 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShengjie Ma
3D Gaussian Blendshapes for Head Avatar Animation
May 02, 2024
We introduce 3D Gaussian blendshapes for modeling photorealistic head avatars. Taking a monocular video as input, we learn a base head model of neutral expression, along with a group of expression blendshapes, each of which corresponds to a basis expression in classical parametric face models. Both the neutral model and expression blendshapes are represented as 3D Gaussians, which contain a few properties to depict the avatar appearance. The avatar model of an arbitrary expression can be effectively generated by combining the neutral model and expression blendshapes through linear blending of Gaussians with the expression coefficients. High-fidelity head avatar animations can be synthesized in real time using Gaussian splatting. Compared to state-of-the-art methods, our Gaussian blendshape representation better captures high-frequency details exhibited in input video, and achieves superior rendering performance.
Leveraging Large Language Models for Relevance Judgments in Legal Case Retrieval
Mar 27, 2024
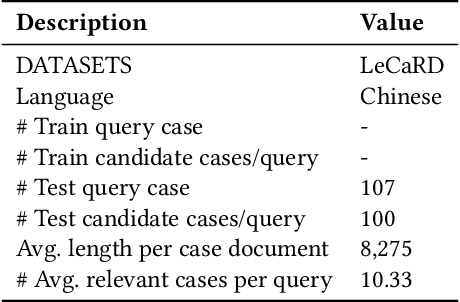
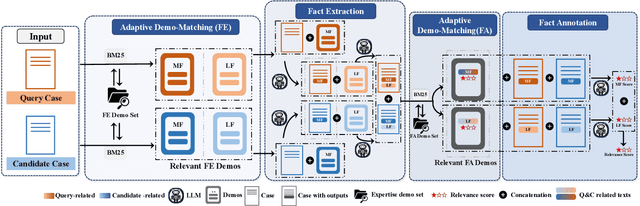

Collecting relevant judgments for legal case retrieval is a challenging and time-consuming task. Accurately judging the relevance between two legal cases requires a considerable effort to read the lengthy text and a high level of domain expertise to extract Legal Facts and make juridical judgments. With the advent of advanced large language models, some recent studies have suggested that it is promising to use LLMs for relevance judgment. Nonetheless, the method of employing a general large language model for reliable relevance judgments in legal case retrieval is yet to be thoroughly explored. To fill this research gap, we devise a novel few-shot workflow tailored to the relevant judgment of legal cases. The proposed workflow breaks down the annotation process into a series of stages, imitating the process employed by human annotators and enabling a flexible integration of expert reasoning to enhance the accuracy of relevance judgments. By comparing the relevance judgments of LLMs and human experts, we empirically show that we can obtain reliable relevance judgments with the proposed workflow. Furthermore, we demonstrate the capacity to augment existing legal case retrieval models through the synthesis of data generated by the large language model.