 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShan Gao
Comparison of static and dynamic random forests models for EHR data in the presence of competing risks: predicting central line-associated bloodstream infection
Apr 24, 2024
Prognostic outcomes related to hospital admissions typically do not suffer from censoring, and can be modeled either categorically or as time-to-event. Competing events are common but often ignored. We compared the performance of random forest (RF) models to predict the risk of central line-associated bloodstream infections (CLABSI) using different outcome operationalizations. We included data from 27478 admissions to the University Hospitals Leuven, covering 30862 catheter episodes (970 CLABSI, 1466 deaths and 28426 discharges) to build static and dynamic RF models for binary (CLABSI vs no CLABSI), multinomial (CLABSI, discharge, death or no event), survival (time to CLABSI) and competing risks (time to CLABSI, discharge or death) outcomes to predict the 7-day CLABSI risk. We evaluated model performance across 100 train/test splits. Performance of binary, multinomial and competing risks models was similar: AUROC was 0.74 for baseline predictions, rose to 0.78 for predictions at day 5 in the catheter episode, and decreased thereafter. Survival models overestimated the risk of CLABSI (E:O ratios between 1.2 and 1.6), and had AUROCs about 0.01 lower than other models. Binary and multinomial models had lowest computation times. Models including multiple outcome events (multinomial and competing risks) display a different internal structure compared to binary and survival models. In the absence of censoring, complex modelling choices do not considerably improve the predictive performance compared to a binary model for CLABSI prediction in our studied settings. Survival models censoring the competing events at their time of occurrence should be avoided.
Early detection of disease outbreaks and non-outbreaks using incidence data
Apr 13, 2024Forecasting the occurrence and absence of novel disease outbreaks is essential for disease management. Here, we develop a general model, with no real-world training data, that accurately forecasts outbreaks and non-outbreaks. We propose a novel framework, using a feature-based time series classification method to forecast outbreaks and non-outbreaks. We tested our methods on synthetic data from a Susceptible-Infected-Recovered model for slowly changing, noisy disease dynamics. Outbreak sequences give a transcritical bifurcation within a specified future time window, whereas non-outbreak (null bifurcation) sequences do not. We identified incipient differences in time series of infectives leading to future outbreaks and non-outbreaks. These differences are reflected in 22 statistical features and 5 early warning signal indicators. Classifier performance, given by the area under the receiver-operating curve, ranged from 0.99 for large expanding windows of training data to 0.7 for small rolling windows. Real-world performances of classifiers were tested on two empirical datasets, COVID-19 data from Singapore and SARS data from Hong Kong, with two classifiers exhibiting high accuracy. In summary, we showed that there are statistical features that distinguish outbreak and non-outbreak sequences long before outbreaks occur. We could detect these differences in synthetic and real-world data sets, well before potential outbreaks occur.
An early warning indicator trained on stochastic disease-spreading models with different noises
Mar 24, 2024The timely detection of disease outbreaks through reliable early warning signals (EWSs) is indispensable for effective public health mitigation strategies. Nevertheless, the intricate dynamics of real-world disease spread, often influenced by diverse sources of noise and limited data in the early stages of outbreaks, pose a significant challenge in developing reliable EWSs, as the performance of existing indicators varies with extrinsic and intrinsic noises. Here, we address the challenge of modeling disease when the measurements are corrupted by additive white noise, multiplicative environmental noise, and demographic noise into a standard epidemic mathematical model. To navigate the complexities introduced by these noise sources, we employ a deep learning algorithm that provides EWS in infectious disease outbreak by training on noise-induced disease-spreading models. The indicator's effectiveness is demonstrated through its application to real-world COVID-19 cases in Edmonton and simulated time series derived from diverse disease spread models affected by noise. Notably, the indicator captures an impending transition in a time series of disease outbreaks and outperforms existing indicators. This study contributes to advancing early warning capabilities by addressing the intricate dynamics inherent in real-world disease spread, presenting a promising avenue for enhancing public health preparedness and response efforts.
ShapeMaker: Self-Supervised Joint Shape Canonicalization, Segmentation, Retrieval and Deformation
Nov 18, 2023In this paper, we present ShapeMaker, a unified self-supervised learning framework for joint shape canonicalization, segmentation, retrieval and deformation. Given a partially-observed object in an arbitrary pose, we first canonicalize the object by extracting point-wise affine-invariant features, disentangling inherent structure of the object with its pose and size. These learned features are then leveraged to predict semantically consistent part segmentation and corresponding part centers. Next, our lightweight retrieval module aggregates the features within each part as its retrieval token and compare all the tokens with source shapes from a pre-established database to identify the most geometrically similar shape. Finally, we deform the retrieved shape in the deformation module to tightly fit the input object by harnessing part center guided neural cage deformation. The key insight of ShapeMaker is the simultaneous training of the four highly-associated processes: canonicalization, segmentation, retrieval, and deformation, leveraging cross-task consistency losses for mutual supervision. Extensive experiments on synthetic datasets PartNet, ComplementMe, and real-world dataset Scan2CAD demonstrate that ShapeMaker surpasses competitors by a large margin. Codes will be released soon.
Tracking without Label: Unsupervised Multiple Object Tracking via Contrastive Similarity Learning
Sep 02, 2023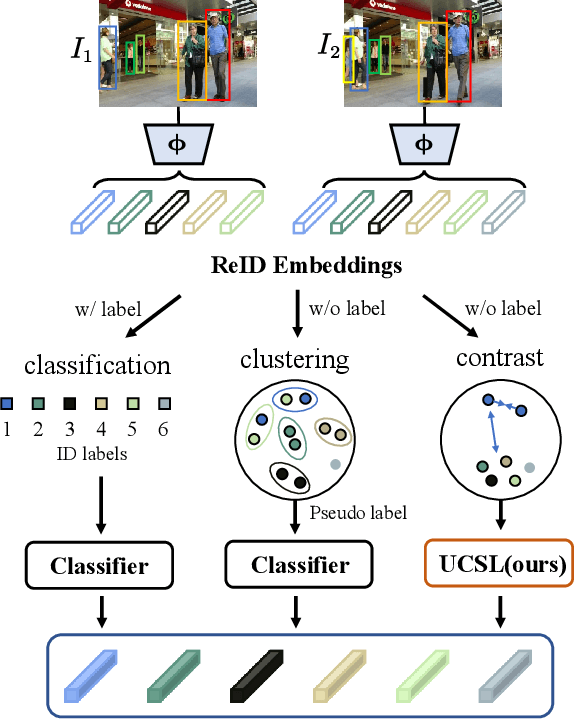
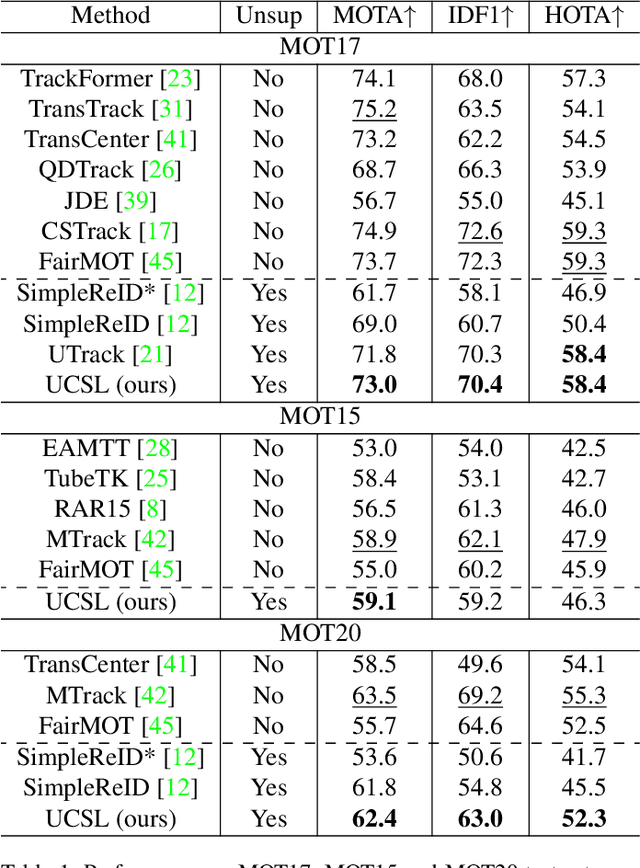
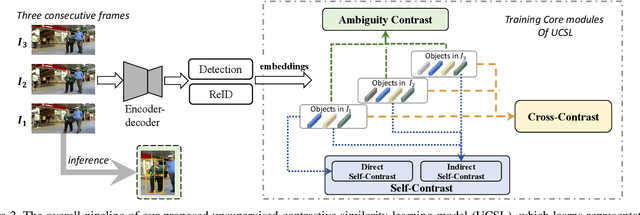

Unsupervised learning is a challenging task due to the lack of labels. Multiple Object Tracking (MOT), which inevitably suffers from mutual object interference, occlusion, etc., is even more difficult without label supervision. In this paper, we explore the latent consistency of sample features across video frames and propose an Unsupervised Contrastive Similarity Learning method, named UCSL, including three contrast modules: self-contrast, cross-contrast, and ambiguity contrast. Specifically, i) self-contrast uses intra-frame direct and inter-frame indirect contrast to obtain discriminative representations by maximizing self-similarity. ii) Cross-contrast aligns cross- and continuous-frame matching results, mitigating the persistent negative effect caused by object occlusion. And iii) ambiguity contrast matches ambiguous objects with each other to further increase the certainty of subsequent object association through an implicit manner. On existing benchmarks, our method outperforms the existing unsupervised methods using only limited help from ReID head, and even provides higher accuracy than lots of fully supervised methods.
Room geometry blind inference based on the localization of real sound source and first order reflections
Jul 22, 2022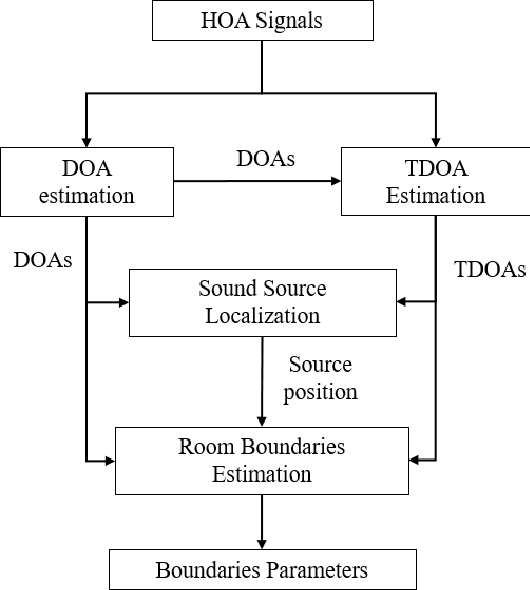
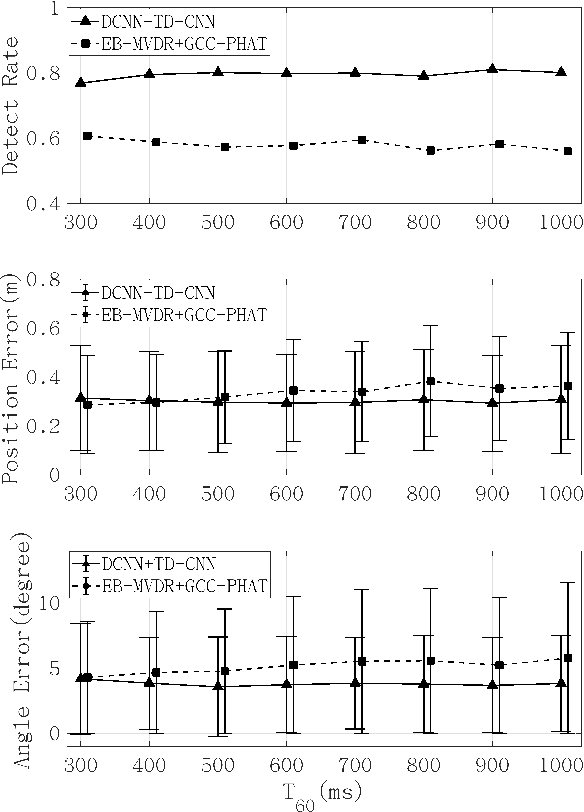

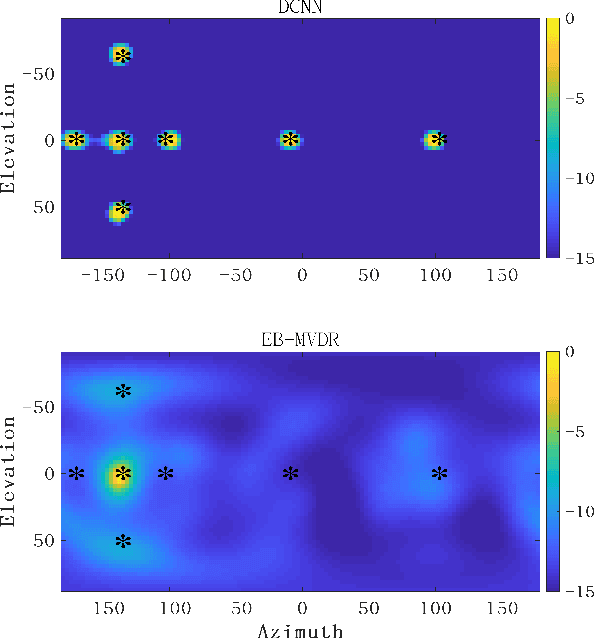
The conventional room geometry blind inference techniques with acoustic signals are conducted based on the prior knowledge of the environment, such as the room impulse response (RIR) or the sound source position, which will limit its application under unknown scenarios. To solve this problem, we have proposed a room geometry reconstruction method in this paper by using the geometric relation between the direct signal and first-order reflections. In addition to the information of the compact microphone array itself, this method does not need any precognition of the environmental parameters. Besides, the learning-based DNN models are designed and used to improve the accuracy and integrity of the localization results of the direct source and first-order reflections. The direction of arrival (DOA) and time difference of arrival (TDOA) information of the direct and reflected signals are firstly estimated using the proposed DCNN and TD-CNN models, which have higher sensitivity and accuracy than the conventional methods. Then the position of the sound source is inferred by integrating the DOA, TDOA and array height using the proposed DNN model. After that, the positions of image sources and corresponding boundaries are derived based on the geometric relation. Experimental results of both simulations and real measurements verify the effectiveness and accuracy of the proposed techniques compared with the conventional methods under different reverberant environments.
Left Ventricle Contouring of Apical Three-Chamber Views on 2D Echocardiography
Jul 13, 2022

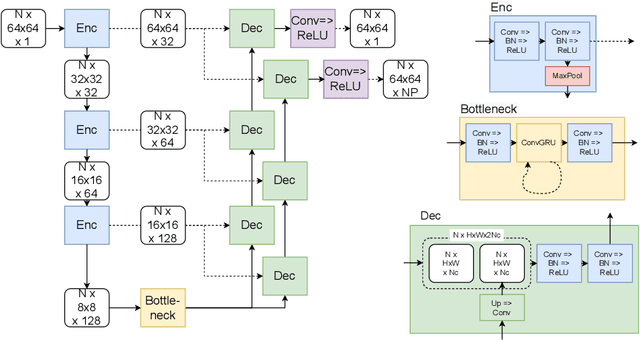
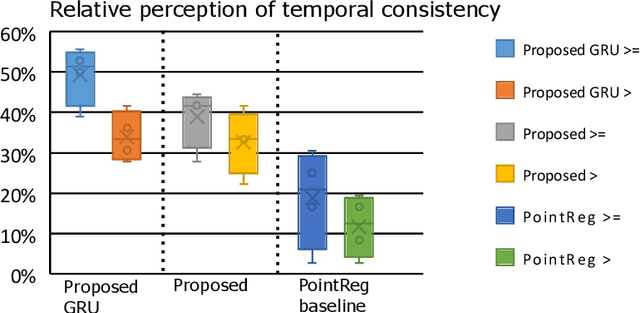
We propose a new method to automatically contour the left ventricle on 2D echocardiographic images. Unlike most existing segmentation methods, which are based on predicting segmentation masks, we focus at predicting the endocardial contour and the key landmark points within this contour (basal points and apex). This provides a representation that is closer to how experts perform manual annotations and hence produce results that are physiologically more plausible. Our proposed method uses a two-headed network based on the U-Net architecture. One head predicts the 7 contour points, and the other head predicts a distance map to the contour. This approach was compared to the U-Net and to a point based approach, achieving performance gains of up to 30\% in terms of landmark localisation (<4.5mm) and distance to the ground truth contour (<3.5mm).
Direct source and early reflections localization using deep deconvolution network under reverberant environment
Oct 22, 2021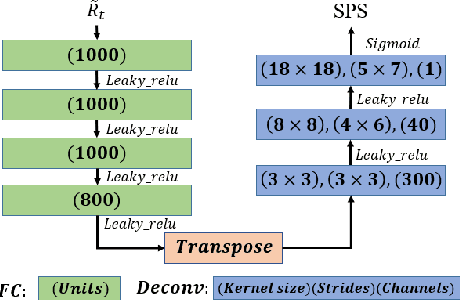
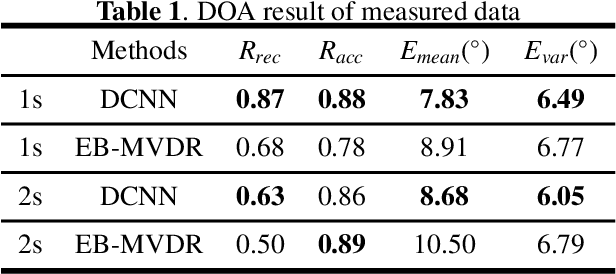
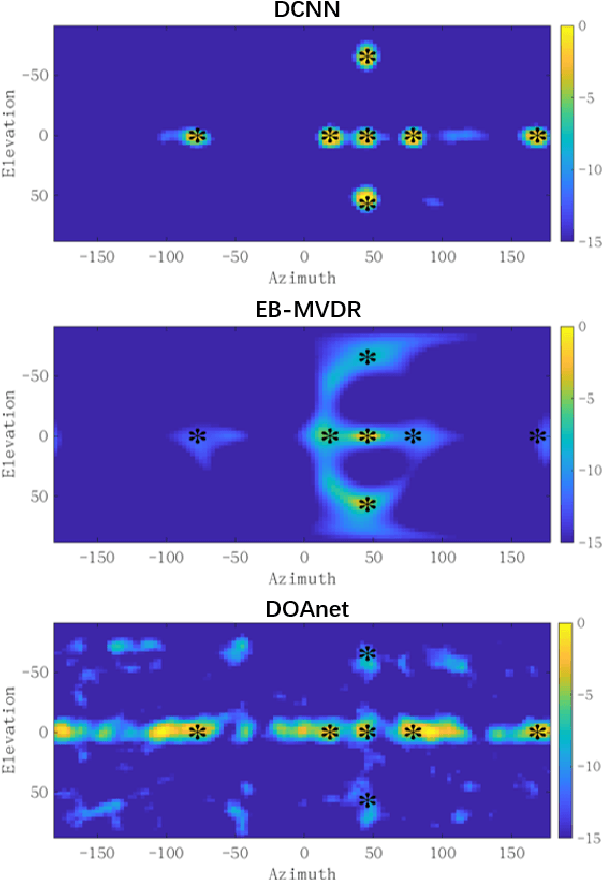
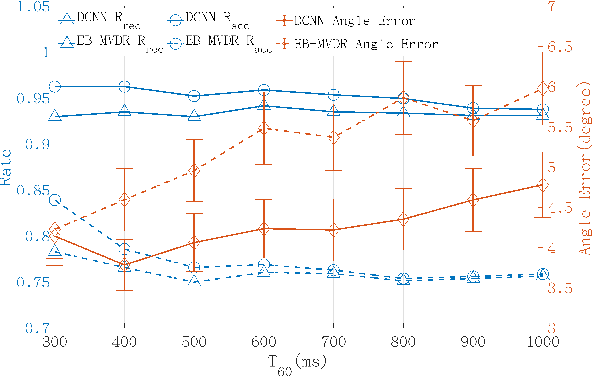
This paper proposes a deconvolution-based network (DCNN) model for DOA estimation of direct source and early reflections under reverberant scenarios. Considering that the first-order reflections of the sound source also contain spatial directivity like the direct source, we treat both of them as the sources in the learning process. We use the covariance matrix of high order Ambisonics (HOA) signals in the time domain as the input feature of the network, which is concise while containing precise spatial information under reverberant scenarios. Besides, we use the deconvolution-based network for the spatial pseudo-spectrum (SPS) reconstruction in the 2D polar space, based on which the spatial relationship between elevation and azimuth can be depicted. We have carried out a series of experiments based on simulated and measured data under different reverberant scenarios, which prove the robustness and accuracy of the proposed DCNN model.
Contrastive Learning for View Classification of Echocardiograms
Aug 06, 2021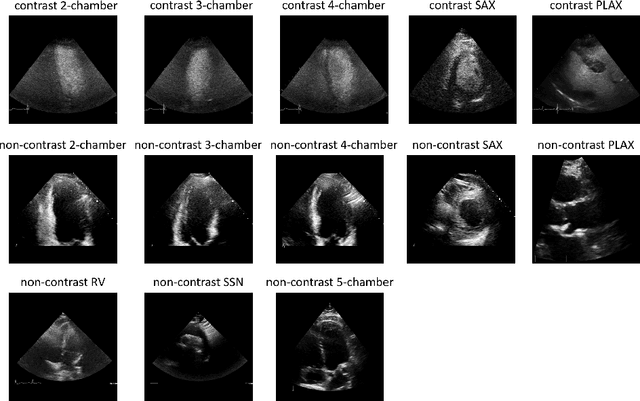
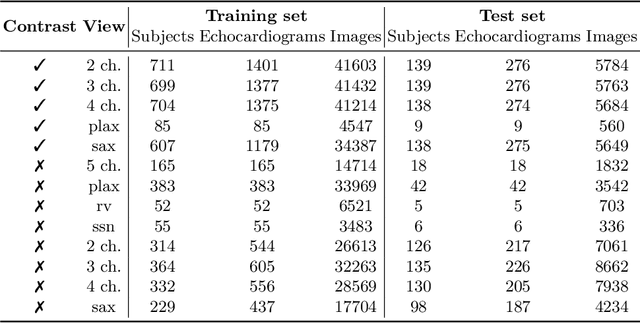
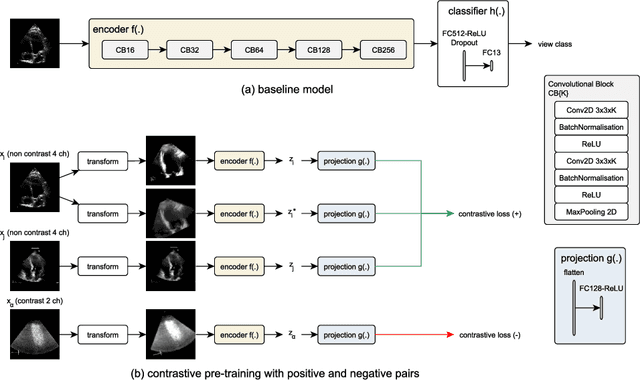

Analysis of cardiac ultrasound images is commonly performed in routine clinical practice for quantification of cardiac function. Its increasing automation frequently employs deep learning networks that are trained to predict disease or detect image features. However, such models are extremely data-hungry and training requires labelling of many thousands of images by experienced clinicians. Here we propose the use of contrastive learning to mitigate the labelling bottleneck. We train view classification models for imbalanced cardiac ultrasound datasets and show improved performance for views/classes for which minimal labelled data is available. Compared to a naive baseline model, we achieve an improvement in F1 score of up to 26% in those views while maintaining state-of-the-art performance for the views with sufficiently many labelled training observations.
A Graphical Social Topology Model for Multi-Object Tracking
Sep 29, 2017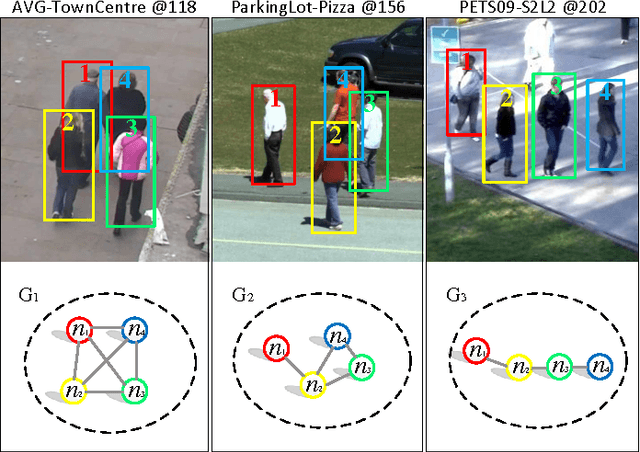

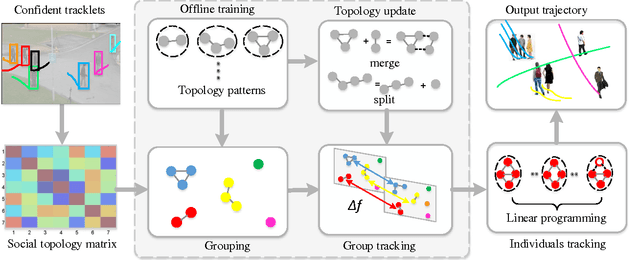
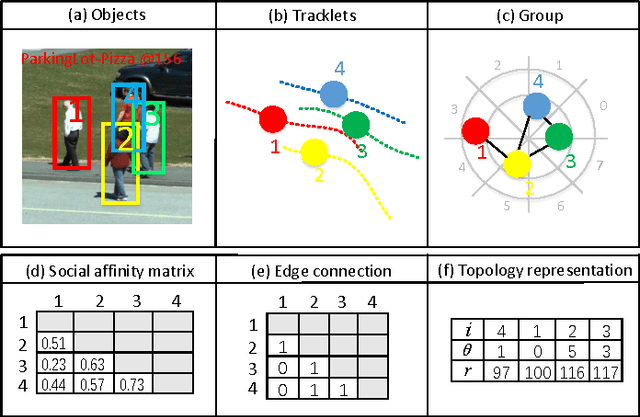
Tracking multiple objects is a challenging task when objects move in groups and occlude each other. Existing methods have investigated the problems of group division and group energy-minimization; however, lacking overall object-group topology modeling limits their ability in handling complex object and group dynamics. Inspired with the social affinity property of moving objects, we propose a Graphical Social Topology (GST) model, which estimates the group dynamics by jointly modeling the group structure and the states of objects using a topological representation. With such topology representation, moving objects are not only assigned to groups, but also dynamically connected with each other, which enables in-group individuals to be correctly associated and the cohesion of each group to be precisely modeled. Using well-designed topology learning modules and topology training, we infer the birth/death and merging/splitting of dynamic groups. With the GST model, the proposed multi-object tracker can naturally facilitate the occlusion problem by treating the occluded object and other in-group members as a whole while leveraging overall state transition. Experiments on both RGB and RGB-D datasets confirm that the proposed multi-object tracker improves the state-of-the-arts especially in crowded scenes.