 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSheng Sun
Privacy-Enhanced Training-as-a-Service for On-Device Intelligence: Concept, Architectural Scheme, and Open Problems
Apr 27, 2024
On-device intelligence (ODI) enables artificial intelligence (AI) applications to run on end devices, providing real-time and customized AI inference without relying on remote servers. However, training models for on-device deployment face significant challenges due to the decentralized and privacy-sensitive nature of users' data, along with end-side constraints related to network connectivity, computation efficiency, etc. Existing training paradigms, such as cloud-based training, federated learning, and transfer learning, fail to sufficiently address these practical constraints that are prevalent for devices. To overcome these challenges, we propose Privacy-Enhanced Training-as-a-Service (PTaaS), a novel service computing paradigm that provides privacy-friendly, customized AI model training for end devices. PTaaS outsources the core training process to remote and powerful cloud or edge servers, efficiently developing customized on-device models based on uploaded anonymous queries, enhancing data privacy while reducing the computation load on individual devices. We explore the definition, goals, and design principles of PTaaS, alongside emerging technologies that support the PTaaS paradigm. An architectural scheme for PTaaS is also presented, followed by a series of open problems that set the stage for future research directions in the field of PTaaS.
Privacy-Preserving Training-as-a-Service for On-Device Intelligence: Concept, Architectural Scheme, and Open Problems
Apr 16, 2024On-device intelligence (ODI) enables artificial intelligence (AI) applications to run on end devices, providing real-time and customized AI services without relying on remote servers. However, training models for on-device deployment face significant challenges due to the decentralized and privacy-sensitive nature of users' data, along with end-side constraints related to network connectivity, computation efficiency, etc. Existing training paradigms, such as cloud-based training, federated learning, and transfer learning, fail to sufficiently address these practical constraints that are prevalent for devices. To overcome these challenges, we propose Privacy-Preserving Training-as-a-Service (PTaaS), a novel service computing paradigm that provides privacy-friendly, customized AI model training for end devices. PTaaS outsources the core training process to remote and powerful cloud or edge servers, efficiently developing customized on-device models based on uploaded anonymous queries, ensuring data privacy while reducing the computation load on individual devices. We explore the definition, goals, and design principles of PTaaS, alongside emerging technologies that support the PTaaS paradigm. An architectural scheme for PTaaS is also presented, followed by a series of open problems that set the stage for future research directions in the field of PTaaS.
Personalized Federated Learning for Spatio-Temporal Forecasting: A Dual Semantic Alignment-Based Contrastive Approach
Apr 04, 2024The existing federated learning (FL) methods for spatio-temporal forecasting fail to capture the inherent spatio-temporal heterogeneity, which calls for personalized FL (PFL) methods to model the spatio-temporally variant patterns. While contrastive learning approach is promising in addressing spatio-temporal heterogeneity, the existing methods are noneffective in determining negative pairs and can hardly apply to PFL paradigm. To tackle this limitation, we propose a novel PFL method, named Federated dUal sEmantic aLignment-based contraStive learning (FUELS), which can adaptively align positive and negative pairs based on semantic similarity, thereby injecting precise spatio-temporal heterogeneity into the latent representation space by auxiliary contrastive tasks. From temporal perspective, a hard negative filtering module is introduced to dynamically align heterogeneous temporal representations for the supplemented intra-client contrastive task. From spatial perspective, we design lightweight-but-efficient prototypes as client-level semantic representations, based on which the server evaluates spatial similarity and yields client-customized global prototypes for the supplemented inter-client contrastive task. Extensive experiments demonstrate that FUELS outperforms state-of-the-art methods, with communication cost decreasing by around 94%.
Federated Class-Incremental Learning with New-Class Augmented Self-Distillation
Jan 09, 2024Federated Learning (FL) enables collaborative model training among participants while guaranteeing the privacy of raw data. Mainstream FL methodologies overlook the dynamic nature of real-world data, particularly its tendency to grow in volume and diversify in classes over time. This oversight results in FL methods suffering from catastrophic forgetting, where the trained models inadvertently discard previously learned information upon assimilating new data. In response to this challenge, we propose a novel Federated Class-Incremental Learning (FCIL) method, named \underline{Fed}erated \underline{C}lass-Incremental \underline{L}earning with New-Class \underline{A}ugmented \underline{S}elf-Di\underline{S}tillation (FedCLASS). The core of FedCLASS is to enrich the class scores of historical models with new class scores predicted by current models and utilize the combined knowledge for self-distillation, enabling a more sufficient and precise knowledge transfer from historical models to current models. Theoretical analyses demonstrate that FedCLASS stands on reliable foundations, considering scores of old classes predicted by historical models as conditional probabilities in the absence of new classes, and the scores of new classes predicted by current models as the conditional probabilities of class scores derived from historical models. Empirical experiments demonstrate the superiority of FedCLASS over four baseline algorithms in reducing average forgetting rate and boosting global accuracy.
Logits Poisoning Attack in Federated Distillation
Jan 08, 2024Federated Distillation (FD) is a novel and promising distributed machine learning paradigm, where knowledge distillation is leveraged to facilitate a more efficient and flexible cross-device knowledge transfer in federated learning. By optimizing local models with knowledge distillation, FD circumvents the necessity of uploading large-scale model parameters to the central server, simultaneously preserving the raw data on local clients. Despite the growing popularity of FD, there is a noticeable gap in previous works concerning the exploration of poisoning attacks within this framework. This can lead to a scant understanding of the vulnerabilities to potential adversarial actions. To this end, we introduce FDLA, a poisoning attack method tailored for FD. FDLA manipulates logit communications in FD, aiming to significantly degrade model performance on clients through misleading the discrimination of private samples. Through extensive simulation experiments across a variety of datasets, attack scenarios, and FD configurations, we demonstrate that LPA effectively compromises client model accuracy, outperforming established baseline algorithms in this regard. Our findings underscore the critical need for robust defense mechanisms in FD settings to mitigate such adversarial threats.
Improving Communication Efficiency of Federated Distillation via Accumulating Local Updates
Dec 07, 2023As an emerging federated learning paradigm, federated distillation enables communication-efficient model training by transmitting only small-scale knowledge during the learning process. To further improve the communication efficiency of federated distillation, we propose a novel technique, ALU, which accumulates multiple rounds of local updates before transferring the knowledge to the central server. ALU drastically decreases the frequency of communication in federated distillation, thereby significantly reducing the communication overhead during the training process. Empirical experiments demonstrate the substantial effect of ALU in improving the communication efficiency of federated distillation.
Federated Skewed Label Learning with Logits Fusion
Nov 14, 2023Federated learning (FL) aims to collaboratively train a shared model across multiple clients without transmitting their local data. Data heterogeneity is a critical challenge in realistic FL settings, as it causes significant performance deterioration due to discrepancies in optimization among local models. In this work, we focus on label distribution skew, a common scenario in data heterogeneity, where the data label categories are imbalanced on each client. To address this issue, we propose FedBalance, which corrects the optimization bias among local models by calibrating their logits. Specifically, we introduce an extra private weak learner on the client side, which forms an ensemble model with the local model. By fusing the logits of the two models, the private weak learner can capture the variance of different data, regardless of their category. Therefore, the optimization direction of local models can be improved by increasing the penalty for misclassifying minority classes and reducing the attention to majority classes, resulting in a better global model. Extensive experiments show that our method can gain 13\% higher average accuracy compared with state-of-the-art methods.
FedBIAD: Communication-Efficient and Accuracy-Guaranteed Federated Learning with Bayesian Inference-Based Adaptive Dropout
Jul 14, 2023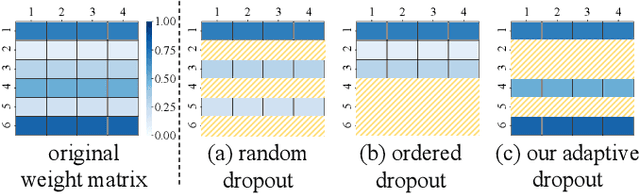
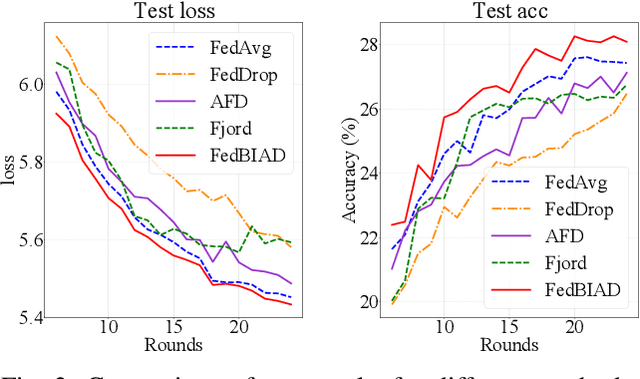
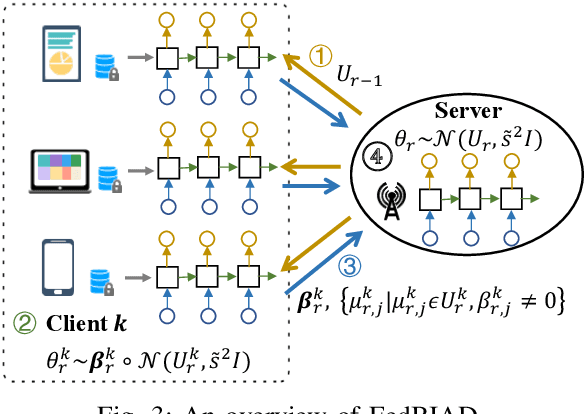
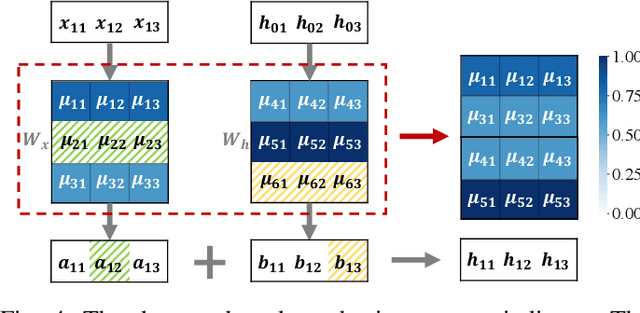
Federated Learning (FL) emerges as a distributed machine learning paradigm without end-user data transmission, effectively avoiding privacy leakage. Participating devices in FL are usually bandwidth-constrained, and the uplink is much slower than the downlink in wireless networks, which causes a severe uplink communication bottleneck. A prominent direction to alleviate this problem is federated dropout, which drops fractional weights of local models. However, existing federated dropout studies focus on random or ordered dropout and lack theoretical support, resulting in unguaranteed performance. In this paper, we propose Federated learning with Bayesian Inference-based Adaptive Dropout (FedBIAD), which regards weight rows of local models as probability distributions and adaptively drops partial weight rows based on importance indicators correlated with the trend of local training loss. By applying FedBIAD, each client adaptively selects a high-quality dropping pattern with accurate approximations and only transmits parameters of non-dropped weight rows to mitigate uplink costs while improving accuracy. Theoretical analysis demonstrates that the convergence rate of the average generalization error of FedBIAD is minimax optimal up to a squared logarithmic factor. Extensive experiments on image classification and next-word prediction show that compared with status quo approaches, FedBIAD provides 2x uplink reduction with an accuracy increase of up to 2.41% even on non-Independent and Identically Distributed (non-IID) data, which brings up to 72% decrease in training time.
Online Spatio-Temporal Correlation-Based Federated Learning for Traffic Flow Forecasting
Feb 17, 2023



Traffic flow forecasting (TFF) is of great importance to the construction of Intelligent Transportation Systems (ITS). To mitigate communication burden and tackle with the problem of privacy leakage aroused by centralized forecasting methods, Federated Learning (FL) has been applied to TFF. However, existing FL-based approaches employ batch learning manner, which makes the pre-trained models inapplicable to subsequent traffic data, thus exhibiting subpar prediction performance. In this paper, we perform the first study of forecasting traffic flow adopting Online Learning (OL) manner in FL framework and then propose a novel prediction method named Online Spatio-Temporal Correlation-based Federated Learning (FedOSTC), aiming to guarantee performance gains regardless of traffic fluctuation. Specifically, clients employ Gated Recurrent Unit (GRU)-based encoders to obtain the internal temporal patterns inside traffic data sequences. Then, the central server evaluates spatial correlation among clients via Graph Attention Network (GAT), catering to the dynamic changes of spatial closeness caused by traffic fluctuation. Furthermore, to improve the generalization of the global model for upcoming traffic data, a period-aware aggregation mechanism is proposed to aggregate the local models which are optimized using Online Gradient Descent (OGD) algorithm at clients. We perform comprehensive experiments on two real-world datasets to validate the efficiency and effectiveness of our proposed method and the numerical results demonstrate the superiority of FedOSTC.
Survey of Knowledge Distillation in Federated Edge Learning
Jan 14, 2023
The increasing demand for intelligent services and privacy protection of mobile and Internet of Things (IoT) devices motivates the wide application of Federated Edge Learning (FEL), in which devices collaboratively train on-device Machine Learning (ML) models without sharing their private data. \textcolor{black}{Limited by device hardware, diverse user behaviors and network infrastructure, the algorithm design of FEL faces challenges related to resources, personalization and network environments}, and Knowledge Distillation (KD) has been leveraged as an important technique to tackle the above challenges in FEL. In this paper, we investigate the works that KD applies to FEL, discuss the limitations and open problems of existing KD-based FEL approaches, and provide guidance for their real deployment.