 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShibin Zheng
GAPLE: Generalizable Approaching Policy LEarning for Robotic Object Searching in Indoor Environment
Mar 07, 2019
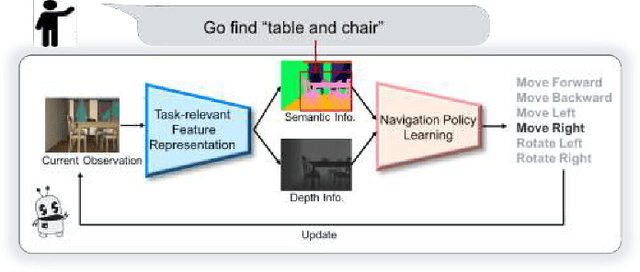
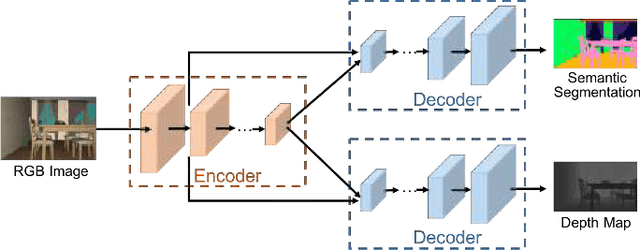
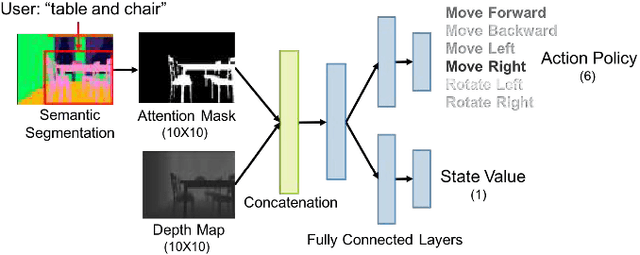

We study the problem of learning a generalizable action policy for an intelligent agent to actively approach an object of interest in an indoor environment solely from its visual inputs. While scene-driven or recognition-driven visual navigation has been widely studied, prior efforts suffer severely from the limited generalization capability. In this paper, we first argue the object searching task is environment dependent while the approaching ability is general. To learn a generalizable approaching policy, we present a novel solution dubbed as GAPLE which adopts two channels of visual features: depth and semantic segmentation, as the inputs to the policy learning module. The empirical studies conducted on the House3D dataset as well as on a physical platform in a real world scenario validate our hypothesis, and we further provide in-depth qualitative analysis.
Active Object Perceiver: Recognition-guided Policy Learning for Object Searching on Mobile Robots
Jul 30, 2018
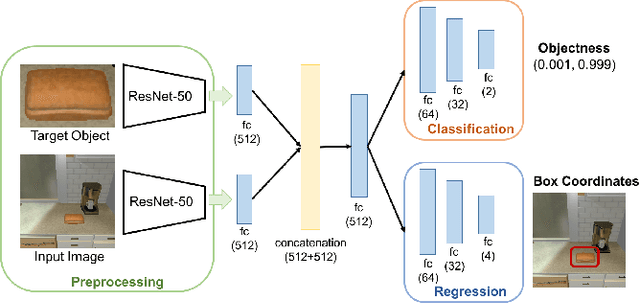
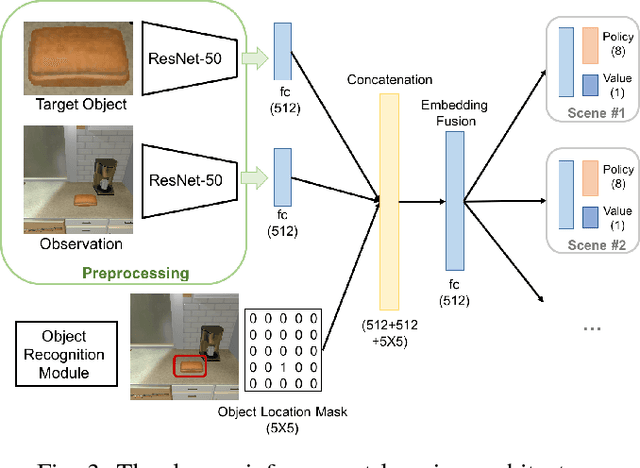
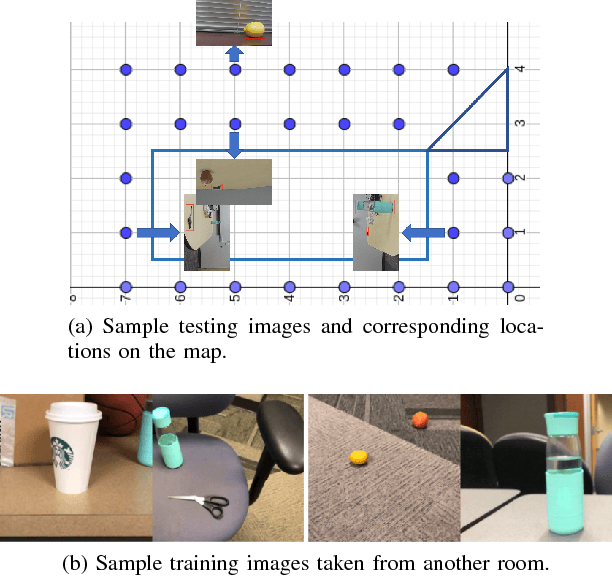
We study the problem of learning a navigation policy for a robot to actively search for an object of interest in an indoor environment solely from its visual inputs. While scene-driven visual navigation has been widely studied, prior efforts on learning navigation policies for robots to find objects are limited. The problem is often more challenging than target scene finding as the target objects can be very small in the view and can be in an arbitrary pose. We approach the problem from an active perceiver perspective, and propose a novel framework that integrates a deep neural network based object recognition module and a deep reinforcement learning based action prediction mechanism. To validate our method, we conduct experiments on both a simulation dataset (AI2-THOR) and a real-world environment with a physical robot. We further propose a new decaying reward function to learn the control policy specific to the object searching task. Experimental results validate the efficacy of our method, which outperforms competing methods in both average trajectory length and success rate.