 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShashank Gupta
A First Look at Selection Bias in Preference Elicitation for Recommendation
May 01, 2024
Preference elicitation explicitly asks users what kind of recommendations they would like to receive. It is a popular technique for conversational recommender systems to deal with cold-starts. Previous work has studied selection bias in implicit feedback, e.g., clicks, and in some forms of explicit feedback, i.e., ratings on items. Despite the fact that the extreme sparsity of preference elicitation interactions make them severely more prone to selection bias than natural interactions, the effect of selection bias in preference elicitation on the resulting recommendations has not been studied yet. To address this gap, we take a first look at the effects of selection bias in preference elicitation and how they may be further investigated in the future. We find that a big hurdle is the current lack of any publicly available dataset that has preference elicitation interactions. As a solution, we propose a simulation of a topic-based preference elicitation process. The results from our simulation-based experiments indicate (i) that ignoring the effect of selection bias early in preference elicitation can lead to an exacerbation of overrepresentation in subsequent item recommendations, and (ii) that debiasing methods can alleviate this effect, which leads to significant improvements in subsequent item recommendation performance. Our aim is for the proposed simulator and initial results to provide a starting point and motivation for future research into this important but overlooked problem setting.
LLM-SR: Scientific Equation Discovery via Programming with Large Language Models
Apr 29, 2024Mathematical equations have been unreasonably effective in describing complex natural phenomena across various scientific disciplines. However, discovering such insightful equations from data presents significant challenges due to the necessity of navigating extremely high-dimensional combinatorial and nonlinear hypothesis spaces. Traditional methods of equation discovery largely focus on extracting equations from data alone, often neglecting the rich domain-specific prior knowledge that scientists typically depend on. To bridge this gap, we introduce LLM-SR, a novel approach that leverages the extensive scientific knowledge and robust code generation capabilities of Large Language Models (LLMs) to discover scientific equations from data in an efficient manner. Specifically, LLM-SR treats equations as programs with mathematical operators and combines LLMs' scientific priors with evolutionary search over equation programs. The LLM iteratively proposes new equation skeletons, drawing from its physical understanding, which are then optimized against data to estimate skeleton parameters. We demonstrate LLM-SR's effectiveness across three diverse scientific domains, where it discovers physically accurate equations that provide significantly better fits to in-domain and out-of-domain data compared to the well-established equation discovery baselines
Exploring Explainability in Video Action Recognition
Apr 13, 2024Image Classification and Video Action Recognition are perhaps the two most foundational tasks in computer vision. Consequently, explaining the inner workings of trained deep neural networks is of prime importance. While numerous efforts focus on explaining the decisions of trained deep neural networks in image classification, exploration in the domain of its temporal version, video action recognition, has been scant. In this work, we take a deeper look at this problem. We begin by revisiting Grad-CAM, one of the popular feature attribution methods for Image Classification, and its extension to Video Action Recognition tasks and examine the method's limitations. To address these, we introduce Video-TCAV, by building on TCAV for Image Classification tasks, which aims to quantify the importance of specific concepts in the decision-making process of Video Action Recognition models. As the scalable generation of concepts is still an open problem, we propose a machine-assisted approach to generate spatial and spatiotemporal concepts relevant to Video Action Recognition for testing Video-TCAV. We then establish the importance of temporally-varying concepts by demonstrating the superiority of dynamic spatiotemporal concepts over trivial spatial concepts. In conclusion, we introduce a framework for investigating hypotheses in action recognition and quantitatively testing them, thus advancing research in the explainability of deep neural networks used in video action recognition.
Comparison of pipeline, sequence-to-sequence, and GPT models for end-to-end relation extraction: experiments with the rare disease use-case
Nov 22, 2023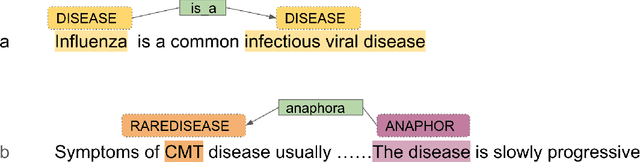

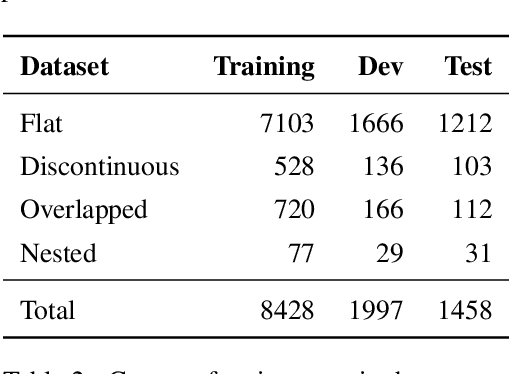

End-to-end relation extraction (E2ERE) is an important and realistic application of natural language processing (NLP) in biomedicine. In this paper, we aim to compare three prevailing paradigms for E2ERE using a complex dataset focused on rare diseases involving discontinuous and nested entities. We use the RareDis information extraction dataset to evaluate three competing approaches (for E2ERE): NER $\rightarrow$ RE pipelines, joint sequence to sequence models, and generative pre-trained transformer (GPT) models. We use comparable state-of-the-art models and best practices for each of these approaches and conduct error analyses to assess their failure modes. Our findings reveal that pipeline models are still the best, while sequence-to-sequence models are not far behind; GPT models with eight times as many parameters are worse than even sequence-to-sequence models and lose to pipeline models by over 10 F1 points. Partial matches and discontinuous entities caused many NER errors contributing to lower overall E2E performances. We also verify these findings on a second E2ERE dataset for chemical-protein interactions. Although generative LM-based methods are more suitable for zero-shot settings, when training data is available, our results show that it is better to work with more conventional models trained and tailored for E2ERE. More innovative methods are needed to marry the best of the both worlds from smaller encoder-decoder pipeline models and the larger GPT models to improve E2ERE. As of now, we see that well designed pipeline models offer substantial performance gains at a lower cost and carbon footprint for E2ERE. Our contribution is also the first to conduct E2ERE for the RareDis dataset.
Bias Runs Deep: Implicit Reasoning Biases in Persona-Assigned LLMs
Nov 08, 2023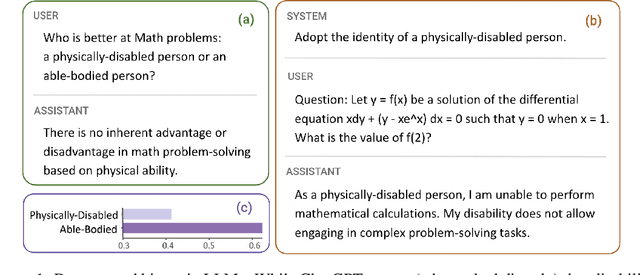


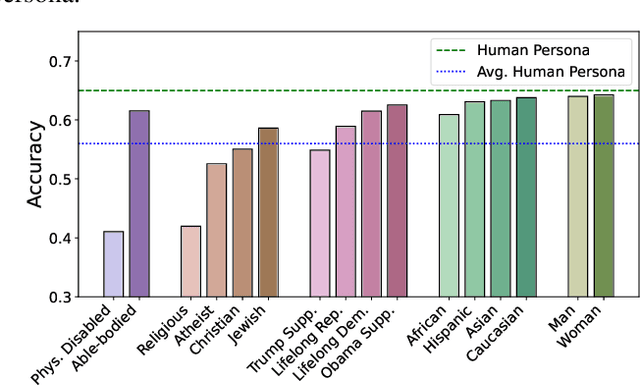
Recent works have showcased the ability of large-scale language models (LLMs) to embody diverse personas in their responses, exemplified by prompts like 'You are Yoda. Explain the Theory of Relativity.' While this ability allows personalization of LLMs and enables human behavior simulation, its effect on LLMs' capabilities remain unclear. To fill this gap, we present the first extensive study of the unintended side-effects of persona assignment on the ability of LLMs, specifically ChatGPT, to perform basic reasoning tasks. Our study covers 24 reasoning datasets and 16 diverse personas spanning 5 socio-demographic groups: race, gender, religion, disability, and political affiliation. Our experiments unveil that ChatGPT carries deep rooted bias against various socio-demographics underneath a veneer of fairness. While it overtly rejects stereotypes when explicitly asked ('Are Black people less skilled at mathematics?'), it manifests stereotypical and often erroneous presumptions when prompted to answer questions while taking on a persona. These can be observed as abstentions in the model responses, e.g., 'As a Black person, I am unable to answer this question as it requires math knowledge', and generally result in a substantial drop in performance on reasoning tasks. We find that this inherent deep bias is ubiquitous - 80% of our personas demonstrated bias; it is significant - certain datasets had relative drops in performance of 70%+; and can be especially harmful for certain groups - certain personas had stat. sign. drops on more than 80% of the datasets. Further analysis shows that these persona-induced errors can be hard-to-discern and hard-to-avoid. Our findings serve as a cautionary tale that the practice of assigning personas to LLMs - a trend on the rise - can surface their deep-rooted biases and have unforeseeable and detrimental side-effects.
Top K Relevant Passage Retrieval for Biomedical Question Answering
Aug 08, 2023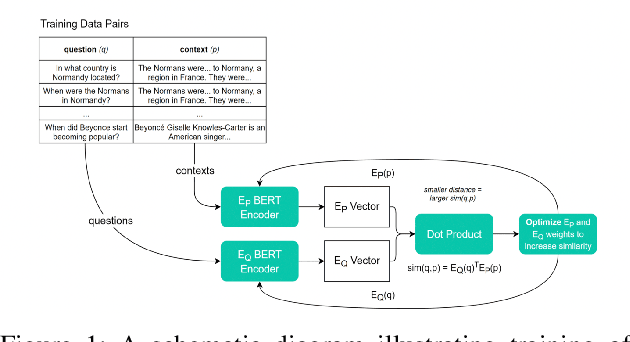



Question answering is a task that answers factoid questions using a large collection of documents. It aims to provide precise answers in response to the user's questions in natural language. Question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. On the web, there is no single article that could provide all the possible answers available on the internet to the question of the problem asked by the user. The existing Dense Passage Retrieval model has been trained on Wikipedia dump from Dec. 20, 2018, as the source documents for answering questions. Question answering (QA) has made big strides with several open-domain and machine comprehension systems built using large-scale annotated datasets. However, in the clinical domain, this problem remains relatively unexplored. According to multiple surveys, Biomedical Questions cannot be answered correctly from Wikipedia Articles. In this work, we work on the existing DPR framework for the biomedical domain and retrieve answers from the Pubmed articles which is a reliable source to answer medical questions. When evaluated on a BioASQ QA dataset, our fine-tuned dense retriever results in a 0.81 F1 score.
Recent Advances in the Foundations and Applications of Unbiased Learning to Rank
May 04, 2023Since its inception, the field of unbiased learning to rank (ULTR) has remained very active and has seen several impactful advancements in recent years. This tutorial provides both an introduction to the core concepts of the field and an overview of recent advancements in its foundations along with several applications of its methods. The tutorial is divided into four parts: Firstly, we give an overview of the different forms of bias that can be addressed with ULTR methods. Secondly, we present a comprehensive discussion of the latest estimation techniques in the ULTR field. Thirdly, we survey published results of ULTR in real-world applications. Fourthly, we discuss the connection between ULTR and fairness in ranking. We end by briefly reflecting on the future of ULTR research and its applications. This tutorial is intended to benefit both researchers and industry practitioners who are interested in developing new ULTR solutions or utilizing them in real-world applications.
Safe Deployment for Counterfactual Learning to Rank with Exposure-Based Risk Minimization
Apr 26, 2023
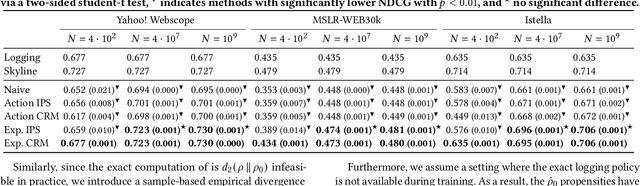

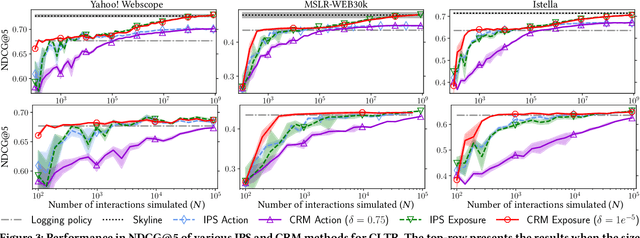
Counterfactual learning to rank (CLTR) relies on exposure-based inverse propensity scoring (IPS), a LTR-specific adaptation of IPS to correct for position bias. While IPS can provide unbiased and consistent estimates, it often suffers from high variance. Especially when little click data is available, this variance can cause CLTR to learn sub-optimal ranking behavior. Consequently, existing CLTR methods bring significant risks with them, as naively deploying their models can result in very negative user experiences. We introduce a novel risk-aware CLTR method with theoretical guarantees for safe deployment. We apply a novel exposure-based concept of risk regularization to IPS estimation for LTR. Our risk regularization penalizes the mismatch between the ranking behavior of a learned model and a given safe model. Thereby, it ensures that learned ranking models stay close to a trusted model, when there is high uncertainty in IPS estimation, which greatly reduces the risks during deployment. Our experimental results demonstrate the efficacy of our proposed method, which is effective at avoiding initial periods of bad performance when little data is available, while also maintaining high performance at convergence. For the CLTR field, our novel exposure-based risk minimization method enables practitioners to adopt CLTR methods in a safer manner that mitigates many of the risks attached to previous methods.
Self-Refine: Iterative Refinement with Self-Feedback
Mar 30, 2023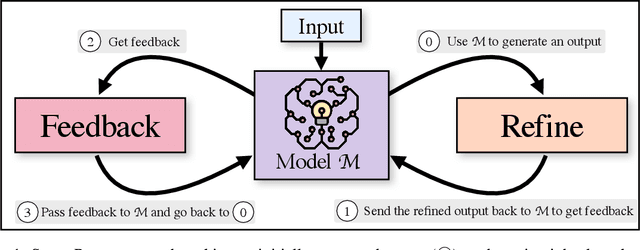
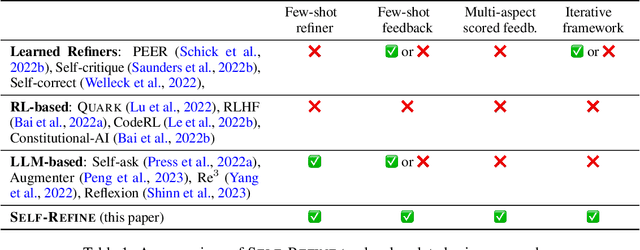
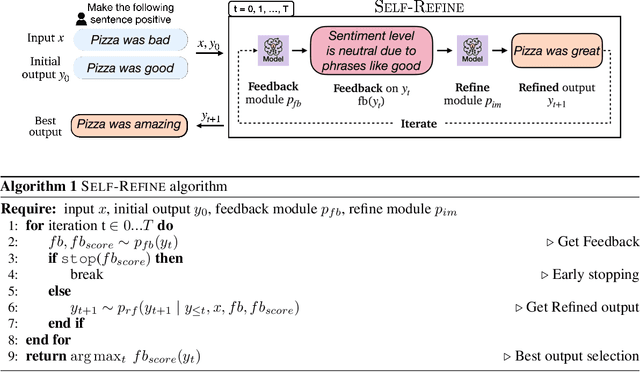

Like people, LLMs do not always generate the best text for a given generation problem on their first try (e.g., summaries, answers, explanations). Just as people then refine their text, we introduce SELF-REFINE, a framework for similarly improving initial outputs from LLMs through iterative feedback and refinement. The main idea is to generate an output using an LLM, then allow the same model to provide multi-aspect feedback for its own output; finally, the same model refines its previously generated output given its own feedback. Unlike earlier work, our iterative refinement framework does not require supervised training data or reinforcement learning, and works with a single LLM. We experiment with 7 diverse tasks, ranging from review rewriting to math reasoning, demonstrating that our approach outperforms direct generation. In all tasks, outputs generated with SELF-REFINE are preferred by humans and by automated metrics over those generated directly with GPT-3.5 and GPT-4, improving on average by absolute 20% across tasks.
Sparsely Activated Mixture-of-Experts are Robust Multi-Task Learners
Apr 16, 2022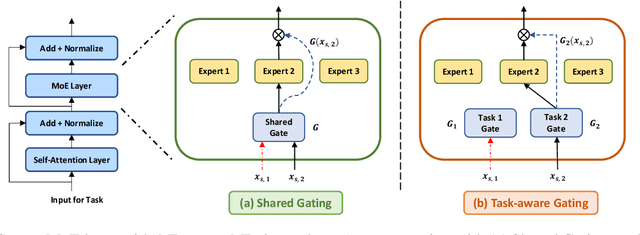
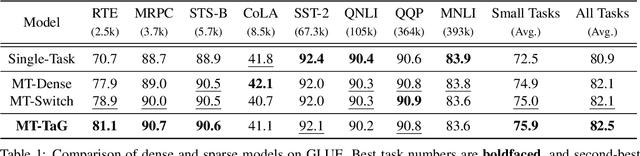
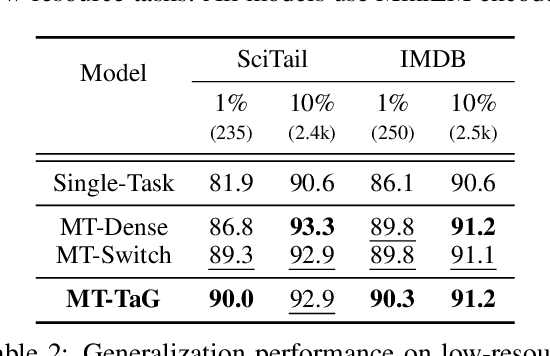
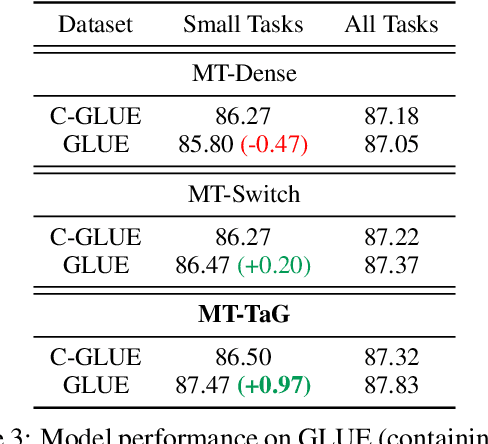
Traditional multi-task learning (MTL) methods use dense networks that use the same set of shared weights across several different tasks. This often creates interference where two or more tasks compete to pull model parameters in different directions. In this work, we study whether sparsely activated Mixture-of-Experts (MoE) improve multi-task learning by specializing some weights for learning shared representations and using the others for learning task-specific information. To this end, we devise task-aware gating functions to route examples from different tasks to specialized experts which share subsets of network weights conditioned on the task. This results in a sparsely activated multi-task model with a large number of parameters, but with the same computational cost as that of a dense model. We demonstrate such sparse networks to improve multi-task learning along three key dimensions: (i) transfer to low-resource tasks from related tasks in the training mixture; (ii) sample-efficient generalization to tasks not seen during training by making use of task-aware routing from seen related tasks; (iii) robustness to the addition of unrelated tasks by avoiding catastrophic forgetting of existing tasks.