 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShahin Shahrampour
Linear Convergence of Independent Natural Policy Gradient in Games with Entropy Regularization
May 04, 2024
This work focuses on the entropy-regularized independent natural policy gradient (NPG) algorithm in multi-agent reinforcement learning. In this work, agents are assumed to have access to an oracle with exact policy evaluation and seek to maximize their respective independent rewards. Each individual's reward is assumed to depend on the actions of all the agents in the multi-agent system, leading to a game between agents. We assume all agents make decisions under a policy with bounded rationality, which is enforced by the introduction of entropy regularization. In practice, a smaller regularization implies the agents are more rational and behave closer to Nash policies. On the other hand, agents with larger regularization acts more randomly, which ensures more exploration. We show that, under sufficient entropy regularization, the dynamics of this system converge at a linear rate to the quantal response equilibrium (QRE). Although regularization assumptions prevent the QRE from approximating a Nash equilibrium, our findings apply to a wide range of games, including cooperative, potential, and two-player matrix games. We also provide extensive empirical results on multiple games (including Markov games) as a verification of our theoretical analysis.
Regret Analysis of Policy Optimization over Submanifolds for Linearly Constrained Online LQG
Mar 13, 2024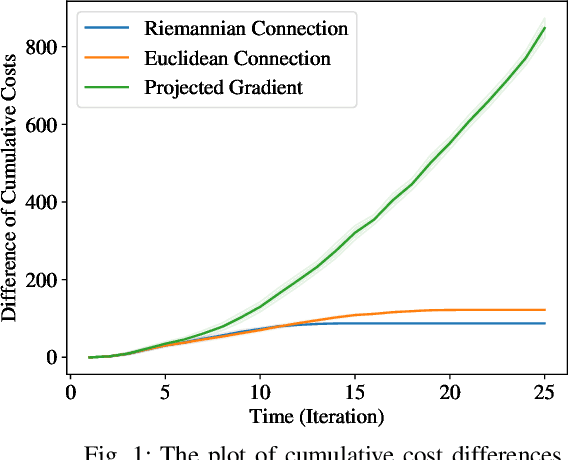
Recent advancement in online optimization and control has provided novel tools to study online linear quadratic regulator (LQR) problems, where cost matrices are varying adversarially over time. However, the controller parameterization of existing works may not satisfy practical conditions like sparsity due to physical connections. In this work, we study online linear quadratic Gaussian problems with a given linear constraint imposed on the controller. Inspired by the recent work of [1] which proposed, for a linearly constrained policy optimization of an offline LQR, a second order method equipped with a Riemannian metric that emerges naturally in the context of optimal control problems, we propose online optimistic Newton on manifold (OONM) which provides an online controller based on the prediction on the first and second order information of the function sequence. To quantify the proposed algorithm, we leverage the notion of regret defined as the sub-optimality of its cumulative cost to that of a (locally) minimizing controller sequence and provide the regret bound in terms of the path-length of the minimizer sequence. Simulation results are also provided to verify the property of OONM.
Tracking Dynamic Gaussian Density with a Theoretically Optimal Sliding Window Approach
Mar 11, 2024Dynamic density estimation is ubiquitous in many applications, including computer vision and signal processing. One popular method to tackle this problem is the "sliding window" kernel density estimator. There exist various implementations of this method that use heuristically defined weight sequences for the observed data. The weight sequence, however, is a key aspect of the estimator affecting the tracking performance significantly. In this work, we study the exact mean integrated squared error (MISE) of "sliding window" Gaussian Kernel Density Estimators for evolving Gaussian densities. We provide a principled guide for choosing the optimal weight sequence by theoretically characterizing the exact MISE, which can be formulated as constrained quadratic programming. We present empirical evidence with synthetic datasets to show that our weighting scheme indeed improves the tracking performance compared to heuristic approaches.
Provably Fast Convergence of Independent Natural Policy Gradient for Markov Potential Games
Oct 27, 2023This work studies an independent natural policy gradient (NPG) algorithm for the multi-agent reinforcement learning problem in Markov potential games. It is shown that, under mild technical assumptions and the introduction of the \textit{suboptimality gap}, the independent NPG method with an oracle providing exact policy evaluation asymptotically reaches an $\epsilon$-Nash Equilibrium (NE) within $\mathcal{O}(1/\epsilon)$ iterations. This improves upon the previous best result of $\mathcal{O}(1/\epsilon^2)$ iterations and is of the same order, $\mathcal{O}(1/\epsilon)$, that is achievable for the single-agent case. Empirical results for a synthetic potential game and a congestion game are presented to verify the theoretical bounds.
Regret Analysis of Distributed Online Control for LTI Systems with Adversarial Disturbances
Oct 04, 2023This paper addresses the distributed online control problem over a network of linear time-invariant (LTI) systems (with possibly unknown dynamics) in the presence of adversarial perturbations. There exists a global network cost that is characterized by a time-varying convex function, which evolves in an adversarial manner and is sequentially and partially observed by local agents. The goal of each agent is to generate a control sequence that can compete with the best centralized control policy in hindsight, which has access to the global cost. This problem is formulated as a regret minimization. For the case of known dynamics, we propose a fully distributed disturbance feedback controller that guarantees a regret bound of $O(\sqrt{T}\log T)$, where $T$ is the time horizon. For the unknown dynamics case, we design a distributed explore-then-commit approach, where in the exploration phase all agents jointly learn the system dynamics, and in the learning phase our proposed control algorithm is applied using each agent system estimate. We establish a regret bound of $O(T^{2/3} \text{poly}(\log T))$ for this setting.
Dynamic Regret Analysis of Safe Distributed Online Optimization for Convex and Non-convex Problems
Feb 23, 2023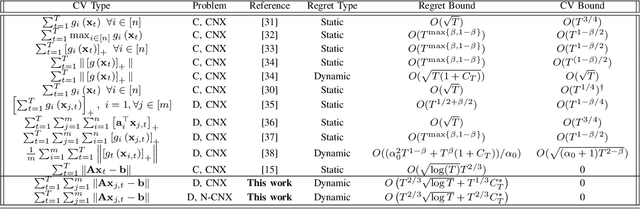
This paper addresses safe distributed online optimization over an unknown set of linear safety constraints. A network of agents aims at jointly minimizing a global, time-varying function, which is only partially observable to each individual agent. Therefore, agents must engage in local communications to generate a safe sequence of actions competitive with the best minimizer sequence in hindsight, and the gap between the two sequences is quantified via dynamic regret. We propose distributed safe online gradient descent (D-Safe-OGD) with an exploration phase, where all agents estimate the constraint parameters collaboratively to build estimated feasible sets, ensuring the action selection safety during the optimization phase. We prove that for convex functions, D-Safe-OGD achieves a dynamic regret bound of $O(T^{2/3} \sqrt{\log T} + T^{1/3}C_T^*)$, where $C_T^*$ denotes the path-length of the best minimizer sequence. We further prove a dynamic regret bound of $O(T^{2/3} \sqrt{\log T} + T^{2/3}C_T^*)$ for certain non-convex problems, which establishes the first dynamic regret bound for a safe distributed algorithm in the non-convex setting.
TAP: The Attention Patch for Cross-Modal Knowledge Transfer from Unlabeled Data
Feb 04, 2023
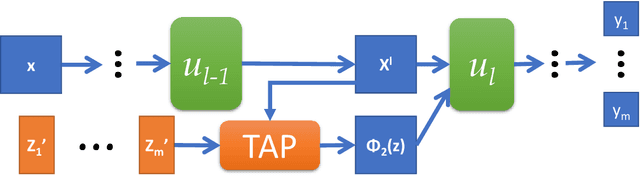
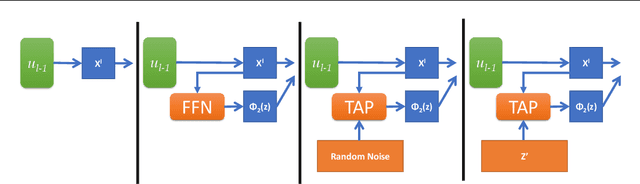

This work investigates the intersection of cross modal learning and semi supervised learning, where we aim to improve the supervised learning performance of the primary modality by borrowing missing information from an unlabeled modality. We investigate this problem from a Nadaraya Watson (NW) kernel regression perspective and show that this formulation implicitly leads to a kernelized cross attention module. To this end, we propose The Attention Patch (TAP), a simple neural network plugin that allows data level knowledge transfer from the unlabeled modality. We provide numerical simulations on three real world datasets to examine each aspect of TAP and show that a TAP integration in a neural network can improve generalization performance using the unlabeled modality.
On the Stability Analysis of Open Federated Learning Systems
Sep 25, 2022

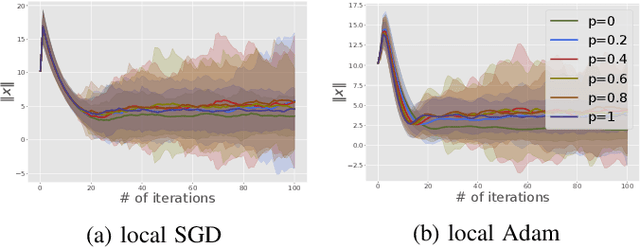
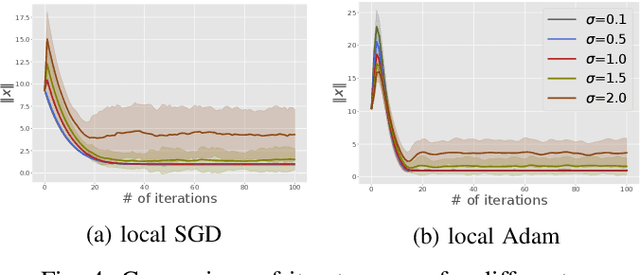
We consider the open federated learning (FL) systems, where clients may join and/or leave the system during the FL process. Given the variability of the number of present clients, convergence to a fixed model cannot be guaranteed in open systems. Instead, we resort to a new performance metric that we term the stability of open FL systems, which quantifies the magnitude of the learned model in open systems. Under the assumption that local clients' functions are strongly convex and smooth, we theoretically quantify the radius of stability for two FL algorithms, namely local SGD and local Adam. We observe that this radius relies on several key parameters, including the function condition number as well as the variance of the stochastic gradient. Our theoretical results are further verified by numerical simulations on both synthetic and real-world benchmark data-sets.
Distributed Online System Identification for LTI Systems Using Reverse Experience Replay
Jul 03, 2022
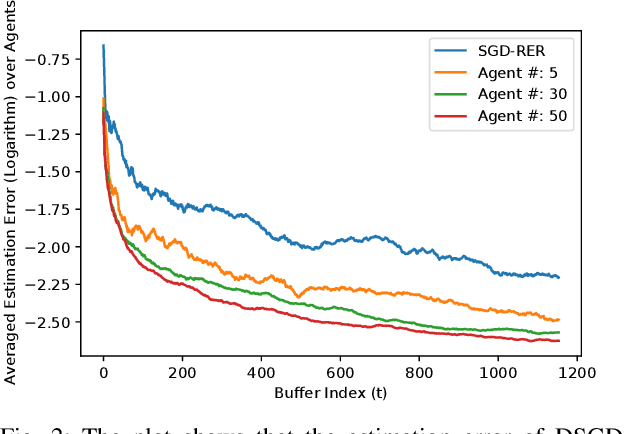

Identification of linear time-invariant (LTI) systems plays an important role in control and reinforcement learning. Both asymptotic and finite-time offline system identification are well-studied in the literature. For online system identification, the idea of stochastic-gradient descent with reverse experience replay (SGD-RER) was recently proposed, where the data sequence is stored in several buffers and the stochastic-gradient descent (SGD) update performs backward in each buffer to break the time dependency between data points. Inspired by this work, we study distributed online system identification of LTI systems over a multi-agent network. We consider agents as identical LTI systems, and the network goal is to jointly estimate the system parameters by leveraging the communication between agents. We propose DSGD-RER, a distributed variant of the SGD-RER algorithm, and theoretically characterize the improvement of the estimation error with respect to the network size. Our numerical experiments certify the reduction of estimation error as the network size grows.
TAKDE: Temporal Adaptive Kernel Density Estimator for Real-Time Dynamic Density Estimation
Mar 15, 2022
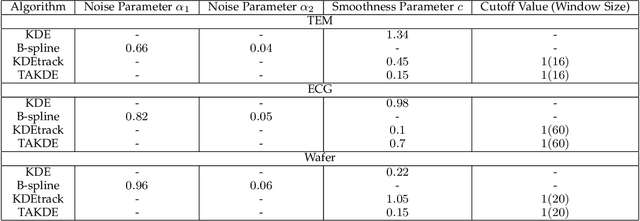
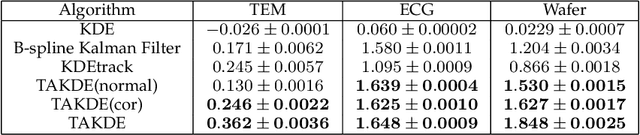
Real-time density estimation is ubiquitous in many applications, including computer vision and signal processing. Kernel density estimation is arguably one of the most commonly used density estimation techniques, and the use of "sliding window" mechanism adapts kernel density estimators to dynamic processes. In this paper, we derive the asymptotic mean integrated squared error (AMISE) upper bound for the "sliding window" kernel density estimator. This upper bound provides a principled guide to devise a novel estimator, which we name the temporal adaptive kernel density estimator (TAKDE). Compared to heuristic approaches for "sliding window" kernel density estimator, TAKDE is theoretically optimal in terms of the worst-case AMISE. We provide numerical experiments using synthetic and real-world datasets, showing that TAKDE outperforms other state-of-the-art dynamic density estimators (including those outside of kernel family). In particular, TAKDE achieves a superior test log-likelihood with a smaller runtime.