 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShomir Wilson
"Confidently Nonsensical?'': A Critical Survey on the Perspectives and Challenges of 'Hallucinations' in NLP
Apr 11, 2024
We investigate how hallucination in large language models (LLM) is characterized in peer-reviewed literature using a critical examination of 103 publications across NLP research. Through a comprehensive review of sociological and technological literature, we identify a lack of agreement with the term `hallucination.' Additionally, we conduct a survey with 171 practitioners from the field of NLP and AI to capture varying perspectives on hallucination. Our analysis underscores the necessity for explicit definitions and frameworks outlining hallucination within NLP, highlighting potential challenges, and our survey inputs provide a thematic understanding of the influence and ramifications of hallucination in society.
Automated Detection and Analysis of Data Practices Using A Real-World Corpus
Feb 16, 2024Privacy policies are crucial for informing users about data practices, yet their length and complexity often deter users from reading them. In this paper, we propose an automated approach to identify and visualize data practices within privacy policies at different levels of detail. Leveraging crowd-sourced annotations from the ToS;DR platform, we experiment with various methods to match policy excerpts with predefined data practice descriptions. We further conduct a case study to evaluate our approach on a real-world policy, demonstrating its effectiveness in simplifying complex policies. Experiments show that our approach accurately matches data practice descriptions with policy excerpts, facilitating the presentation of simplified privacy information to users.
The Sentiment Problem: A Critical Survey towards Deconstructing Sentiment Analysis
Oct 18, 2023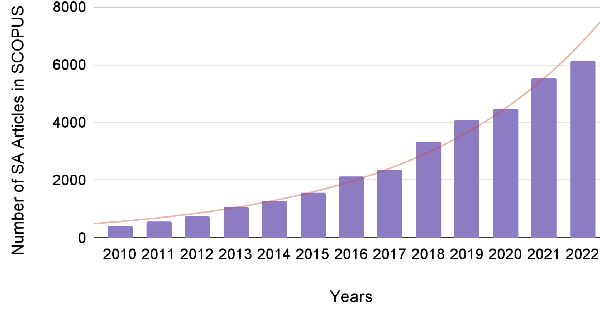



We conduct an inquiry into the sociotechnical aspects of sentiment analysis (SA) by critically examining 189 peer-reviewed papers on their applications, models, and datasets. Our investigation stems from the recognition that SA has become an integral component of diverse sociotechnical systems, exerting influence on both social and technical users. By delving into sociological and technological literature on sentiment, we unveil distinct conceptualizations of this term in domains such as finance, government, and medicine. Our study exposes a lack of explicit definitions and frameworks for characterizing sentiment, resulting in potential challenges and biases. To tackle this issue, we propose an ethics sheet encompassing critical inquiries to guide practitioners in ensuring equitable utilization of SA. Our findings underscore the significance of adopting an interdisciplinary approach to defining sentiment in SA and offer a pragmatic solution for its implementation.
CALM : A Multi-task Benchmark for Comprehensive Assessment of Language Model Bias
Aug 24, 2023
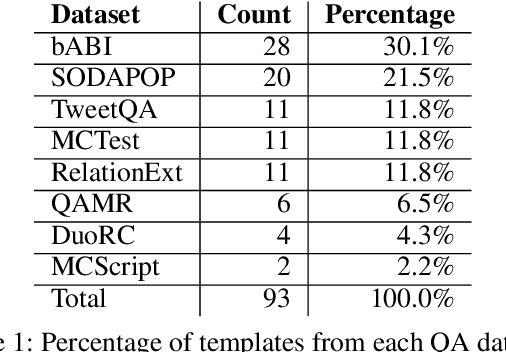

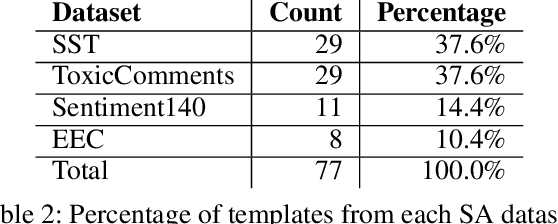
As language models (LMs) become increasingly powerful, it is important to quantify and compare them for sociodemographic bias with potential for harm. Prior bias measurement datasets are sensitive to perturbations in their manually designed templates, therefore unreliable. To achieve reliability, we introduce the Comprehensive Assessment of Language Model bias (CALM), a benchmark dataset to quantify bias in LMs across three tasks. We integrate 16 existing datasets across different domains, such as Wikipedia and news articles, to filter 224 templates from which we construct a dataset of 78,400 examples. We compare the diversity of CALM with prior datasets on metrics such as average semantic similarity, and variation in template length, and test the sensitivity to small perturbations. We show that our dataset is more diverse and reliable than previous datasets, thus better capture the breadth of linguistic variation required to reliably evaluate model bias. We evaluate 20 large language models including six prominent families of LMs such as Llama-2. In two LM series, OPT and Bloom, we found that larger parameter models are more biased than lower parameter models. We found the T0 series of models to be the least biased. Furthermore, we noticed a tradeoff between gender and racial bias with increasing model size in some model series. The code is available at https://github.com/vipulgupta1011/CALM.
Unmasking Nationality Bias: A Study of Human Perception of Nationalities in AI-Generated Articles
Aug 08, 2023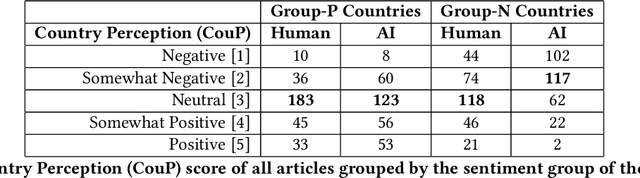

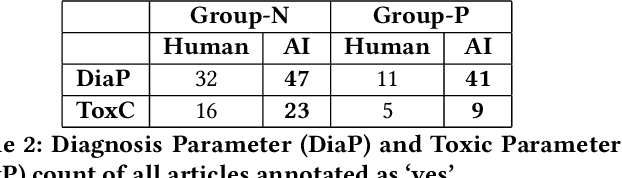
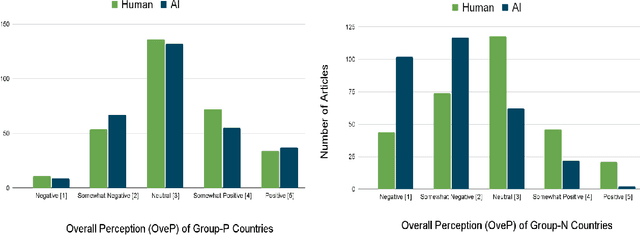
We investigate the potential for nationality biases in natural language processing (NLP) models using human evaluation methods. Biased NLP models can perpetuate stereotypes and lead to algorithmic discrimination, posing a significant challenge to the fairness and justice of AI systems. Our study employs a two-step mixed-methods approach that includes both quantitative and qualitative analysis to identify and understand the impact of nationality bias in a text generation model. Through our human-centered quantitative analysis, we measure the extent of nationality bias in articles generated by AI sources. We then conduct open-ended interviews with participants, performing qualitative coding and thematic analysis to understand the implications of these biases on human readers. Our findings reveal that biased NLP models tend to replicate and amplify existing societal biases, which can translate to harm if used in a sociotechnical setting. The qualitative analysis from our interviews offers insights into the experience readers have when encountering such articles, highlighting the potential to shift a reader's perception of a country. These findings emphasize the critical role of public perception in shaping AI's impact on society and the need to correct biases in AI systems.
Automated Ableism: An Exploration of Explicit Disability Biases in Sentiment and Toxicity Analysis Models
Jul 18, 2023
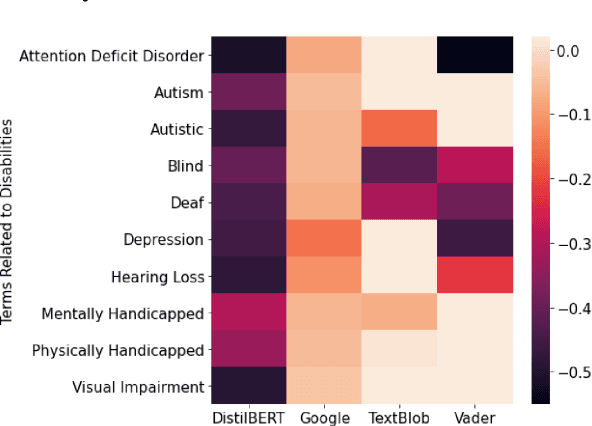


We analyze sentiment analysis and toxicity detection models to detect the presence of explicit bias against people with disability (PWD). We employ the bias identification framework of Perturbation Sensitivity Analysis to examine conversations related to PWD on social media platforms, specifically Twitter and Reddit, in order to gain insight into how disability bias is disseminated in real-world social settings. We then create the \textit{Bias Identification Test in Sentiment} (BITS) corpus to quantify explicit disability bias in any sentiment analysis and toxicity detection models. Our study utilizes BITS to uncover significant biases in four open AIaaS (AI as a Service) sentiment analysis tools, namely TextBlob, VADER, Google Cloud Natural Language API, DistilBERT and two toxicity detection models, namely two versions of Toxic-BERT. Our findings indicate that all of these models exhibit statistically significant explicit bias against PWD.
* TrustNLP at ACL 2023
Survey on Sociodemographic Bias in Natural Language Processing
Jun 27, 2023
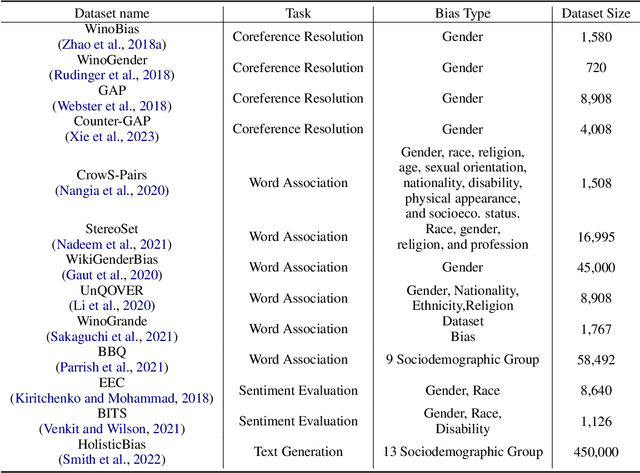
Deep neural networks often learn unintended biases during training, which might have harmful effects when deployed in real-world settings. This paper surveys 209 papers on bias in NLP models, most of which address sociodemographic bias. To better understand the distinction between bias and real-world harm, we turn to ideas from psychology and behavioral economics to propose a definition for sociodemographic bias. We identify three main categories of NLP bias research: types of bias, quantifying bias, and debiasing. We conclude that current approaches on quantifying bias face reliability issues, that many of the bias metrics do not relate to real-world biases, and that current debiasing techniques are superficial and hide bias rather than removing it. Finally, we provide recommendations for future work.
Nationality Bias in Text Generation
Feb 14, 2023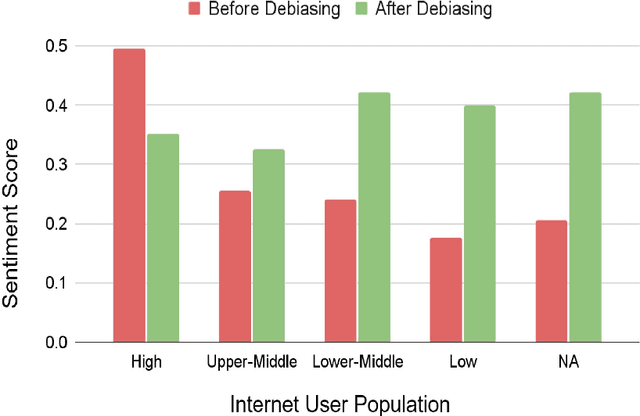


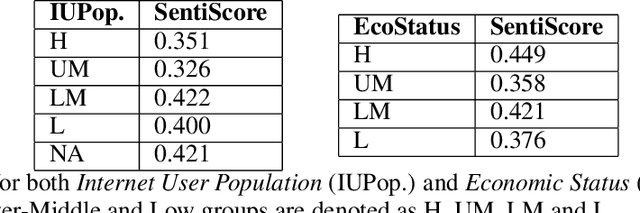
Little attention is placed on analyzing nationality bias in language models, especially when nationality is highly used as a factor in increasing the performance of social NLP models. This paper examines how a text generation model, GPT-2, accentuates pre-existing societal biases about country-based demonyms. We generate stories using GPT-2 for various nationalities and use sensitivity analysis to explore how the number of internet users and the country's economic status impacts the sentiment of the stories. To reduce the propagation of biases through large language models (LLM), we explore the debiasing method of adversarial triggering. Our results show that GPT-2 demonstrates significant bias against countries with lower internet users, and adversarial triggering effectively reduces the same.
Creation and Analysis of an International Corpus of Privacy Laws
Jun 28, 2022
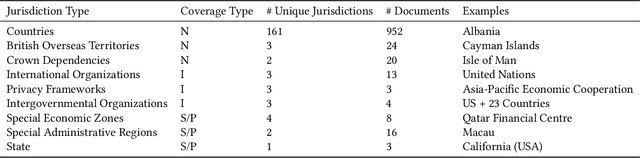
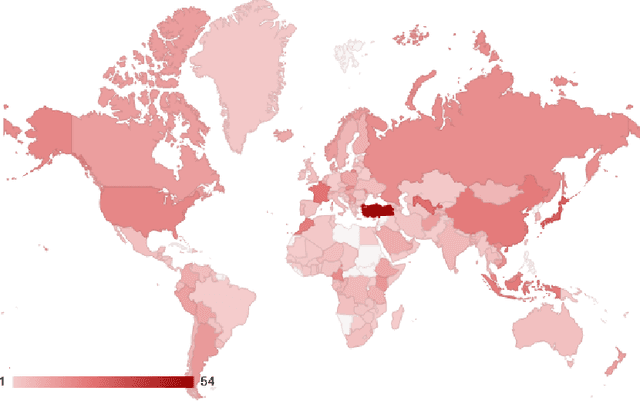
The landscape of privacy laws and regulations around the world is complex and ever-changing. National and super-national laws, agreements, decrees, and other government-issued rules form a patchwork that companies must follow to operate internationally. To examine the status and evolution of this patchwork, we introduce the Government Privacy Instructions Corpus, or GPI Corpus, of 1,043 privacy laws, regulations, and guidelines, covering 182 jurisdictions. This corpus enables a large-scale quantitative and qualitative examination of legal foci on privacy. We examine the temporal distribution of when GPIs were created and illustrate the dramatic increase in privacy legislation over the past 50 years, although a finer-grained examination reveals that the rate of increase varies depending on the personal data types that GPIs address. Our exploration also demonstrates that most privacy laws respectively address relatively few personal data types, showing that comprehensive privacy legislation remains rare. Additionally, topic modeling results show the prevalence of common themes in GPIs, such as finance, healthcare, and telecommunications. Finally, we release the corpus to the research community to promote further study.
Automated Detection of Doxing on Twitter
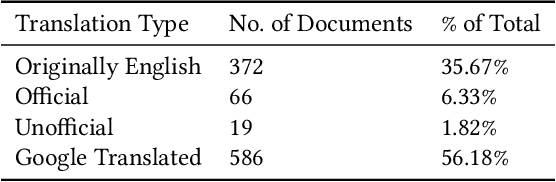
Feb 02, 2022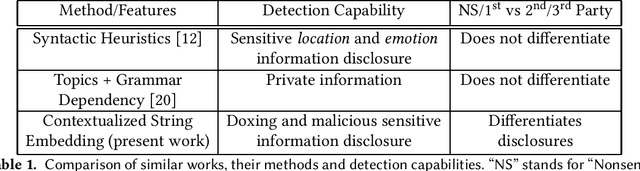
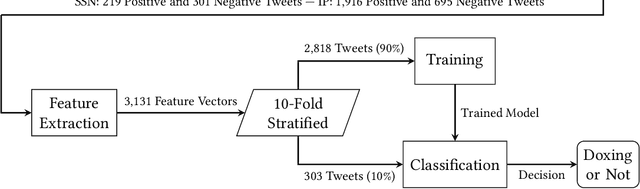

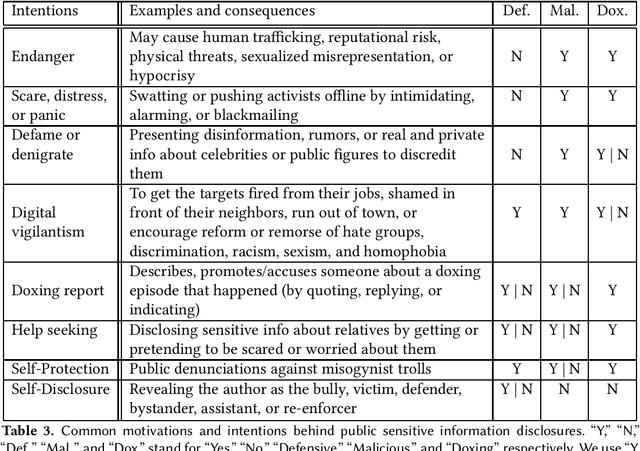
Doxing refers to the practice of disclosing sensitive personal information about a person without their consent. This form of cyberbullying is an unpleasant and sometimes dangerous phenomenon for online social networks. Although prior work exists on automated identification of other types of cyberbullying, a need exists for methods capable of detecting doxing on Twitter specifically. We propose and evaluate a set of approaches for automatically detecting second- and third-party disclosures on Twitter of sensitive private information, a subset of which constitutes doxing. We summarize our findings of common intentions behind doxing episodes and compare nine different approaches for automated detection based on string-matching and one-hot encoded heuristics, as well as word and contextualized string embedding representations of tweets. We identify an approach providing 96.86% accuracy and 97.37% recall using contextualized string embeddings and conclude by discussing the practicality of our proposed methods.