 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaowei Wang
Instant square lattice structured illumination microscopy: an optimal strategy towards photon-saving and real-time super-resolution observation
Feb 05, 2024
Over the past decade, structured illumination microscopy (SIM) has found its niche in super-resolution (SR) microscopy due to its fast imaging speed and low excitation intensity. However, due to the significantly higher light dose compared to wide-field microscopy and the time-consuming post-processing procedures, long-term, real-time, super-resolution observation of living cells is still out of reach for most SIM setups, which inevitably limits its routine use by cell biologists. Here, we describe square lattice SIM (SL-SIM) for long-duration live cell imaging by using the square lattice optical field as illumination, which allows continuous super-resolved observation over long periods of time. In addition, by extending the previous joint spatial-frequency reconstruction concept to SL-SIM, a high-speed reconstruction strategy is validated in the GPU environment, whose reconstruction time is even shorter than image acquisition time, thus enabling real-time observation. We have demonstrated the potential of SL-SIM on various biological applications, ranging from microtubule cytoskeleton dynamics to the interactions of mitochondrial cristae and DNAs in COS7 cells. The inherent lower light dose and user-friendly workflow of the SL-SIM could help make long-duration, real-time and super-resolved observations accessible to biological laboratories.
ZS4C: Zero-Shot Synthesis of Compilable Code for Incomplete Code Snippets using ChatGPT
Jan 25, 2024Technical question and answering (Q&A) sites such as Stack Overflow have become an important source for software developers to seek knowledge. However, code snippets on Q&A sites are usually uncompilable and semantically incomplete for compilation due to unresolved types and missing dependent libraries, which raises the obstacle for users to reuse or analyze Q&A code snippets. Prior approaches either are not designed for synthesizing compilable code or suffer from a low compilation success rate. To address this problem, we propose ZS4C, a lightweight approach to perform zero-shot synthesis of compilable code from incomplete code snippets using Large Language Model (LLM). ZS4C operates in two stages. In the first stage, ZS4C utilizes an LLM, i.e., ChatGPT, to identify missing import statements for a given code snippet, leveraging our designed task-specific prompt template. In the second stage, ZS4C fixes compilation errors caused by incorrect import statements and syntax errors through collaborative work between ChatGPT and a compiler. We thoroughly evaluated ZS4C on a widely used benchmark called StatType-SO against the SOTA approach SnR. Compared with SnR, ZS4C improves the compilation rate from 63% to 87.6%, with a 39.3% improvement. On average, ZS4C can infer more accurate import statements than SnR, with an improvement of 6.6% in the F1.
A First Look at Information Highlighting in Stack Overflow Answers
Jan 03, 2024Context: Navigating the knowledge of Stack Overflow (SO) remains challenging. To make the posts vivid to users, SO allows users to write and edit posts with Markdown or HTML so that users can leverage various formatting styles (e.g., bold, italic, and code) to highlight the important information. Nonetheless, there have been limited studies on the highlighted information. Objective: We carried out the first large-scale exploratory study on the information highlighted in SO answers in our recent study. To extend our previous study, we develop approaches to automatically recommend highlighted content with formatting styles using neural network architectures initially designed for the Named Entity Recognition task. Method: In this paper, we studied 31,169,429 answers of Stack Overflow. For training recommendation models, we choose CNN and BERT models for each type of formatting (i.e., Bold, Italic, Code, and Heading) using the information highlighting dataset we collected from SO answers. Results: Our models based on CNN architecture achieve precision ranging from 0.71 to 0.82. The trained model for automatic code content highlighting achieves a recall of 0.73 and an F1 score of 0.71, outperforming the trained models for other formatting styles. The BERT models have even lower recalls and F1 scores than the CNN models. Our analysis of failure cases indicates that the majority of the failure cases are missing identification (i.e., the model misses the content that is supposed to be highlighted) due to the models tend to learn the frequently highlighted words while struggling to learn less frequent words. Conclusion: Our findings suggest that it is possible to develop recommendation models for highlighting information for answers with different formatting styles on Stack Overflow.
The Impact of Using Regression Models to Build Defect Classifiers
Feb 12, 2022
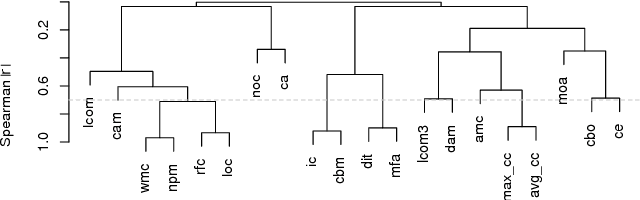
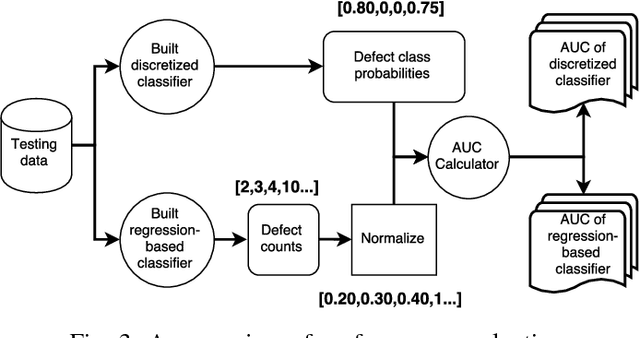
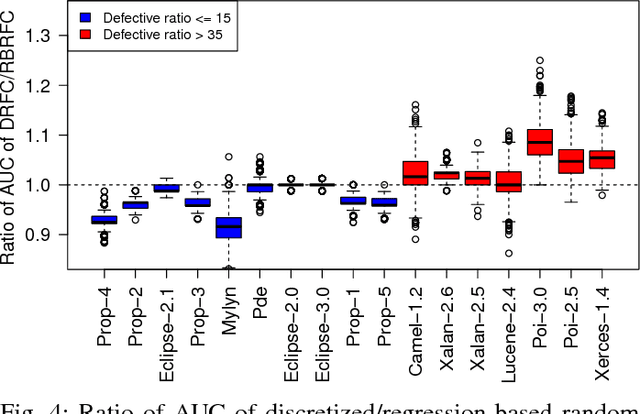
It is common practice to discretize continuous defect counts into defective and non-defective classes and use them as a target variable when building defect classifiers (discretized classifiers). However, this discretization of continuous defect counts leads to information loss that might affect the performance and interpretation of defect classifiers. Another possible approach to build defect classifiers is through the use of regression models then discretizing the predicted defect counts into defective and non-defective classes (regression-based classifiers). In this paper, we compare the performance and interpretation of defect classifiers that are built using both approaches (i.e., discretized classifiers and regression-based classifiers) across six commonly used machine learning classifiers (i.e., linear/logistic regression, random forest, KNN, SVM, CART, and neural networks) and 17 datasets. We find that: i) Random forest based classifiers outperform other classifiers (best AUC) for both classifier building approaches; ii) In contrast to common practice, building a defect classifier using discretized defect counts (i.e., discretized classifiers) does not always lead to better performance. Hence we suggest that future defect classification studies should consider building regression-based classifiers (in particular when the defective ratio of the modeled dataset is low). Moreover, we suggest that both approaches for building defect classifiers should be explored, so the best-performing classifier can be used when determining the most influential features.
Impact of Discretization Noise of the Dependent variable on Machine Learning Classifiers in Software Engineering
Feb 12, 2022
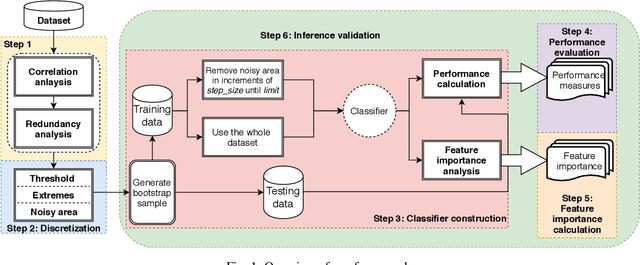
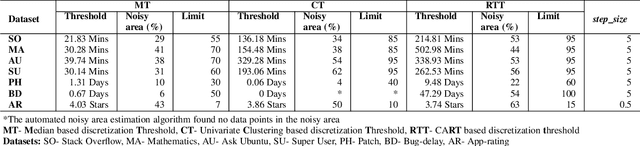
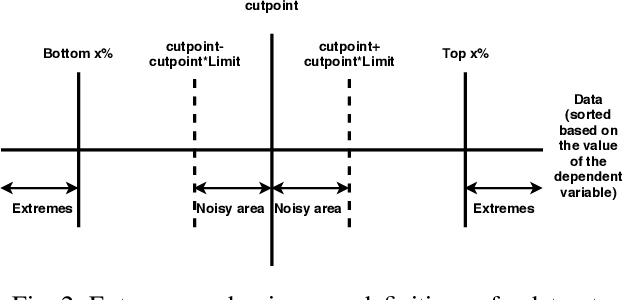
Researchers usually discretize a continuous dependent variable into two target classes by introducing an artificial discretization threshold (e.g., median). However, such discretization may introduce noise (i.e., discretization noise) due to ambiguous class loyalty of data points that are close to the artificial threshold. Previous studies do not provide a clear directive on the impact of discretization noise on the classifiers and how to handle such noise. In this paper, we propose a framework to help researchers and practitioners systematically estimate the impact of discretization noise on classifiers in terms of its impact on various performance measures and the interpretation of classifiers. Through a case study of 7 software engineering datasets, we find that: 1) discretization noise affects the different performance measures of a classifier differently for different datasets; 2) Though the interpretation of the classifiers are impacted by the discretization noise on the whole, the top 3 most important features are not affected by the discretization noise. Therefore, we suggest that practitioners and researchers use our framework to understand the impact of discretization noise on the performance of their built classifiers and estimate the exact amount of discretization noise to be discarded from the dataset to avoid the negative impact of such noise.
The impact of feature importance methods on the interpretation of defect classifiers
Feb 04, 2022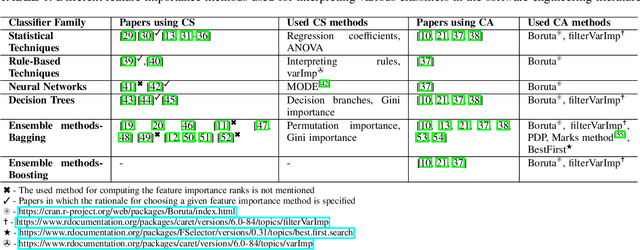
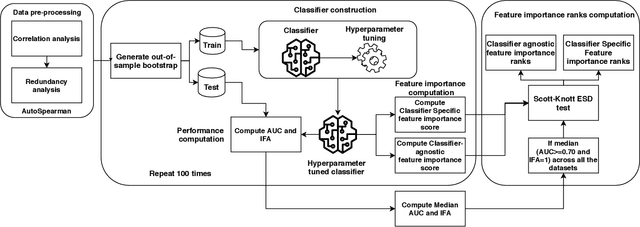
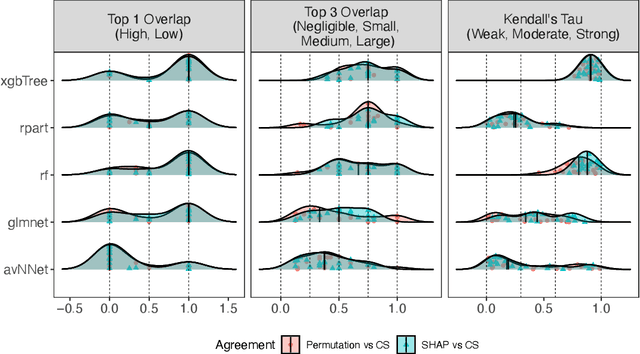
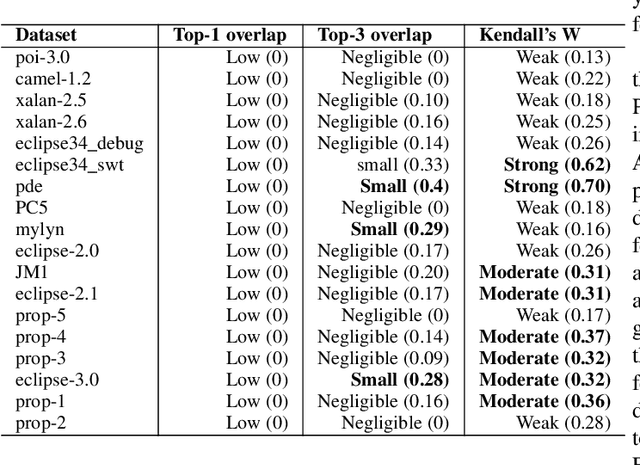
Classifier specific (CS) and classifier agnostic (CA) feature importance methods are widely used (often interchangeably) by prior studies to derive feature importance ranks from a defect classifier. However, different feature importance methods are likely to compute different feature importance ranks even for the same dataset and classifier. Hence such interchangeable use of feature importance methods can lead to conclusion instabilities unless there is a strong agreement among different methods. Therefore, in this paper, we evaluate the agreement between the feature importance ranks associated with the studied classifiers through a case study of 18 software projects and six commonly used classifiers. We find that: 1) The computed feature importance ranks by CA and CS methods do not always strongly agree with each other. 2) The computed feature importance ranks by the studied CA methods exhibit a strong agreement including the features reported at top-1 and top-3 ranks for a given dataset and classifier, while even the commonly used CS methods yield vastly different feature importance ranks. Such findings raise concerns about the stability of conclusions across replicated studies. We further observe that the commonly used defect datasets are rife with feature interactions and these feature interactions impact the computed feature importance ranks of the CS methods (not the CA methods). We demonstrate that removing these feature interactions, even with simple methods like CFS improves agreement between the computed feature importance ranks of CA and CS methods. In light of our findings, we provide guidelines for stakeholders and practitioners when performing model interpretation and directions for future research, e.g., future research is needed to investigate the impact of advanced feature interaction removal methods on computed feature importance ranks of different CS methods.
Hippocampus-heuristic Character Recognition Network for Zero-shot Learning
Apr 06, 2021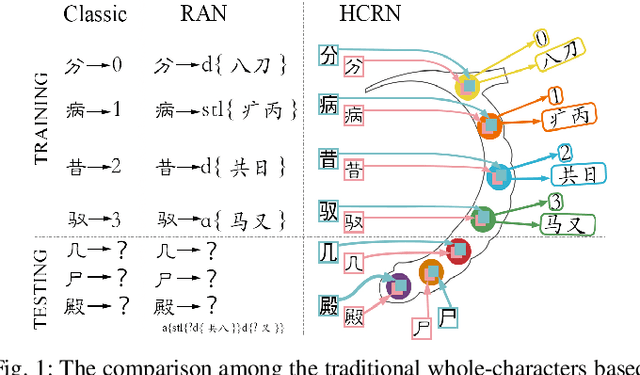
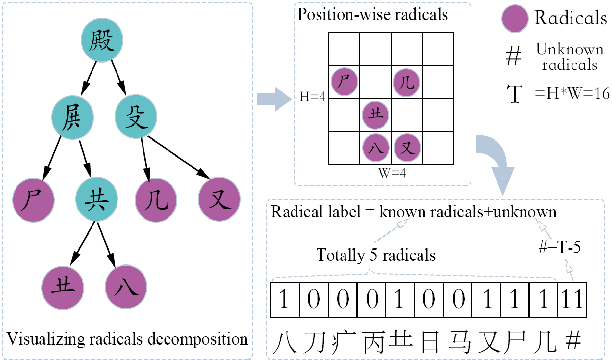
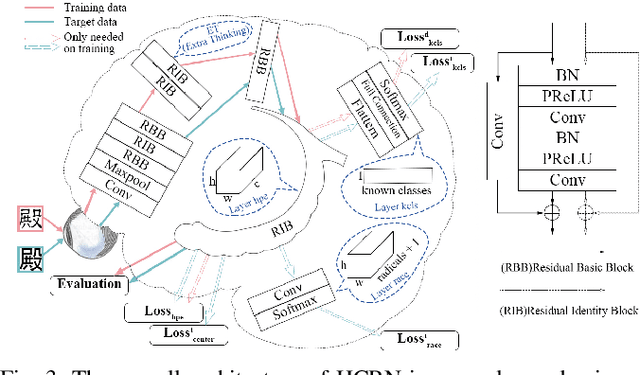
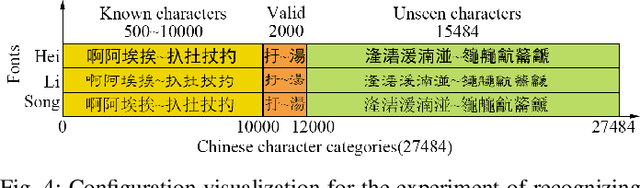
The recognition of Chinese characters has always been a challenging task due to their huge variety and complex structures. The latest research proves that such an enormous character set can be decomposed into a collection of about 500 fundamental Chinese radicals, and based on which this problem can be solved effectively. While with the constant advent of novel Chinese characters, the number of basic radicals is also expanding. The current methods that entirely rely on existing radicals are not flexible for identifying these novel characters and fail to recognize these Chinese characters without learning all of their radicals in the training stage. To this end, this paper proposes a novel Hippocampus-heuristic Character Recognition Network (HCRN), which references the way of hippocampus thinking, and can recognize unseen Chinese characters (namely zero-shot learning) only by training part of radicals. More specifically, the network architecture of HCRN is a new pseudo-siamese network designed by us, which can learn features from pairs of input training character samples and use them to predict unseen Chinese characters. The experimental results show that HCRN is robust and effective. It can accurately predict about 16,330 unseen testing Chinese characters relied on only 500 trained Chinese characters. The recognition accuracy of HCRN outperforms the state-of-the-art Chinese radical recognition approach by 15% (from 85.1% to 99.9%) for recognizing unseen Chinese characters.
RL-CSDia: Representation Learning of Computer Science Diagrams
Mar 10, 2021
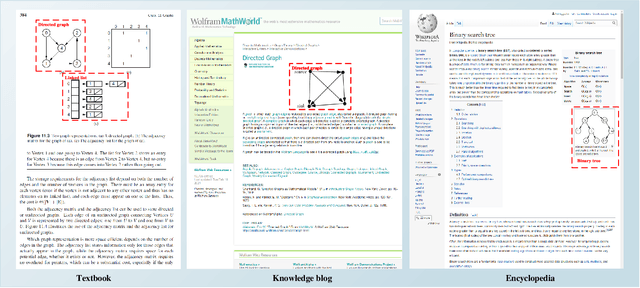
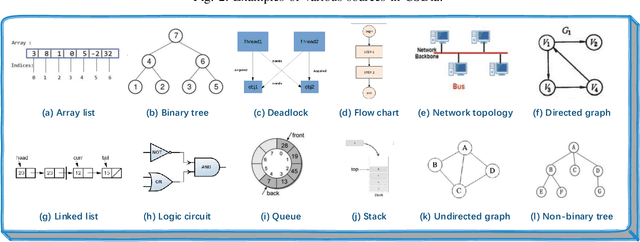
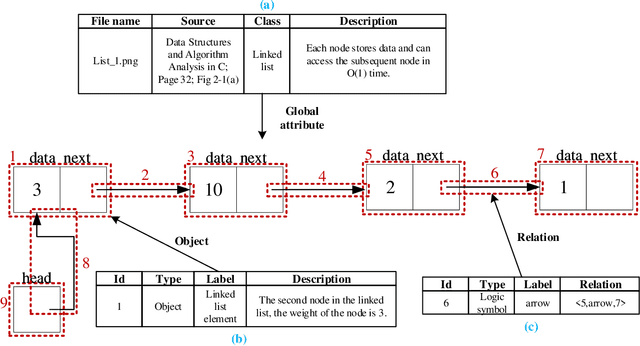
Recent studies on computer vision mainly focus on natural images that express real-world scenes. They achieve outstanding performance on diverse tasks such as visual question answering. Diagram is a special form of visual expression that frequently appears in the education field and is of great significance for learners to understand multimodal knowledge. Current research on diagrams preliminarily focuses on natural disciplines such as Biology and Geography, whose expressions are still similar to natural images. Another type of diagrams such as from Computer Science is composed of graphics containing complex topologies and relations, and research on this type of diagrams is still blank. The main challenges of graphic diagrams understanding are the rarity of data and the confusion of semantics, which are mainly reflected in the diversity of expressions. In this paper, we construct a novel dataset of graphic diagrams named Computer Science Diagrams (CSDia). It contains more than 1,200 diagrams and exhaustive annotations of objects and relations. Considering the visual noises caused by the various expressions in diagrams, we introduce the topology of diagrams to parse topological structure. After that, we propose Diagram Parsing Net (DPN) to represent the diagram from three branches: topology, visual feature, and text, and apply the model to the diagram classification task to evaluate the ability of diagrams understanding. The results show the effectiveness of the proposed DPN on diagrams understanding.
Aggregating Votes with Local Differential Privacy: Usefulness, Soundness vs. Indistinguishability
Aug 14, 2019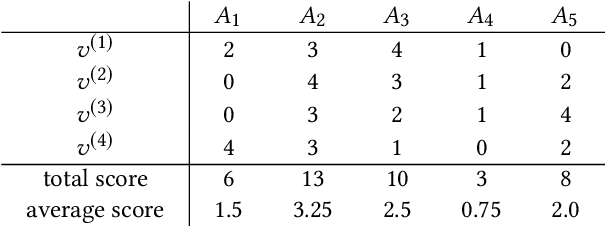
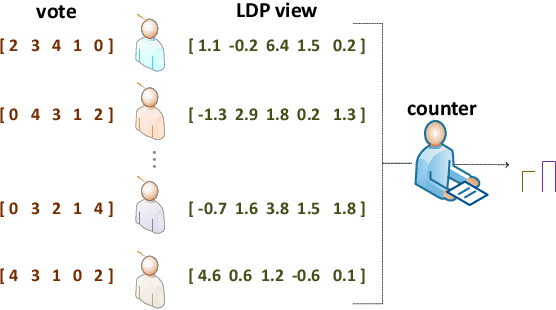
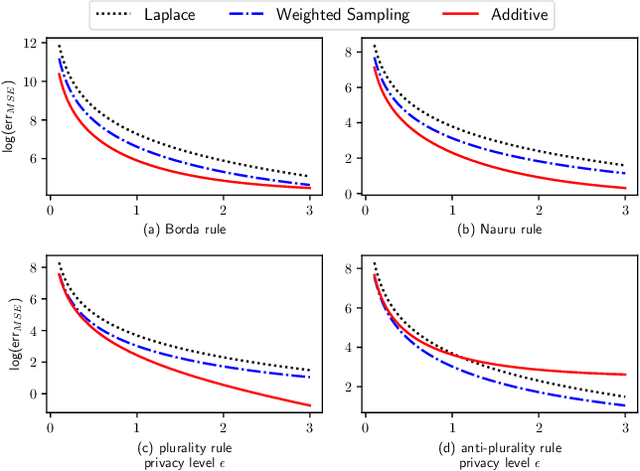
Voting plays a central role in bringing crowd wisdom to collective decision making, meanwhile data privacy has been a common ethical/legal issue in eliciting preferences from individuals. This work studies the problem of aggregating individual's voting data under the local differential privacy setting, where usefulness and soundness of the aggregated scores are of major concern. One naive approach to the problem is adding Laplace random noises, however, it makes aggregated scores extremely fragile to new types of strategic behaviors tailored to the local privacy setting: data amplification attack and view disguise attack. The data amplification attack means an attacker's manipulation power is amplified by the privacy-preserving procedure when contributing a fraud vote. The view disguise attack happens when an attacker could disguise malicious data as valid private views to manipulate the voting result. In this work, after theoretically quantifying the estimation error bound and the manipulating risk bound of the Laplace mechanism, we propose two mechanisms improving the usefulness and soundness simultaneously: the weighted sampling mechanism and the additive mechanism. The former one interprets the score vector as probabilistic data. Compared to the Laplace mechanism for Borda voting rule with $d$ candidates, it reduces the mean squared error bound by half and lowers the maximum magnitude risk bound from $+\infty$ to $O(\frac{d^3}{n\epsilon})$. The latter one randomly outputs a subset of candidates according to their total scores. Its mean squared error bound is optimized from $O(\frac{d^5}{n\epsilon^2})$ to $O(\frac{d^4}{n\epsilon^2})$, and its maximum magnitude risk bound is reduced to $O(\frac{d^2}{n\epsilon})$. Experimental results validate that our proposed approaches averagely reduce estimation error by $50\%$ and are more robust to adversarial attacks.
Personalized Classifier Ensemble Pruning Framework for Mobile Crowdsourcing
Jan 25, 2017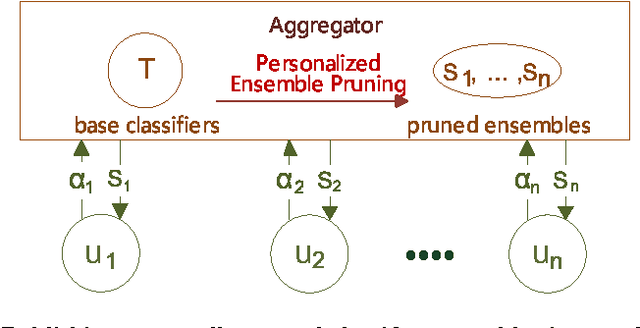
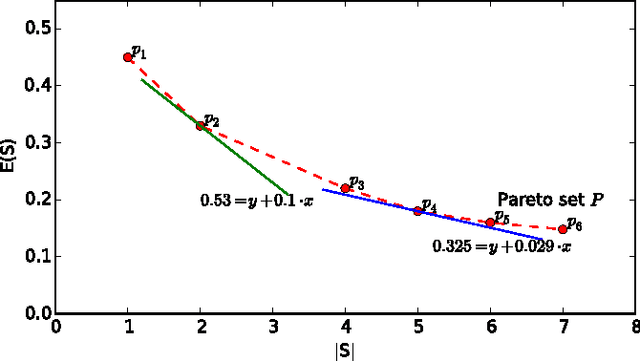
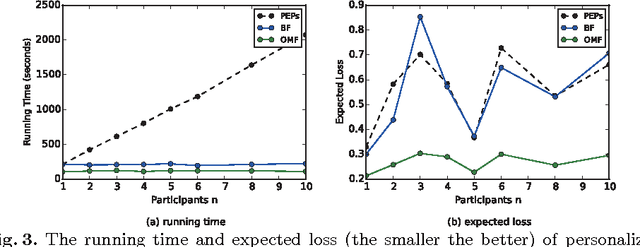
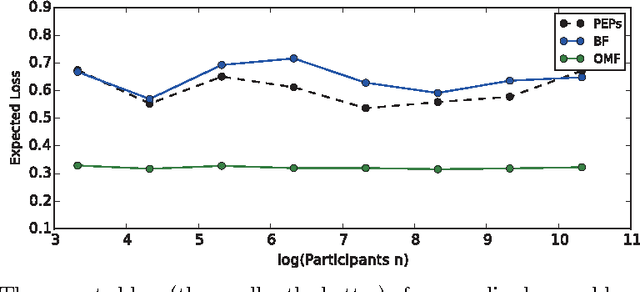
Ensemble learning has been widely employed by mobile applications, ranging from environmental sensing to activity recognitions. One of the fundamental issue in ensemble learning is the trade-off between classification accuracy and computational costs, which is the goal of ensemble pruning. During crowdsourcing, the centralized aggregator releases ensemble learning models to a large number of mobile participants for task evaluation or as the crowdsourcing learning results, while different participants may seek for different levels of the accuracy-cost trade-off. However, most of existing ensemble pruning approaches consider only one identical level of such trade-off. In this study, we present an efficient ensemble pruning framework for personalized accuracy-cost trade-offs via multi-objective optimization. Specifically, for the commonly used linear-combination style of the trade-off, we provide an objective-mixture optimization to further reduce the number of ensemble candidates. Experimental results show that our framework is highly efficient for personalized ensemble pruning, and achieves much better pruning performance with objective-mixture optimization when compared to state-of-art approaches.