 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSheng-Min Shih
Your ViT is Secretly a Hybrid Discriminative-Generative Diffusion Model
Aug 16, 2022
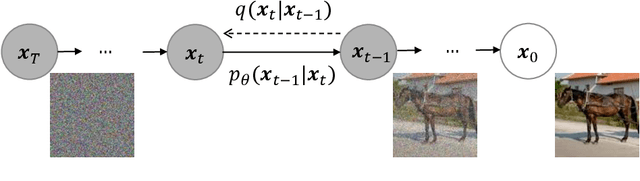
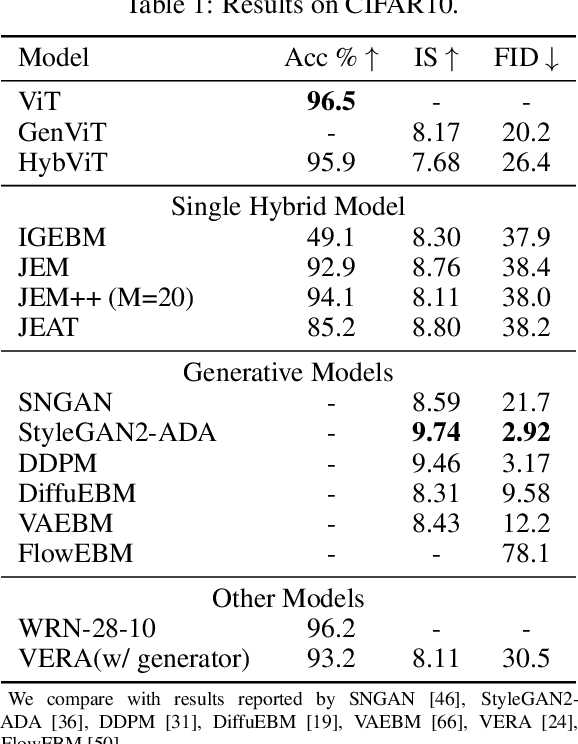
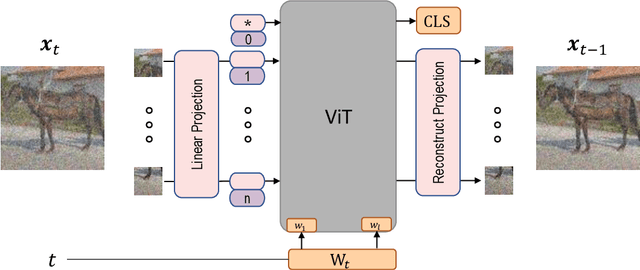
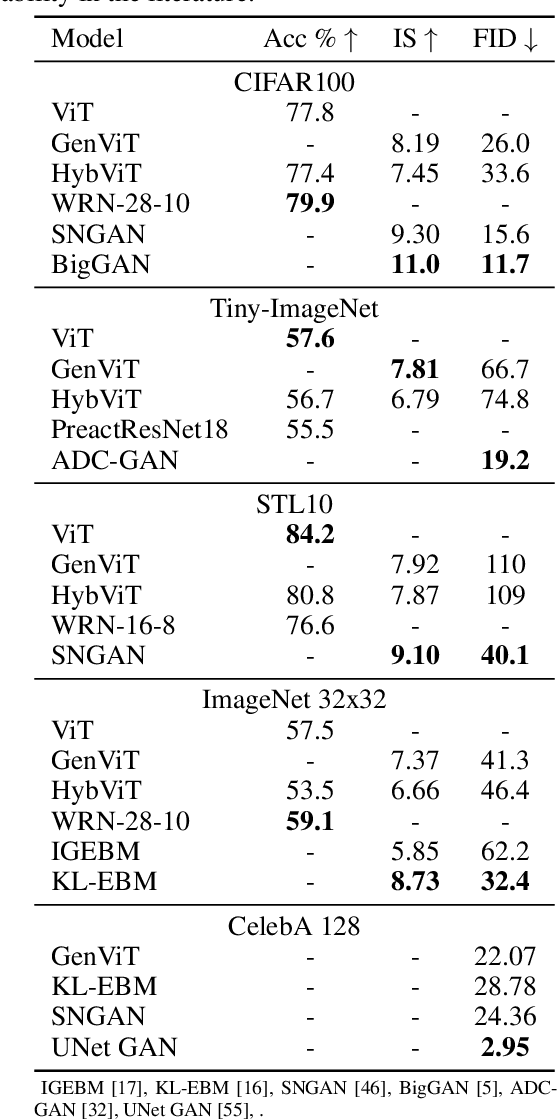
Diffusion Denoising Probability Models (DDPM) and Vision Transformer (ViT) have demonstrated significant progress in generative tasks and discriminative tasks, respectively, and thus far these models have largely been developed in their own domains. In this paper, we establish a direct connection between DDPM and ViT by integrating the ViT architecture into DDPM, and introduce a new generative model called Generative ViT (GenViT). The modeling flexibility of ViT enables us to further extend GenViT to hybrid discriminative-generative modeling, and introduce a Hybrid ViT (HybViT). Our work is among the first to explore a single ViT for image generation and classification jointly. We conduct a series of experiments to analyze the performance of proposed models and demonstrate their superiority over prior state-of-the-arts in both generative and discriminative tasks. Our code and pre-trained models can be found in https://github.com/sndnyang/Diffusion_ViT .
Robust Information Retrieval for False Claims with Distracting Entities In Fact Extraction and Verification
Dec 10, 2021
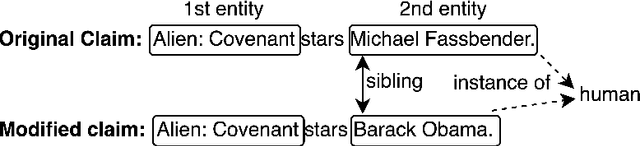
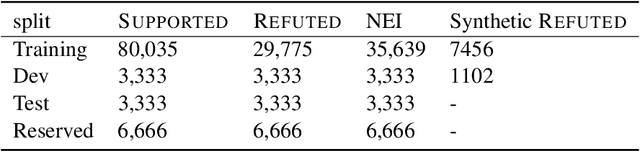
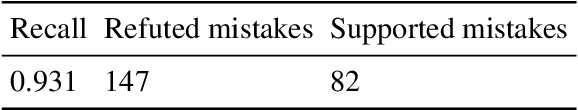
Accurate evidence retrieval is essential for automated fact checking. Little previous research has focused on the differences between true and false claims and how they affect evidence retrieval. This paper shows that, compared with true claims, false claims more frequently contain irrelevant entities which can distract evidence retrieval model. A BERT-based retrieval model made more mistakes in retrieving refuting evidence for false claims than supporting evidence for true claims. When tested with adversarial false claims (synthetically generated) containing irrelevant entities, the recall of the retrieval model is significantly lower than that for original claims. These results suggest that the vanilla BERT-based retrieval model is not robust to irrelevant entities in the false claims. By augmenting the training data with synthetic false claims containing irrelevant entities, the trained model achieved higher evidence recall, including that of false claims with irrelevant entities. In addition, using separate models to retrieve refuting and supporting evidence and then aggregating them can also increase the evidence recall, including that of false claims with irrelevant entities. These results suggest that we can increase the BERT-based retrieval model's robustness to false claims with irrelevant entities via data augmentation and model ensemble.
GANMEX: One-vs-One Attributions using GAN-based Model Explainability
Dec 01, 2020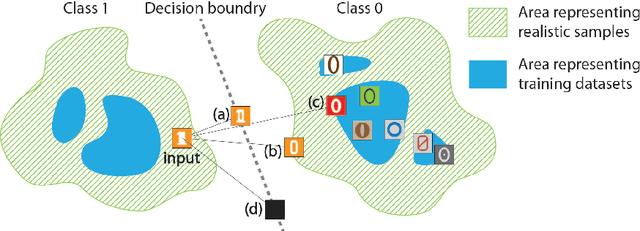
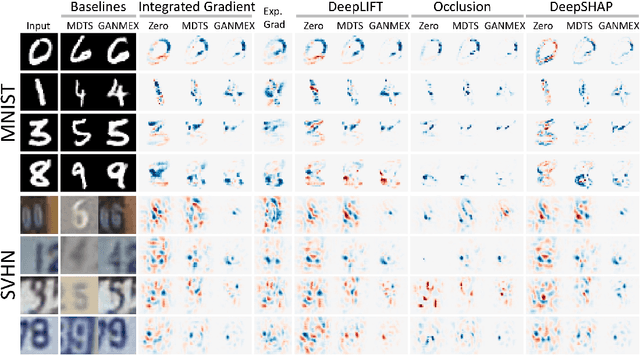
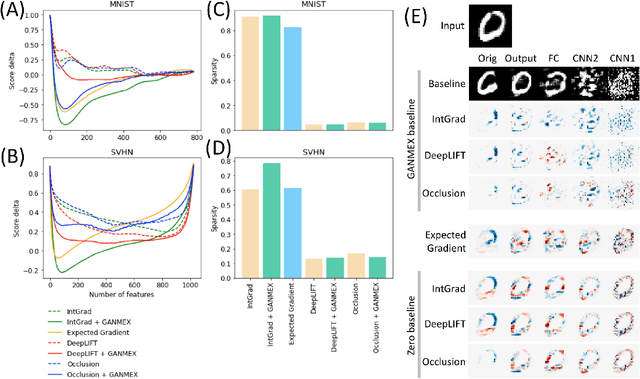
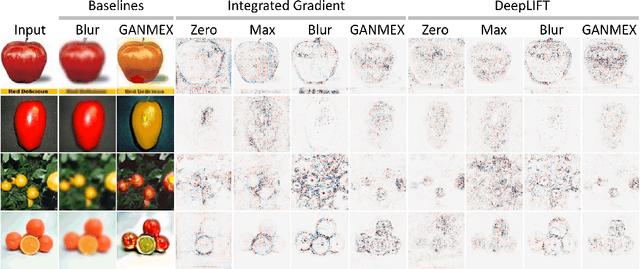
Attribution methods have been shown as promising approaches for identifying key features that led to learned model predictions. While most existing attribution methods rely on a baseline input for performing feature perturbations, limited research has been conducted to address the baseline selection issues. Poor choices of baselines limit the ability of one-vs-one explanations for multi-class classifiers, which means the attribution methods were not able to explain why an input belongs to its original class but not the other specified target class. Achieving one-vs-one explanation is crucial when certain classes are more similar than others, e.g. two bird types among multiple animals, by focusing on key differentiating features rather than shared features across classes. In this paper, we present GANMEX, a novel approach applying Generative Adversarial Networks (GAN) by incorporating the to-be-explained classifier as part of the adversarial networks. Our approach effectively selects the baseline as the closest realistic sample belong to the target class, which allows attribution methods to provide true one-vs-one explanations. We showed that GANMEX baselines improved the saliency maps and led to stronger performance on perturbation-based evaluation metrics over the existing baselines. Existing attribution results are known for being insensitive to model randomization, and we demonstrated that GANMEX baselines led to better outcome under the cascading randomization of the model.