 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiji Xin
MEWL: Few-shot multimodal word learning with referential uncertainty
Jun 01, 2023
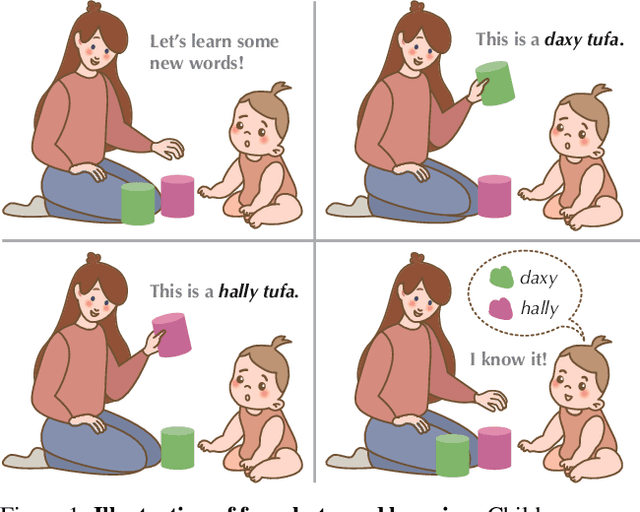

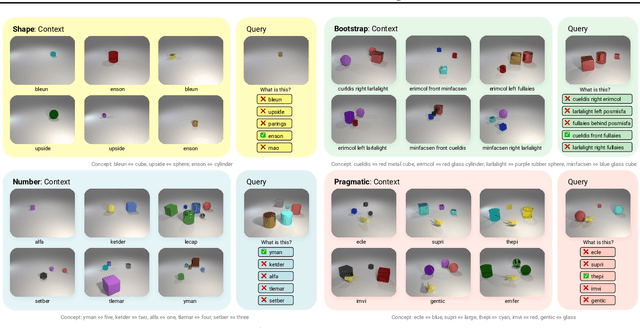
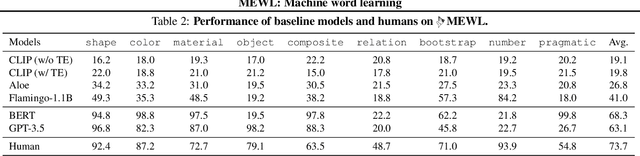
Without explicit feedback, humans can rapidly learn the meaning of words. Children can acquire a new word after just a few passive exposures, a process known as fast mapping. This word learning capability is believed to be the most fundamental building block of multimodal understanding and reasoning. Despite recent advancements in multimodal learning, a systematic and rigorous evaluation is still missing for human-like word learning in machines. To fill in this gap, we introduce the MachinE Word Learning (MEWL) benchmark to assess how machines learn word meaning in grounded visual scenes. MEWL covers human's core cognitive toolkits in word learning: cross-situational reasoning, bootstrapping, and pragmatic learning. Specifically, MEWL is a few-shot benchmark suite consisting of nine tasks for probing various word learning capabilities. These tasks are carefully designed to be aligned with the children's core abilities in word learning and echo the theories in the developmental literature. By evaluating multimodal and unimodal agents' performance with a comparative analysis of human performance, we notice a sharp divergence in human and machine word learning. We further discuss these differences between humans and machines and call for human-like few-shot word learning in machines.
On the Connection between Invariant Learning and Adversarial Training for Out-of-Distribution Generalization
Dec 18, 2022



Despite impressive success in many tasks, deep learning models are shown to rely on spurious features, which will catastrophically fail when generalized to out-of-distribution (OOD) data. Invariant Risk Minimization (IRM) is proposed to alleviate this issue by extracting domain-invariant features for OOD generalization. Nevertheless, recent work shows that IRM is only effective for a certain type of distribution shift (e.g., correlation shift) while it fails for other cases (e.g., diversity shift). Meanwhile, another thread of method, Adversarial Training (AT), has shown better domain transfer performance, suggesting that it has the potential to be an effective candidate for extracting domain-invariant features. This paper investigates this possibility by exploring the similarity between the IRM and AT objectives. Inspired by this connection, we propose Domainwise Adversarial Training (DAT), an AT-inspired method for alleviating distribution shift by domain-specific perturbations. Extensive experiments show that our proposed DAT can effectively remove domain-varying features and improve OOD generalization under both correlation shift and diversity shift.
Boosting Certified $\ell_\infty$ Robustness with EMA Method and Ensemble Model
Jul 01, 2021



The neural network with $1$-Lipschitz property based on $\ell_\infty$-dist neuron has a theoretical guarantee in certified $\ell_\infty$ robustness. However, due to the inherent difficulties in the training of the network, the certified accuracy of previous work is limited. In this paper, we propose two approaches to deal with these difficuties. Aiming at the characteristics of the training process based on $\ell_\infty$-norm neural network, we introduce the EMA method to improve the training process. Considering the randomness of the training algorithm, we propose an ensemble method based on trained base models that have the $1$-Lipschitz property and gain significant improvement in the small parameter network. Moreover, we give the theoretical analysis of the ensemble method based on the $1$-Lipschitz property on the certified robustness, which ensures the effectiveness and stability of the algorithm. Our code is available at https://github.com/Theia-4869/EMA-and-Ensemble-Lip-Networks.