 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSergio Escalera
AI Competitions and Benchmarks: Dataset Development
Apr 15, 2024
Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
in2IN: Leveraging individual Information to Generate Human INteractions
Apr 15, 2024Generating human-human motion interactions conditioned on textual descriptions is a very useful application in many areas such as robotics, gaming, animation, and the metaverse. Alongside this utility also comes a great difficulty in modeling the highly dimensional inter-personal dynamics. In addition, properly capturing the intra-personal diversity of interactions has a lot of challenges. Current methods generate interactions with limited diversity of intra-person dynamics due to the limitations of the available datasets and conditioning strategies. For this, we introduce in2IN, a novel diffusion model for human-human motion generation which is conditioned not only on the textual description of the overall interaction but also on the individual descriptions of the actions performed by each person involved in the interaction. To train this model, we use a large language model to extend the InterHuman dataset with individual descriptions. As a result, in2IN achieves state-of-the-art performance in the InterHuman dataset. Furthermore, in order to increase the intra-personal diversity on the existing interaction datasets, we propose DualMDM, a model composition technique that combines the motions generated with in2IN and the motions generated by a single-person motion prior pre-trained on HumanML3D. As a result, DualMDM generates motions with higher individual diversity and improves control over the intra-person dynamics while maintaining inter-personal coherence.
T-DEED: Temporal-Discriminability Enhancer Encoder-Decoder for Precise Event Spotting in Sports Videos
Apr 11, 2024In this paper, we introduce T-DEED, a Temporal-Discriminability Enhancer Encoder-Decoder for Precise Event Spotting in sports videos. T-DEED addresses multiple challenges in the task, including the need for discriminability among frame representations, high output temporal resolution to maintain prediction precision, and the necessity to capture information at different temporal scales to handle events with varying dynamics. It tackles these challenges through its specifically designed architecture, featuring an encoder-decoder for leveraging multiple temporal scales and achieving high output temporal resolution, along with temporal modules designed to increase token discriminability. Leveraging these characteristics, T-DEED achieves SOTA performance on the FigureSkating and FineDiving datasets. Code is available at https://github.com/arturxe2/T-DEED.
Unified Physical-Digital Attack Detection Challenge
Apr 09, 2024Face Anti-Spoofing (FAS) is crucial to safeguard Face Recognition (FR) Systems. In real-world scenarios, FRs are confronted with both physical and digital attacks. However, existing algorithms often address only one type of attack at a time, which poses significant limitations in real-world scenarios where FR systems face hybrid physical-digital threats. To facilitate the research of Unified Attack Detection (UAD) algorithms, a large-scale UniAttackData dataset has been collected. UniAttackData is the largest public dataset for Unified Attack Detection, with a total of 28,706 videos, where each unique identity encompasses all advanced attack types. Based on this dataset, we organized a Unified Physical-Digital Face Attack Detection Challenge to boost the research in Unified Attack Detections. It attracted 136 teams for the development phase, with 13 qualifying for the final round. The results re-verified by the organizing team were used for the final ranking. This paper comprehensively reviews the challenge, detailing the dataset introduction, protocol definition, evaluation criteria, and a summary of published results. Finally, we focus on the detailed analysis of the highest-performing algorithms and offer potential directions for unified physical-digital attack detection inspired by this competition. Challenge Website: https://sites.google.com/view/face-anti-spoofing-challenge/welcome/challengecvpr2024.
A noisy elephant in the room: Is your out-of-distribution detector robust to label noise?
Apr 02, 2024The ability to detect unfamiliar or unexpected images is essential for safe deployment of computer vision systems. In the context of classification, the task of detecting images outside of a model's training domain is known as out-of-distribution (OOD) detection. While there has been a growing research interest in developing post-hoc OOD detection methods, there has been comparably little discussion around how these methods perform when the underlying classifier is not trained on a clean, carefully curated dataset. In this work, we take a closer look at 20 state-of-the-art OOD detection methods in the (more realistic) scenario where the labels used to train the underlying classifier are unreliable (e.g. crowd-sourced or web-scraped labels). Extensive experiments across different datasets, noise types & levels, architectures and checkpointing strategies provide insights into the effect of class label noise on OOD detection, and show that poor separation between incorrectly classified ID samples vs. OOD samples is an overlooked yet important limitation of existing methods. Code: https://github.com/glhr/ood-labelnoise
ASTRA: An Action Spotting TRAnsformer for Soccer Videos
Apr 02, 2024In this paper, we introduce ASTRA, a Transformer-based model designed for the task of Action Spotting in soccer matches. ASTRA addresses several challenges inherent in the task and dataset, including the requirement for precise action localization, the presence of a long-tail data distribution, non-visibility in certain actions, and inherent label noise. To do so, ASTRA incorporates (a) a Transformer encoder-decoder architecture to achieve the desired output temporal resolution and to produce precise predictions, (b) a balanced mixup strategy to handle the long-tail distribution of the data, (c) an uncertainty-aware displacement head to capture the label variability, and (d) input audio signal to enhance detection of non-visible actions. Results demonstrate the effectiveness of ASTRA, achieving a tight Average-mAP of 66.82 on the test set. Moreover, in the SoccerNet 2023 Action Spotting challenge, we secure the 3rd position with an Average-mAP of 70.21 on the challenge set.
Your Image is My Video: Reshaping the Receptive Field via Image-To-Video Differentiable AutoAugmentation and Fusion
Mar 22, 2024The landscape of deep learning research is moving towards innovative strategies to harness the true potential of data. Traditionally, emphasis has been on scaling model architectures, resulting in large and complex neural networks, which can be difficult to train with limited computational resources. However, independently of the model size, data quality (i.e. amount and variability) is still a major factor that affects model generalization. In this work, we propose a novel technique to exploit available data through the use of automatic data augmentation for the tasks of image classification and semantic segmentation. We introduce the first Differentiable Augmentation Search method (DAS) to generate variations of images that can be processed as videos. Compared to previous approaches, DAS is extremely fast and flexible, allowing the search on very large search spaces in less than a GPU day. Our intuition is that the increased receptive field in the temporal dimension provided by DAS could lead to benefits also to the spatial receptive field. More specifically, we leverage DAS to guide the reshaping of the spatial receptive field by selecting task-dependant transformations. As a result, compared to standard augmentation alternatives, we improve in terms of accuracy on ImageNet, Cifar10, Cifar100, Tiny-ImageNet, Pascal-VOC-2012 and CityScapes datasets when plugging-in our DAS over different light-weight video backbones.
CFPL-FAS: Class Free Prompt Learning for Generalizable Face Anti-spoofing
Mar 21, 2024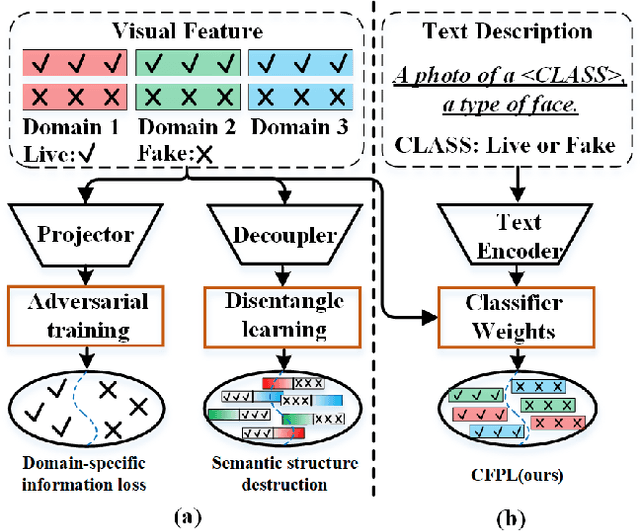
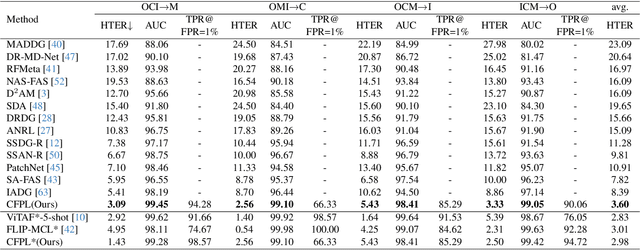
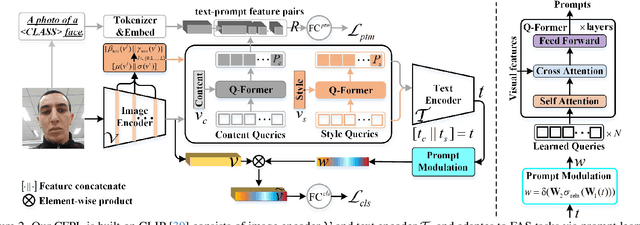
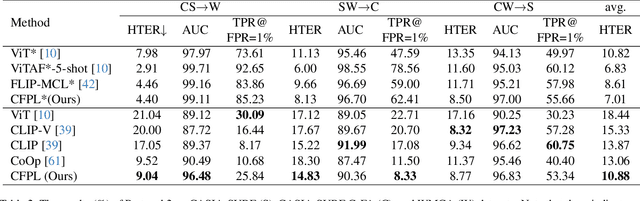
Domain generalization (DG) based Face Anti-Spoofing (FAS) aims to improve the model's performance on unseen domains. Existing methods either rely on domain labels to align domain-invariant feature spaces, or disentangle generalizable features from the whole sample, which inevitably lead to the distortion of semantic feature structures and achieve limited generalization. In this work, we make use of large-scale VLMs like CLIP and leverage the textual feature to dynamically adjust the classifier's weights for exploring generalizable visual features. Specifically, we propose a novel Class Free Prompt Learning (CFPL) paradigm for DG FAS, which utilizes two lightweight transformers, namely Content Q-Former (CQF) and Style Q-Former (SQF), to learn the different semantic prompts conditioned on content and style features by using a set of learnable query vectors, respectively. Thus, the generalizable prompt can be learned by two improvements: (1) A Prompt-Text Matched (PTM) supervision is introduced to ensure CQF learns visual representation that is most informative of the content description. (2) A Diversified Style Prompt (DSP) technology is proposed to diversify the learning of style prompts by mixing feature statistics between instance-specific styles. Finally, the learned text features modulate visual features to generalization through the designed Prompt Modulation (PM). Extensive experiments show that the CFPL is effective and outperforms the state-of-the-art methods on several cross-domain datasets.
Seamless Human Motion Composition with Blended Positional Encodings
Feb 23, 2024Conditional human motion generation is an important topic with many applications in virtual reality, gaming, and robotics. While prior works have focused on generating motion guided by text, music, or scenes, these typically result in isolated motions confined to short durations. Instead, we address the generation of long, continuous sequences guided by a series of varying textual descriptions. In this context, we introduce FlowMDM, the first diffusion-based model that generates seamless Human Motion Compositions (HMC) without any postprocessing or redundant denoising steps. For this, we introduce the Blended Positional Encodings, a technique that leverages both absolute and relative positional encodings in the denoising chain. More specifically, global motion coherence is recovered at the absolute stage, whereas smooth and realistic transitions are built at the relative stage. As a result, we achieve state-of-the-art results in terms of accuracy, realism, and smoothness on the Babel and HumanML3D datasets. FlowMDM excels when trained with only a single description per motion sequence thanks to its Pose-Centric Cross-ATtention, which makes it robust against varying text descriptions at inference time. Finally, to address the limitations of existing HMC metrics, we propose two new metrics: the Peak Jerk and the Area Under the Jerk, to detect abrupt transitions.
A Transformer Model for Boundary Detection in Continuous Sign Language
Feb 22, 2024Sign Language Recognition (SLR) has garnered significant attention from researchers in recent years, particularly the intricate domain of Continuous Sign Language Recognition (CSLR), which presents heightened complexity compared to Isolated Sign Language Recognition (ISLR). One of the prominent challenges in CSLR pertains to accurately detecting the boundaries of isolated signs within a continuous video stream. Additionally, the reliance on handcrafted features in existing models poses a challenge to achieving optimal accuracy. To surmount these challenges, we propose a novel approach utilizing a Transformer-based model. Unlike traditional models, our approach focuses on enhancing accuracy while eliminating the need for handcrafted features. The Transformer model is employed for both ISLR and CSLR. The training process involves using isolated sign videos, where hand keypoint features extracted from the input video are enriched using the Transformer model. Subsequently, these enriched features are forwarded to the final classification layer. The trained model, coupled with a post-processing method, is then applied to detect isolated sign boundaries within continuous sign videos. The evaluation of our model is conducted on two distinct datasets, including both continuous signs and their corresponding isolated signs, demonstrates promising results.