 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShengxian Wan
RLTM: An Efficient Neural IR Framework for Long Documents
Aug 11, 2019
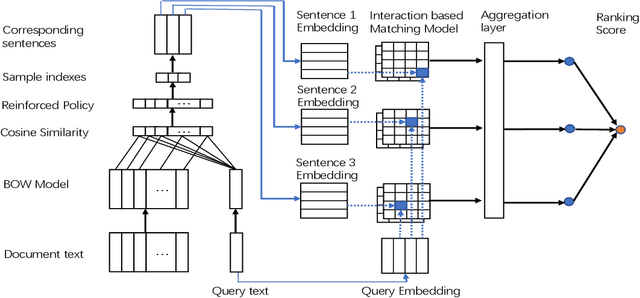
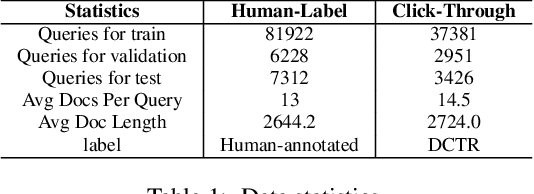
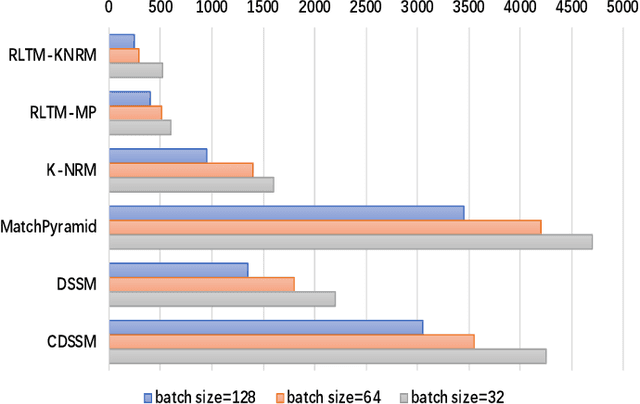

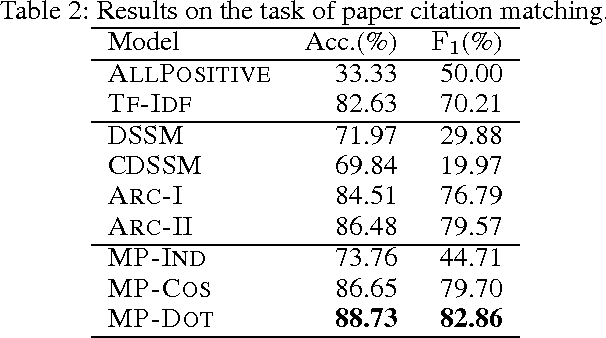
Deep neural networks have achieved significant improvements in information retrieval (IR). However, most existing models are computational costly and can not efficiently scale to long documents. This paper proposes a novel End-to-End neural ranking framework called Reinforced Long Text Matching (RLTM) which matches a query with long documents efficiently and effectively. The core idea behind the framework can be analogous to the human judgment process which firstly locates the relevance parts quickly from the whole document and then matches these parts with the query carefully to obtain the final label. Firstly, we select relevant sentences from the long documents by a coarse and efficient matching model. Secondly, we generate a relevance score by a more sophisticated matching model based on the sentence selected. The whole model is trained jointly with reinforcement learning in a pairwise manner by maximizing the expected score gaps between positive and negative examples. Experimental results demonstrate that RLTM has greatly improved the efficiency and effectiveness of the state-of-the-art models.
Match-SRNN: Modeling the Recursive Matching Structure with Spatial RNN
Apr 15, 2016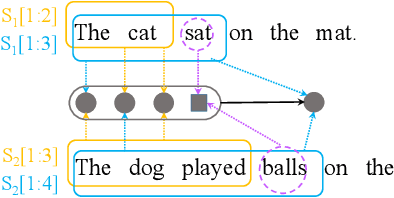
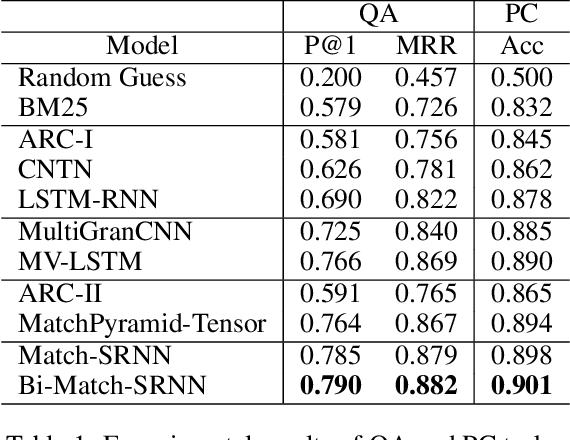
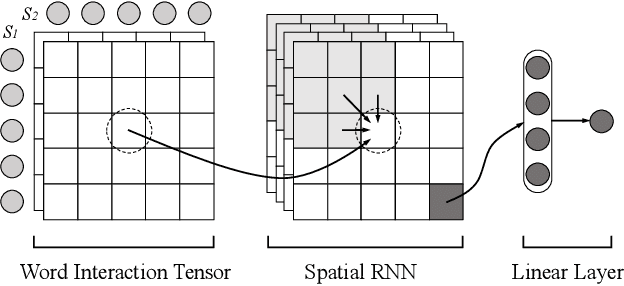
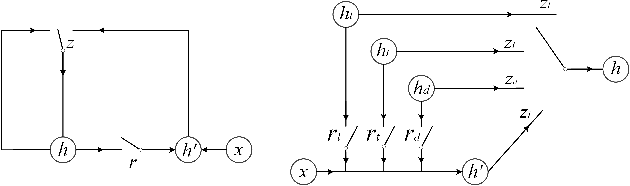
Semantic matching, which aims to determine the matching degree between two texts, is a fundamental problem for many NLP applications. Recently, deep learning approach has been applied to this problem and significant improvements have been achieved. In this paper, we propose to view the generation of the global interaction between two texts as a recursive process: i.e. the interaction of two texts at each position is a composition of the interactions between their prefixes as well as the word level interaction at the current position. Based on this idea, we propose a novel deep architecture, namely Match-SRNN, to model the recursive matching structure. Firstly, a tensor is constructed to capture the word level interactions. Then a spatial RNN is applied to integrate the local interactions recursively, with importance determined by four types of gates. Finally, the matching score is calculated based on the global interaction. We show that, after degenerated to the exact matching scenario, Match-SRNN can approximate the dynamic programming process of longest common subsequence. Thus, there exists a clear interpretation for Match-SRNN. Our experiments on two semantic matching tasks showed the effectiveness of Match-SRNN, and its ability of visualizing the learned matching structure.
Text Matching as Image Recognition
Feb 20, 2016
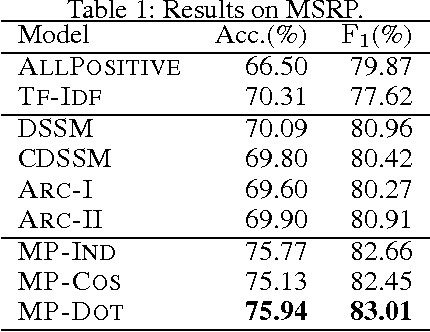
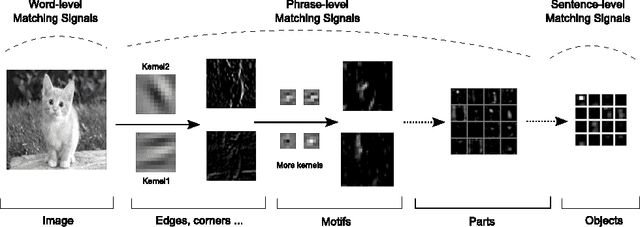
Matching two texts is a fundamental problem in many natural language processing tasks. An effective way is to extract meaningful matching patterns from words, phrases, and sentences to produce the matching score. Inspired by the success of convolutional neural network in image recognition, where neurons can capture many complicated patterns based on the extracted elementary visual patterns such as oriented edges and corners, we propose to model text matching as the problem of image recognition. Firstly, a matching matrix whose entries represent the similarities between words is constructed and viewed as an image. Then a convolutional neural network is utilized to capture rich matching patterns in a layer-by-layer way. We show that by resembling the compositional hierarchies of patterns in image recognition, our model can successfully identify salient signals such as n-gram and n-term matchings. Experimental results demonstrate its superiority against the baselines.
A Deep Architecture for Semantic Matching with Multiple Positional Sentence Representations
Nov 26, 2015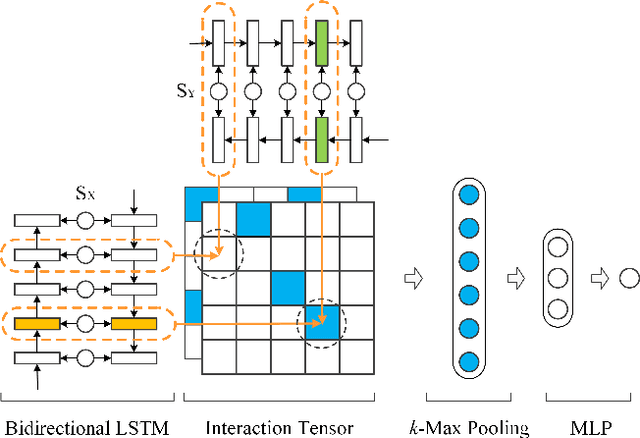

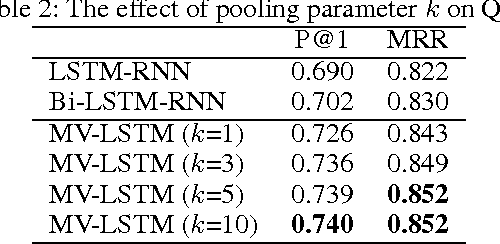
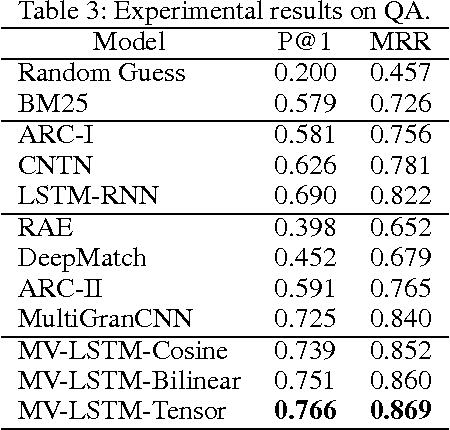
Matching natural language sentences is central for many applications such as information retrieval and question answering. Existing deep models rely on a single sentence representation or multiple granularity representations for matching. However, such methods cannot well capture the contextualized local information in the matching process. To tackle this problem, we present a new deep architecture to match two sentences with multiple positional sentence representations. Specifically, each positional sentence representation is a sentence representation at this position, generated by a bidirectional long short term memory (Bi-LSTM). The matching score is finally produced by aggregating interactions between these different positional sentence representations, through $k$-Max pooling and a multi-layer perceptron. Our model has several advantages: (1) By using Bi-LSTM, rich context of the whole sentence is leveraged to capture the contextualized local information in each positional sentence representation; (2) By matching with multiple positional sentence representations, it is flexible to aggregate different important contextualized local information in a sentence to support the matching; (3) Experiments on different tasks such as question answering and sentence completion demonstrate the superiority of our model.