 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShehroz S. Khan
Engagement Measurement Based on Facial Landmarks and Spatial-Temporal Graph Convolutional Networks
Mar 25, 2024
Engagement in virtual learning is crucial for a variety of factors including learner satisfaction, performance, and compliance with learning programs, but measuring it is a challenging task. There is therefore considerable interest in utilizing artificial intelligence and affective computing to measure engagement in natural settings as well as on a large scale. This paper introduces a novel, privacy-preserving method for engagement measurement from videos. It uses facial landmarks, which carry no personally identifiable information, extracted from videos via the MediaPipe deep learning solution. The extracted facial landmarks are fed to a Spatial-Temporal Graph Convolutional Network (ST-GCN) to output the engagement level of the learner in the video. To integrate the ordinal nature of the engagement variable into the training process, ST-GCNs undergo training in a novel ordinal learning framework based on transfer learning. Experimental results on two video student engagement measurement datasets show the superiority of the proposed method compared to previous methods with improved state-of-the-art on the EngageNet dataset with a %3.1 improvement in four-class engagement level classification accuracy and on the Online Student Engagement dataset with a %1.5 improvement in binary engagement classification accuracy. The relatively lightweight ST-GCN and its integration with the real-time MediaPipe deep learning solution make the proposed approach capable of being deployed on virtual learning platforms and measuring engagement in real time.
Rehabilitation Exercise Quality Assessment through Supervised Contrastive Learning with Hard and Soft Negatives
Mar 05, 2024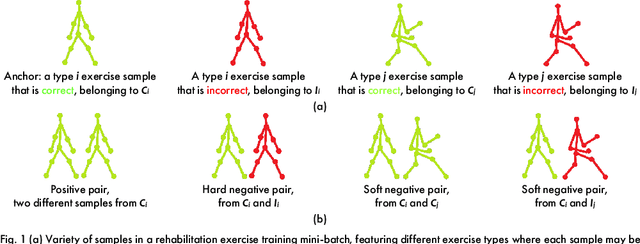
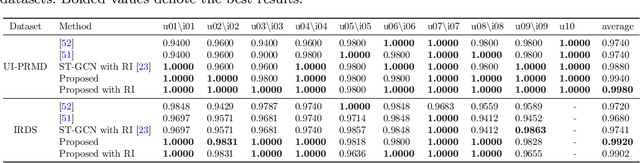
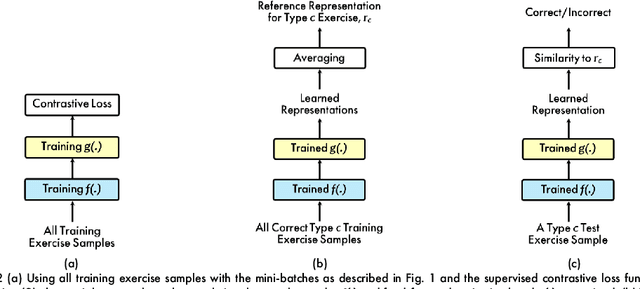

Exercise-based rehabilitation programs have proven to be effective in enhancing the quality of life and reducing mortality and rehospitalization rates. AI-driven virtual rehabilitation, which allows patients to independently complete exercises at home, utilizes AI algorithms to analyze exercise data, providing feedback to patients and updating clinicians on their progress. These programs commonly prescribe a variety of exercise types, leading to a distinct challenge in rehabilitation exercise assessment datasets: while abundant in overall training samples, these datasets often have a limited number of samples for each individual exercise type. This disparity hampers the ability of existing approaches to train generalizable models with such a small sample size per exercise. Addressing this issue, our paper introduces a novel supervised contrastive learning framework with hard and soft negative samples that effectively utilizes the entire dataset to train a single model applicable to all exercise types. This model, with a Spatial-Temporal Graph Convolutional Network (ST-GCN) architecture, demonstrated enhanced generalizability across exercises and a decrease in overall complexity. Through extensive experiments on three publicly available rehabilitation exercise assessment datasets, the University of Idaho-Physical Rehabilitation Movement Data (UI-PRMD), IntelliRehabDS (IRDS), and KInematic assessment of MOvement and clinical scores for remote monitoring of physical REhabilitation (KIMORE), our method has shown to surpass existing methods, setting a new benchmark in rehabilitation exercise assessment accuracy.
Domain-Specific Deep Learning Feature Extractor for Diabetic Foot Ulcer Detection
Nov 27, 2023Diabetic Foot Ulcer (DFU) is a condition requiring constant monitoring and evaluations for treatment. DFU patient population is on the rise and will soon outpace the available health resources. Autonomous monitoring and evaluation of DFU wounds is a much-needed area in health care. In this paper, we evaluate and identify the most accurate feature extractor that is the core basis for developing a deep-learning wound detection network. For the evaluation, we used mAP and F1-score on the publicly available DFU2020 dataset. A combination of UNet and EfficientNetb3 feature extractor resulted in the best evaluation among the 14 networks compared. UNet and Efficientnetb3 can be used as the classifier in the development of a comprehensive DFU domain-specific autonomous wound detection pipeline.
* 5 pages, 2 figures, 3 tables, 2022 IEEE International Conference on Data Mining Workshops
Temporal Shift -- Multi-Objective Loss Function for Improved Anomaly Fall Detection
Nov 06, 2023Falls are a major cause of injuries and deaths among older adults worldwide. Accurate fall detection can help reduce potential injuries and additional health complications. Different types of video modalities can be used in a home setting to detect falls, including RGB, Infrared, and Thermal cameras. Anomaly detection frameworks using autoencoders and their variants can be used for fall detection due to the data imbalance that arises from the rarity and diversity of falls. However, the use of reconstruction error in autoencoders can limit the application of networks' structures that propagate information. In this paper, we propose a new multi-objective loss function called Temporal Shift, which aims to predict both future and reconstructed frames within a window of sequential frames. The proposed loss function is evaluated on a semi-naturalistic fall detection dataset containing multiple camera modalities. The autoencoders were trained on normal activities of daily living (ADL) performed by older adults and tested on ADLs and falls performed by young adults. Temporal shift shows significant improvement to a baseline 3D Convolutional autoencoder, an attention U-Net CAE, and a multi-modal neural network. The greatest improvement was observed in an attention U-Net model improving by 0.20 AUC ROC for a single camera when compared to reconstruction alone. With significant improvement across different models, this approach has the potential to be widely adopted and improve anomaly detection capabilities in other settings besides fall detection.
Synthesizing Diabetic Foot Ulcer Images with Diffusion Model
Oct 31, 2023Diabetic Foot Ulcer (DFU) is a serious skin wound requiring specialized care. However, real DFU datasets are limited, hindering clinical training and research activities. In recent years, generative adversarial networks and diffusion models have emerged as powerful tools for generating synthetic images with remarkable realism and diversity in many applications. This paper explores the potential of diffusion models for synthesizing DFU images and evaluates their authenticity through expert clinician assessments. Additionally, evaluation metrics such as Frechet Inception Distance (FID) and Kernel Inception Distance (KID) are examined to assess the quality of the synthetic DFU images. A dataset of 2,000 DFU images is used for training the diffusion model, and the synthetic images are generated by applying diffusion processes. The results indicate that the diffusion model successfully synthesizes visually indistinguishable DFU images. 70% of the time, clinicians marked synthetic DFU images as real DFUs. However, clinicians demonstrate higher unanimous confidence in rating real images than synthetic ones. The study also reveals that FID and KID metrics do not significantly align with clinicians' assessments, suggesting alternative evaluation approaches are needed. The findings highlight the potential of diffusion models for generating synthetic DFU images and their impact on medical training programs and research in wound detection and classification.
Cross-Modal Video to Body-joints Augmentation for Rehabilitation Exercise Quality Assessment
Jun 15, 2023
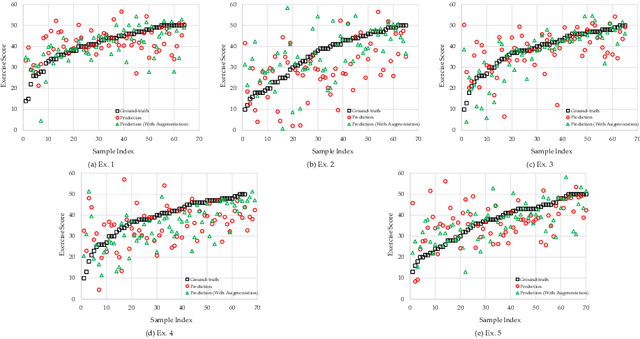
Exercise-based rehabilitation programs have been shown to enhance quality of life and reduce mortality and rehospitalizations. AI-driven virtual rehabilitation programs enable patients to complete exercises independently at home while AI algorithms can analyze exercise data to provide feedback to patients and report their progress to clinicians. This paper introduces a novel approach to assessing the quality of rehabilitation exercises using RGB video. Sequences of skeletal body joints are extracted from consecutive RGB video frames and analyzed by many-to-one sequential neural networks to evaluate exercise quality. Existing datasets for exercise rehabilitation lack adequate samples for training deep sequential neural networks to generalize effectively. A cross-modal data augmentation approach is proposed to resolve this problem. Visual augmentation techniques are applied to video data, and body joints extracted from the resulting augmented videos are used for training sequential neural networks. Extensive experiments conducted on the KInematic assessment of MOvement and clinical scores for remote monitoring of physical REhabilitation (KIMORE) dataset, demonstrate the superiority of the proposed method over previous baseline approaches. The ablation study highlights a significant enhancement in exercise quality assessment following cross-modal augmentation.
Supervised and Unsupervised Deep Learning Approaches for EEG Seizure Prediction
Apr 24, 2023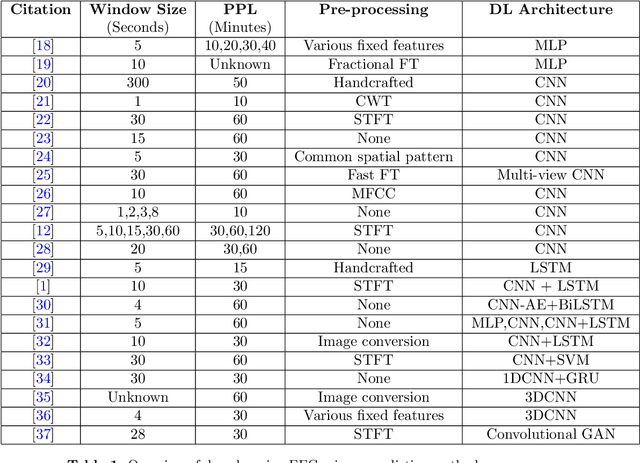
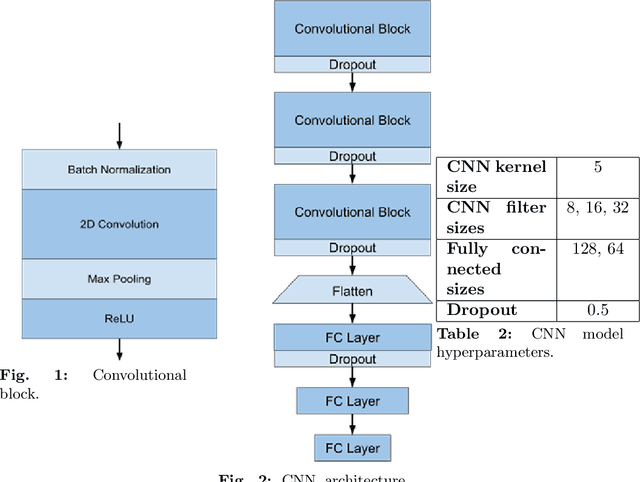
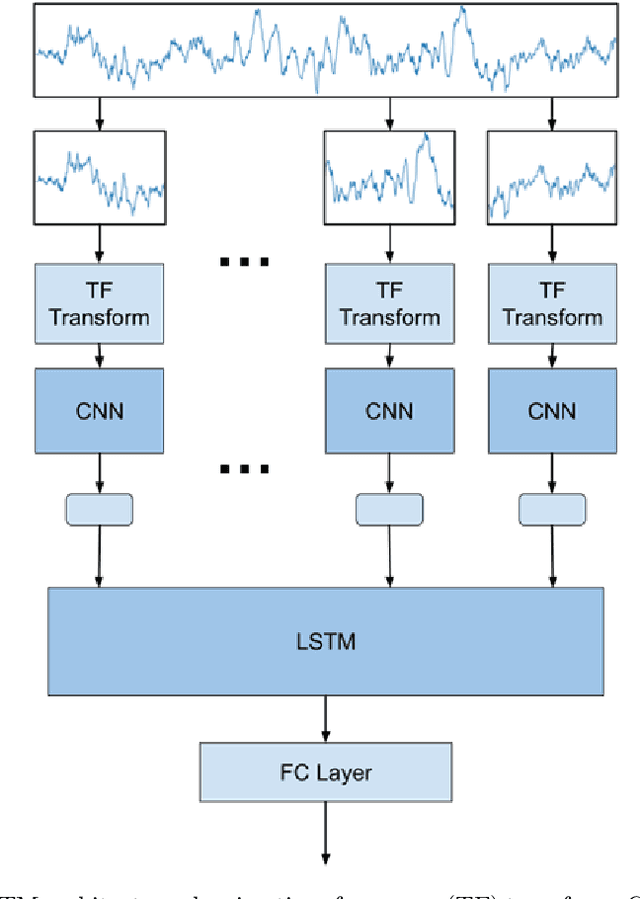
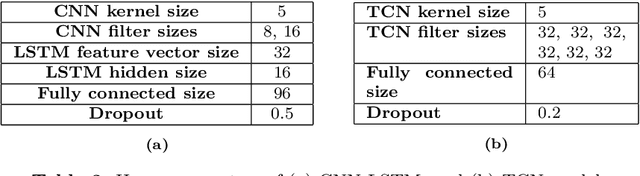
Epilepsy affects more than 50 million people worldwide, making it one of the world's most prevalent neurological diseases. The main symptom of epilepsy is seizures, which occur abruptly and can cause serious injury or death. The ability to predict the occurrence of an epileptic seizure could alleviate many risks and stresses people with epilepsy face. Most of the previous work is focused at seizure detection, we pivot our focus to seizure prediction problem. We formulate the problem of detecting preictal (or pre-seizure) with reference to normal EEG as a precursor to incoming seizure. To this end, we developed several supervised deep learning approaches model to identify preictal EEG from normal EEG. We further develop novel unsupervised deep learning approaches to train the models on only normal EEG, and detecting pre-seizure EEG as an anomalous event. These deep learning models were trained and evaluated on two large EEG seizure datasets in a person-specific manner. We found that both supervised and unsupervised approaches are feasible; however, their performance varies depending on the patient, approach and architecture. This new line of research has the potential to develop therapeutic interventions and save human lives.
Rehabilitation Exercise Repetition Segmentation and Counting using Skeletal Body Joints
Apr 19, 2023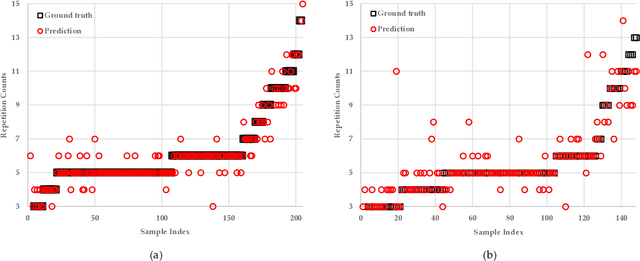
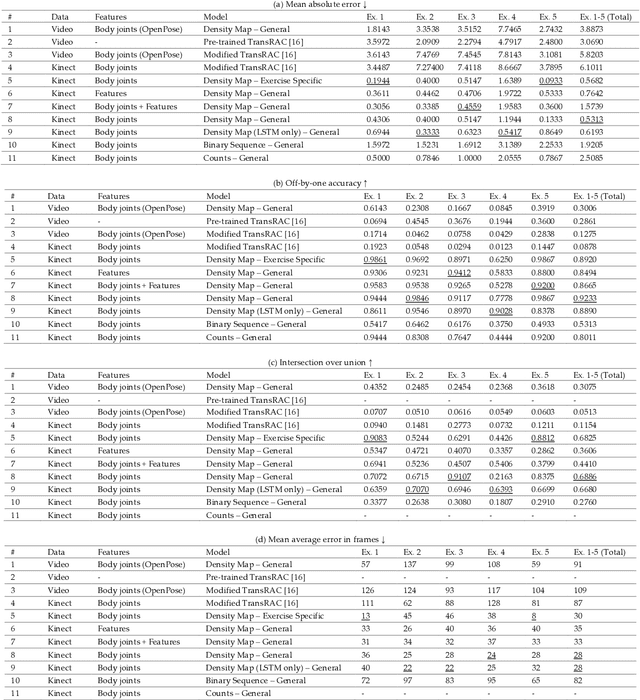
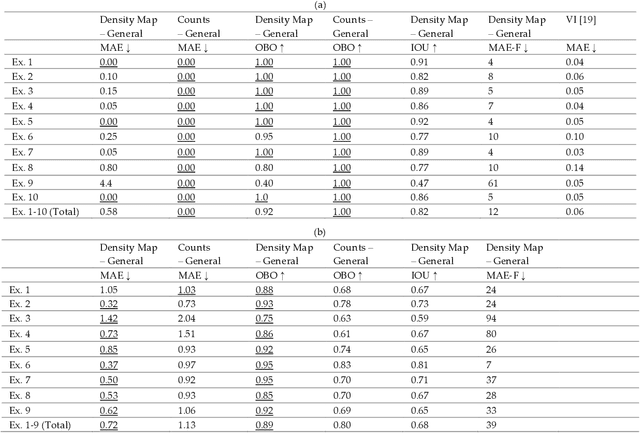
Physical exercise is an essential component of rehabilitation programs that improve quality of life and reduce mortality and re-hospitalization rates. In AI-driven virtual rehabilitation programs, patients complete their exercises independently at home, while AI algorithms analyze the exercise data to provide feedback to patients and report their progress to clinicians. To analyze exercise data, the first step is to segment it into consecutive repetitions. There has been a significant amount of research performed on segmenting and counting the repetitive activities of healthy individuals using raw video data, which raises concerns regarding privacy and is computationally intensive. Previous research on patients' rehabilitation exercise segmentation relied on data collected by multiple wearable sensors, which are difficult to use at home by rehabilitation patients. Compared to healthy individuals, segmenting and counting exercise repetitions in patients is more challenging because of the irregular repetition duration and the variation between repetitions. This paper presents a novel approach for segmenting and counting the repetitions of rehabilitation exercises performed by patients, based on their skeletal body joints. Skeletal body joints can be acquired through depth cameras or computer vision techniques applied to RGB videos of patients. Various sequential neural networks are designed to analyze the sequences of skeletal body joints and perform repetition segmentation and counting. Extensive experiments on three publicly available rehabilitation exercise datasets, KIMORE, UI-PRMD, and IntelliRehabDS, demonstrate the superiority of the proposed method compared to previous methods. The proposed method enables accurate exercise analysis while preserving privacy, facilitating the effective delivery of virtual rehabilitation programs.
Undersampling and Cumulative Class Re-decision Methods to Improve Detection of Agitation in People with Dementia
Feb 07, 2023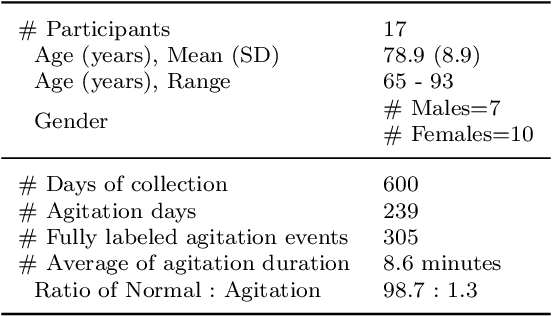
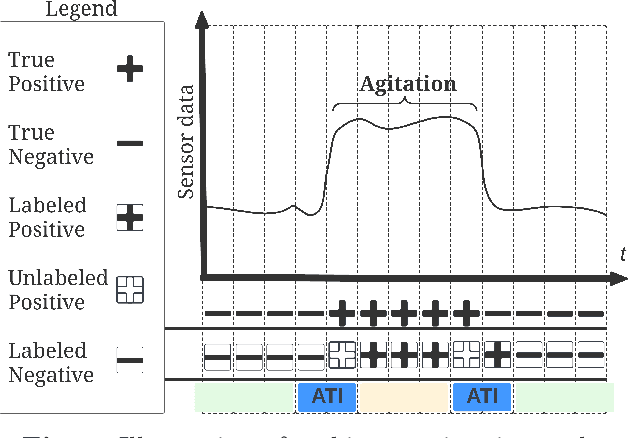
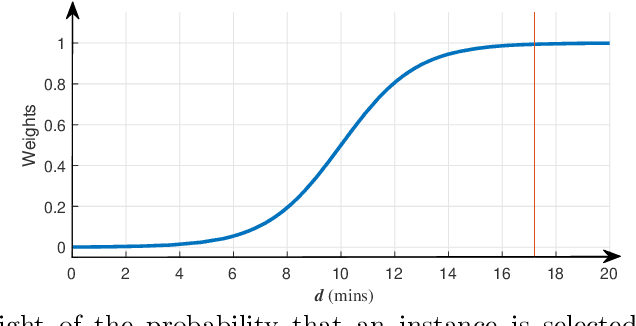
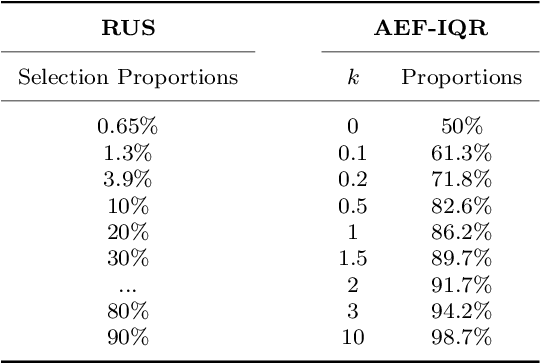
Agitation is one of the most prevalent symptoms in people with dementia (PwD) that can place themselves and the caregiver's safety at risk. Developing objective agitation detection approaches is important to support health and safety of PwD living in a residential setting. In a previous study, we collected multimodal wearable sensor data from 17 participants for 600 days and developed machine learning models for predicting agitation in one-minute windows. However, there are significant limitations in the dataset, such as imbalance problem and potential imprecise labels as the occurrence of agitation is much rarer in comparison to the normal behaviours. In this paper, we first implement different undersampling methods to eliminate the imbalance problem, and come to the conclusion that only 20% of normal behaviour data are adequate to train a competitive agitation detection model. Then, we design a weighted undersampling method to evaluate the manual labeling mechanism given the ambiguous time interval (ATI) assumption. After that, the postprocessing method of cumulative class re-decision (CCR) is proposed based on the historical sequential information and continuity characteristic of agitation, improving the decision-making performance for the potential application of agitation detection system. The results show that a combination of undersampling and CCR improves best F1-score by 26.6% and other metrics to varying degrees with less training time and data used, and inspires a way to find the potential range of optimal threshold reference for clinical purpose.
Bag of States: A Non-sequential Approach to Video-based Engagement Measurement
Jan 17, 2023
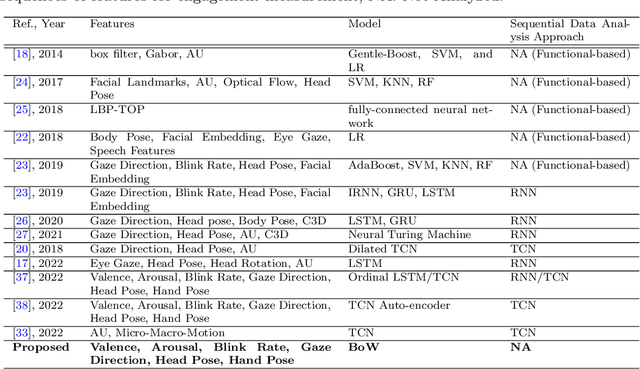
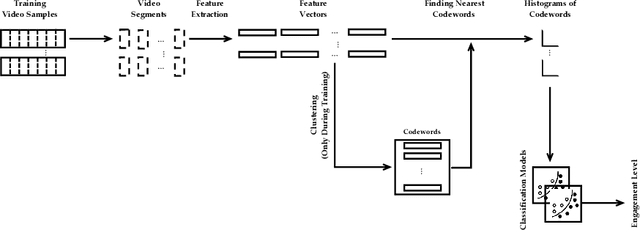
Automatic measurement of student engagement provides helpful information for instructors to meet learning program objectives and individualize program delivery. Students' behavioral and emotional states need to be analyzed at fine-grained time scales in order to measure their level of engagement. Many existing approaches have developed sequential and spatiotemporal models, such as recurrent neural networks, temporal convolutional networks, and three-dimensional convolutional neural networks, for measuring student engagement from videos. These models are trained to incorporate the order of behavioral and emotional states of students into video analysis and output their level of engagement. In this paper, backed by educational psychology, we question the necessity of modeling the order of behavioral and emotional states of students in measuring their engagement. We develop bag-of-words-based models in which only the occurrence of behavioral and emotional states of students is modeled and analyzed and not the order in which they occur. Behavioral and affective features are extracted from videos and analyzed by the proposed models to determine the level of engagement in an ordinal-output classification setting. Compared to the existing sequential and spatiotemporal approaches for engagement measurement, the proposed non-sequential approach improves the state-of-the-art results. According to experimental results, our method significantly improved engagement level classification accuracy on the IIITB Online SE dataset by 26% compared to sequential models and achieved engagement level classification accuracy as high as 66.58% on the DAiSEE student engagement dataset.