 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiran Dudy
Dependency Dialogue Acts -- Annotation Scheme and Case Study
Feb 25, 2023
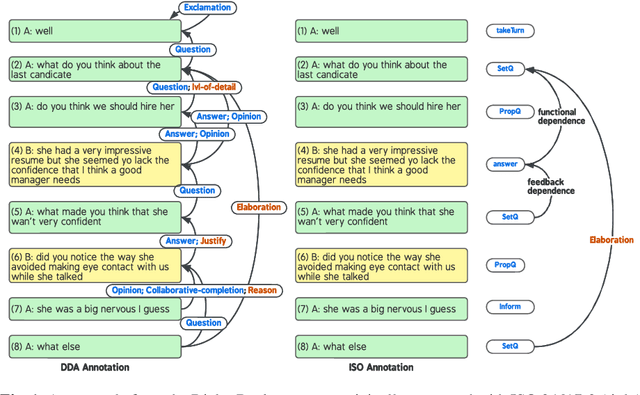

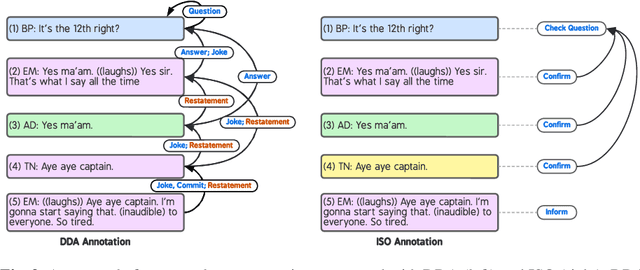
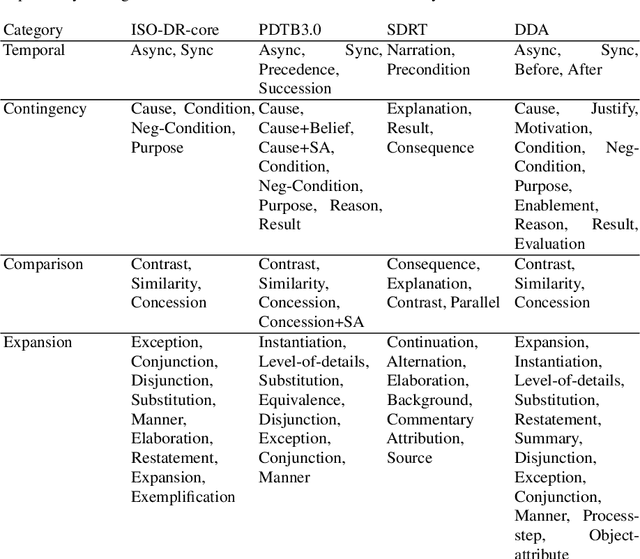
In this paper, we introduce Dependency Dialogue Acts (DDA), a novel framework for capturing the structure of speaker-intentions in multi-party dialogues. DDA combines and adapts features from existing dialogue annotation frameworks, and emphasizes the multi-relational response structure of dialogues in addition to the dialogue acts and rhetorical relations. It represents the functional, discourse, and response structure in multi-party multi-threaded conversations. A few key features distinguish DDA from existing dialogue annotation frameworks such as SWBD-DAMSL and the ISO 24617-2 standard. First, DDA prioritizes the relational structure of the dialogue units and the dialog context, annotating both dialog acts and rhetorical relations as response relations to particular utterances. Second, DDA embraces overloading in dialogues, encouraging annotators to specify multiple response relations and dialog acts for each dialog unit. Lastly, DDA places an emphasis on adequately capturing how a speaker is using the full dialog context to plan and organize their speech. With these features, DDA is highly expressive and recall-oriented with regard to conversation dynamics between multiple speakers. In what follows, we present the DDA annotation framework and case studies annotating DDA structures in multi-party, multi-threaded conversations.
* The 13th International Workshop on Spoken Dialogue Systems Technology
A Major Obstacle for NLP Research: Let's Talk about Time Allocation!
Nov 30, 2022
The field of natural language processing (NLP) has grown over the last few years: conferences have become larger, we have published an incredible amount of papers, and state-of-the-art research has been implemented in a large variety of customer-facing products. However, this paper argues that we have been less successful than we should have been and reflects on where and how the field fails to tap its full potential. Specifically, we demonstrate that, in recent years, subpar time allocation has been a major obstacle for NLP research. We outline multiple concrete problems together with their negative consequences and, importantly, suggest remedies to improve the status quo. We hope that this paper will be a starting point for discussions around which common practices are -- or are not -- beneficial for NLP research.
Expansive Participatory AI: Supporting Dreaming within Inequitable Institutions
Nov 22, 2022Participatory Artificial Intelligence (PAI) has recently gained interest by researchers as means to inform the design of technology through collective's lived experience. PAI has a greater promise than that of providing useful input to developers, it can contribute to the process of democratizing the design of technology, setting the focus on what should be designed. However, in the process of PAI there existing institutional power dynamics that hinder the realization of expansive dreams and aspirations of the relevant stakeholders. In this work we propose co-design principals for AI that address institutional power dynamics focusing on Participatory AI with youth.
* 3 pages, Human-Centered AI workshop
Refocusing on Relevance: Personalization in NLG
Sep 10, 2021Many NLG tasks such as summarization, dialogue response, or open domain question answering focus primarily on a source text in order to generate a target response. This standard approach falls short, however, when a user's intent or context of work is not easily recoverable based solely on that source text -- a scenario that we argue is more of the rule than the exception. In this work, we argue that NLG systems in general should place a much higher level of emphasis on making use of additional context, and suggest that relevance (as used in Information Retrieval) be thought of as a crucial tool for designing user-oriented text-generating tasks. We further discuss possible harms and hazards around such personalization, and argue that value-sensitive design represents a crucial path forward through these challenges.
Are Some Words Worth More than Others?
Oct 14, 2020



Current evaluation metrics for language modeling and generation rely heavily on the accuracy of predicted (or generated) words as compared to a reference ground truth. While important, token-level accuracy only captures one aspect of a language model's behavior, and ignores linguistic properties of words that may allow some mis-predicted tokens to be useful in practice. Furthermore, statistics directly tied to prediction accuracy (including perplexity) may be confounded by the Zipfian nature of written language, as the majority of the prediction attempts will occur with frequently-occurring types. A model's performance may vary greatly between high- and low-frequency words, which in practice could lead to failure modes such as repetitive and dull generated text being produced by a downstream consumer of a language model. To address this, we propose two new intrinsic evaluation measures within the framework of a simple word prediction task that are designed to give a more holistic picture of a language model's performance. We evaluate several commonly-used large English language models using our proposed metrics, and demonstrate that our approach reveals functional differences in performance between the models that are obscured by more traditional metrics.