 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaozu Yuan
Learning to Generate Poetic Chinese Landscape Painting with Calligraphy
May 08, 2023


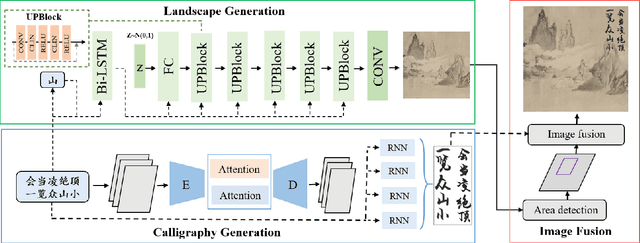
In this paper, we present a novel system (denoted as Polaca) to generate poetic Chinese landscape painting with calligraphy. Unlike previous single image-to-image painting generation, Polaca takes the classic poetry as input and outputs the artistic landscape painting image with the corresponding calligraphy. It is equipped with three different modules to complete the whole piece of landscape painting artwork: the first one is a text-to-image module to generate landscape painting image, the second one is an image-to-image module to generate stylistic calligraphy image, and the third one is an image fusion module to fuse the two images into a whole piece of aesthetic artwork.
SE-GAN: Skeleton Enhanced GAN-based Model for Brush Handwriting Font Generation
Apr 22, 2022



Previous works on font generation mainly focus on the standard print fonts where character's shape is stable and strokes are clearly separated. There is rare research on brush handwriting font generation, which involves holistic structure changes and complex strokes transfer. To address this issue, we propose a novel GAN-based image translation model by integrating the skeleton information. We first extract the skeleton from training images, then design an image encoder and a skeleton encoder to extract corresponding features. A self-attentive refined attention module is devised to guide the model to learn distinctive features between different domains. A skeleton discriminator is involved to first synthesize the skeleton image from the generated image with a pre-trained generator, then to judge its realness to the target one. We also contribute a large-scale brush handwriting font image dataset with six styles and 15,000 high-resolution images. Both quantitative and qualitative experimental results demonstrate the competitiveness of our proposed model.
The JDDC Corpus: A Large-Scale Multi-Turn Chinese Dialogue Dataset for E-commerce Customer Service
Nov 25, 2019



Human conversations in real scenarios are complicated and building a human-like dialogue agent is an extremely challenging task. With the rapid development of deep learning techniques, data-driven models become more and more prevalent which need a huge amount of real conversation data. In this paper, we construct a large-scale real scenario Chinese E-commerce conversation corpus, JDDC, with more than 1 million multi-turn dialogues, 20 million utterances, and 150 million words. The dataset reflects several characteristics of human-human conversations, e.g., goal-driven, and long-term dependency among the context. It also covers various dialogue types including task-oriented, chitchat and question-answering. Extra intent information and three well-annotated challenge sets are also provided. Then, we evaluate several retrieval-based and generative models to provide basic benchmark performance on JDDC corpus. And we hope JDDC can serve as an effective testbed and benefit the development of fundamental research in dialogue task.