolution and result in rather limited performance, we propose CATs++, an extension of CATs. Our proposed methods outperform the previous state-of-the-art methods by large margins, setting a new state-of-the-art for all the benchmarks, including PF-WILLOW, PF-PASCAL, and SPair-71k. We further provide extensive ablation studies and analyses.
AggMatch: Aggregating Pseudo Labels for Semi-Supervised Learning
Jan 25, 2022



Semi-supervised learning (SSL) has recently proven to be an effective paradigm for leveraging a huge amount of unlabeled data while mitigating the reliance on large labeled data. Conventional methods focused on extracting a pseudo label from individual unlabeled data sample and thus they mostly struggled to handle inaccurate or noisy pseudo labels, which degenerate performance. In this paper, we address this limitation with a novel SSL framework for aggregating pseudo labels, called AggMatch, which refines initial pseudo labels by using different confident instances. Specifically, we introduce an aggregation module for consistency regularization framework that aggregates the initial pseudo labels based on the similarity between the instances. To enlarge the aggregation candidates beyond the mini-batch, we present a class-balanced confidence-aware queue built with the momentum model, encouraging to provide more stable and consistent aggregation. We also propose a novel uncertainty-based confidence measure for the pseudo label by considering the consensus among multiple hypotheses with different subsets of the queue. We conduct experiments to demonstrate the effectiveness of AggMatch over the latest methods on standard benchmarks and provide extensive analyses.