 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaohua Wang
When Less is Enough: Positive and Unlabeled Learning Model for Vulnerability Detection
Aug 21, 2023
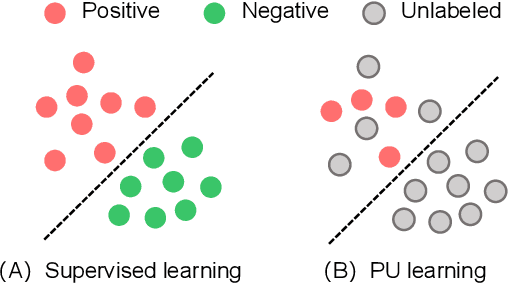
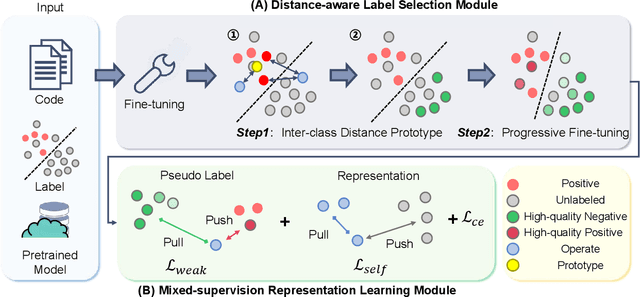

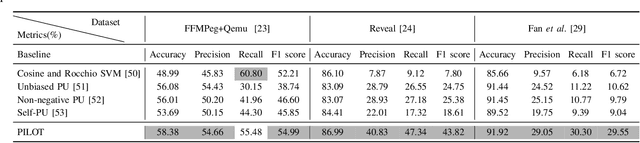
Automated code vulnerability detection has gained increasing attention in recent years. The deep learning (DL)-based methods, which implicitly learn vulnerable code patterns, have proven effective in vulnerability detection. The performance of DL-based methods usually relies on the quantity and quality of labeled data. However, the current labeled data are generally automatically collected, such as crawled from human-generated commits, making it hard to ensure the quality of the labels. Prior studies have demonstrated that the non-vulnerable code (i.e., negative labels) tends to be unreliable in commonly-used datasets, while vulnerable code (i.e., positive labels) is more determined. Considering the large numbers of unlabeled data in practice, it is necessary and worth exploring to leverage the positive data and large numbers of unlabeled data for more accurate vulnerability detection. In this paper, we focus on the Positive and Unlabeled (PU) learning problem for vulnerability detection and propose a novel model named PILOT, i.e., PositIve and unlabeled Learning mOdel for vulnerability deTection. PILOT only learns from positive and unlabeled data for vulnerability detection. It mainly contains two modules: (1) A distance-aware label selection module, aiming at generating pseudo-labels for selected unlabeled data, which involves the inter-class distance prototype and progressive fine-tuning; (2) A mixed-supervision representation learning module to further alleviate the influence of noise and enhance the discrimination of representations.
Machine vision detection to daily facial fatigue with a nonlocal 3D attention network
Apr 21, 2021



Fatigue detection is valued for people to keep mental health and prevent safety accidents. However, detecting facial fatigue, especially mild fatigue in the real world via machine vision is still a challenging issue due to lack of non-lab dataset and well-defined algorithms. In order to improve the detection capability on facial fatigue that can be used widely in daily life, this paper provided an audiovisual dataset named DLFD (daily-life fatigue dataset) which reflected people's facial fatigue state in the wild. A framework using 3D-ResNet along with non-local attention mechanism was training for extraction of local and long-range features in spatial and temporal dimensions. Then, a compacted loss function combining mean squared error and cross-entropy was designed to predict both continuous and categorical fatigue degrees. Our proposed framework has reached an average accuracy of 90.8% on validation set and 72.5% on test set for binary classification, standing a good position compared to other state-of-the-art methods. The analysis of feature map visualization revealed that our framework captured facial dynamics and attempted to build a connection with fatigue state. Our experimental results in multiple metrics proved that our framework captured some typical, micro and dynamic facial features along spatiotemporal dimensions, contributing to the mild fatigue detection in the wild.
Zero Cost Improvements for General Object Detection Network
Nov 16, 2020


Modern object detection networks pursuit higher precision on general object detection datasets, at the same time the computation burden is also increasing along with the improvement of precision. Nevertheless, the inference time and precision are both critical to object detection system which needs to be real-time. It is necessary to research precision improvement without extra computation cost. In this work, two modules are proposed to improve detection precision with zero cost, which are focus on FPN and detection head improvement for general object detection networks. We employ the scale attention mechanism to efficiently fuse multi-level feature maps with less parameters, which is called SA-FPN module. Considering the correlation of classification head and regression head, we use sequential head to take the place of widely-used parallel head, which is called Seq-HEAD module. To evaluate the effectiveness, we apply the two modules to some modern state-of-art object detection networks, including anchor-based and anchor-free. Experiment results on coco dataset show that the networks with the two modules can surpass original networks by 1.1 AP and 0.8 AP with zero cost for anchor-based and anchor-free networks, respectively. Code will be available at https://git.io/JTFGl.
A context-based geoprocessing framework for optimizing meetup location of multiple moving objects along road networks
Dec 10, 2018

Given different types of constraints on human life, people must make decisions that satisfy social activity needs. Minimizing costs (i.e., distance, time, or money) associated with travel plays an important role in perceived and realized social quality of life. Identifying optimal interaction locations on road networks when there are multiple moving objects (MMO) with space-time constraints remains a challenge. In this research, we formalize the problem of finding dynamic ideal interaction locations for MMO as a spatial optimization model and introduce a context-based geoprocessing heuristic framework to address this problem. As a proof of concept, a case study involving identification of a meetup location for multiple people under traffic conditions is used to validate the proposed geoprocessing framework. Five heuristic methods with regard to efficient shortest-path search space have been tested. We find that the R* tree-based algorithm performs the best with high quality solutions and low computation time. This framework is implemented in a GIS environment to facilitate integration with external geographic contextual information, e.g., temporary road barriers, points of interest (POI), and real-time traffic information, when dynamically searching for ideal meetup sites. The proposed method can be applied in trip planning, carpooling services, collaborative interaction, and logistics management.
* 34 pages, 8 figures