 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShreyas Chaudhari
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Apr 12, 2024
State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
Gradient Networks
Apr 10, 2024Directly parameterizing and learning gradients of functions has widespread significance, with specific applications in optimization, generative modeling, and optimal transport. This paper introduces gradient networks (GradNets): novel neural network architectures that parameterize gradients of various function classes. GradNets exhibit specialized architectural constraints that ensure correspondence to gradient functions. We provide a comprehensive GradNet design framework that includes methods for transforming GradNets into monotone gradient networks (mGradNets), which are guaranteed to represent gradients of convex functions. We establish the approximation capabilities of the proposed GradNet and mGradNet. Our results demonstrate that these networks universally approximate the gradients of (convex) functions. Furthermore, these networks can be customized to correspond to specific spaces of (monotone) gradient functions, including gradients of transformed sums of (convex) ridge functions. Our analysis leads to two distinct GradNet architectures, GradNet-C and GradNet-M, and we describe the corresponding monotone versions, mGradNet-C and mGradNet-M. Our empirical results show that these architectures offer efficient parameterizations and outperform popular methods in gradient field learning tasks.
From Past to Future: Rethinking Eligibility Traces
Dec 20, 2023In this paper, we introduce a fresh perspective on the challenges of credit assignment and policy evaluation. First, we delve into the nuances of eligibility traces and explore instances where their updates may result in unexpected credit assignment to preceding states. From this investigation emerges the concept of a novel value function, which we refer to as the \emph{bidirectional value function}. Unlike traditional state value functions, bidirectional value functions account for both future expected returns (rewards anticipated from the current state onward) and past expected returns (cumulative rewards from the episode's start to the present). We derive principled update equations to learn this value function and, through experimentation, demonstrate its efficacy in enhancing the process of policy evaluation. In particular, our results indicate that the proposed learning approach can, in certain challenging contexts, perform policy evaluation more rapidly than TD($\lambda$) -- a method that learns forward value functions, $v^\pi$, \emph{directly}. Overall, our findings present a new perspective on eligibility traces and potential advantages associated with the novel value function it inspires, especially for policy evaluation.
Distributional Off-Policy Evaluation for Slate Recommendations
Aug 27, 2023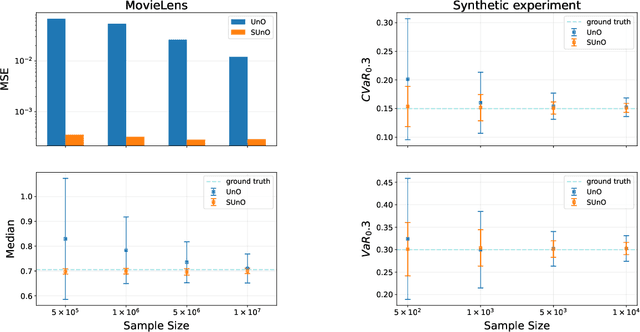
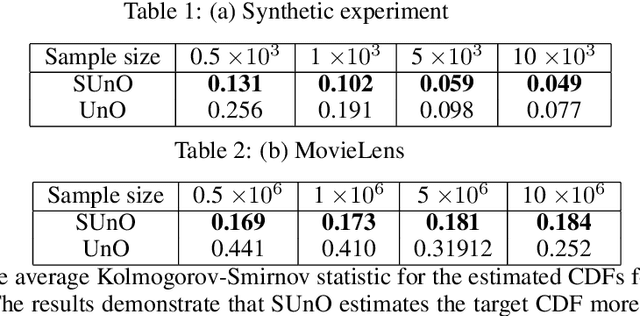

Recommendation strategies are typically evaluated by using previously logged data, employing off-policy evaluation methods to estimate their expected performance. However, for strategies that present users with slates of multiple items, the resulting combinatorial action space renders many of these methods impractical. Prior work has developed estimators that leverage the structure in slates to estimate the expected off-policy performance, but the estimation of the entire performance distribution remains elusive. Estimating the complete distribution allows for a more comprehensive evaluation of recommendation strategies, particularly along the axes of risk and fairness that employ metrics computable from the distribution. In this paper, we propose an estimator for the complete off-policy performance distribution for slates and establish conditions under which the estimator is unbiased and consistent. This builds upon prior work on off-policy evaluation for slates and off-policy distribution estimation in reinforcement learning. We validate the efficacy of our method empirically on synthetic data as well as on a slate recommendation simulator constructed from real-world data (MovieLens-20M). Our results show a significant reduction in estimation variance and improved sample efficiency over prior work across a range of slate structures.
Learning Gradients of Convex Functions with Monotone Gradient Networks
Jan 25, 2023
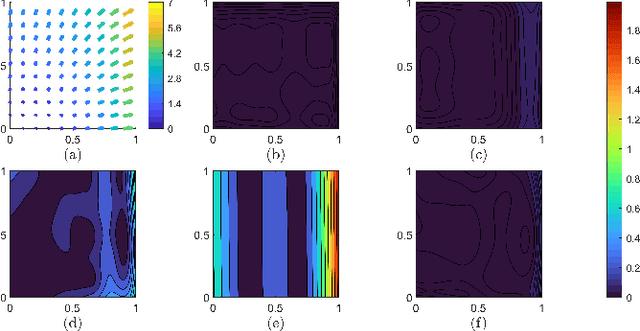
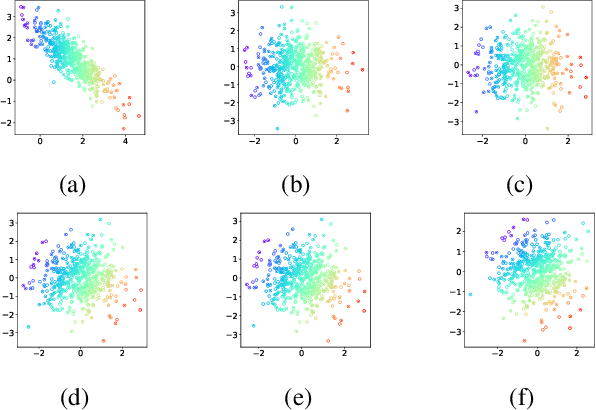
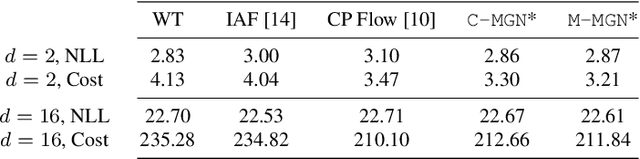
While much effort has been devoted to deriving and studying effective convex formulations of signal processing problems, the gradients of convex functions also have critical applications ranging from gradient-based optimization to optimal transport. Recent works have explored data-driven methods for learning convex objectives, but learning their monotone gradients is seldom studied. In this work, we propose Cascaded and Modular Monotone Gradient Networks (C-MGN and M-MGN respectively), two monotone gradient neural network architectures for directly learning the gradients of convex functions. We show that our networks are simpler to train, learn monotone gradient fields more accurately, and use significantly fewer parameters than state of the art methods. We further demonstrate their ability to learn optimal transport mappings to augment driving image data.
High-Resolution CMB Lensing Reconstruction with Deep Learning
May 15, 2022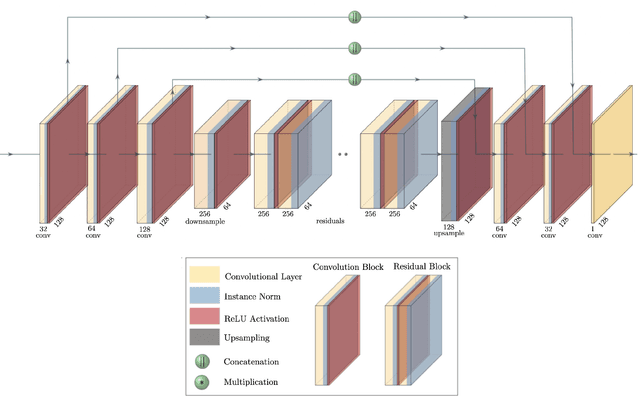
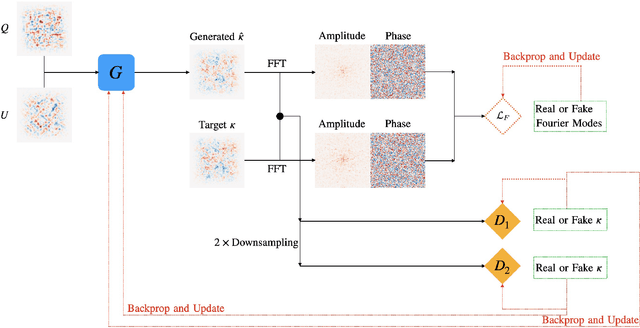
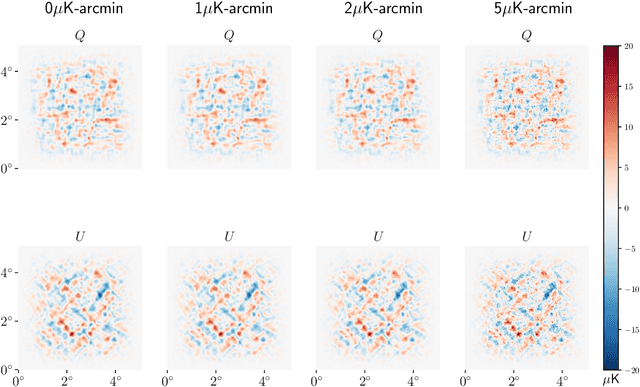
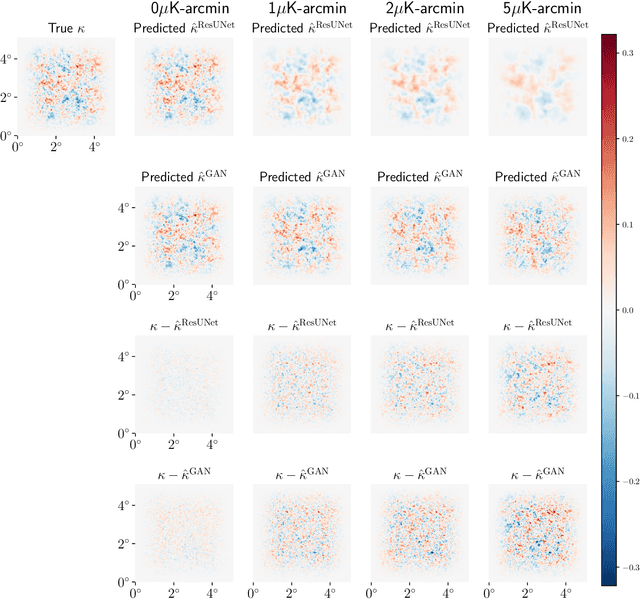
Next-generation cosmic microwave background (CMB) surveys are expected to provide valuable information about the primordial universe by creating maps of the mass along the line of sight. Traditional tools for creating these lensing convergence maps include the quadratic estimator and the maximum likelihood based iterative estimator. Here, we apply a generative adversarial network (GAN) to reconstruct the lensing convergence field. We compare our results with a previous deep learning approach -- Residual-UNet -- and discuss the pros and cons of each. In the process, we use training sets generated by a variety of power spectra, rather than the one used in testing the methods.
Unsupervised Clustering of Time Series Signals using Neuromorphic Energy-Efficient Temporal Neural Networks
Feb 18, 2021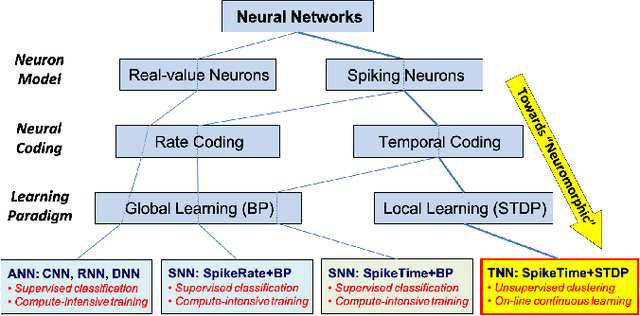
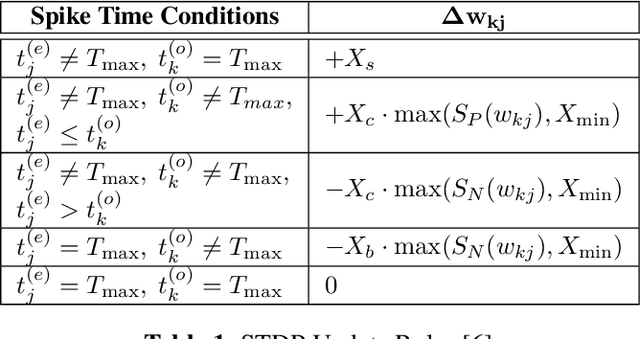
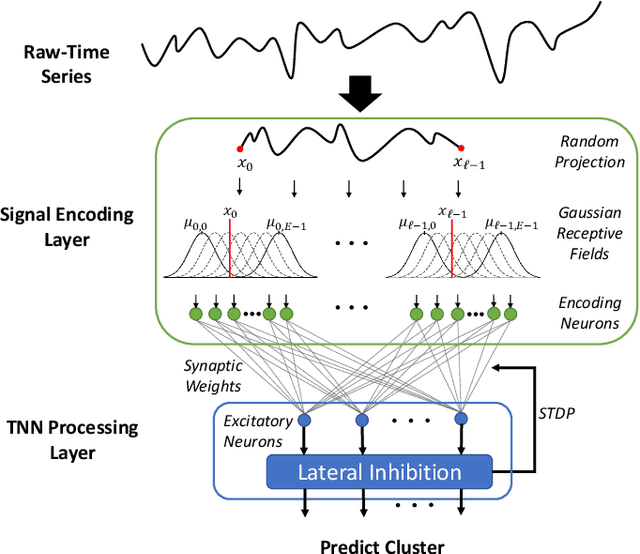
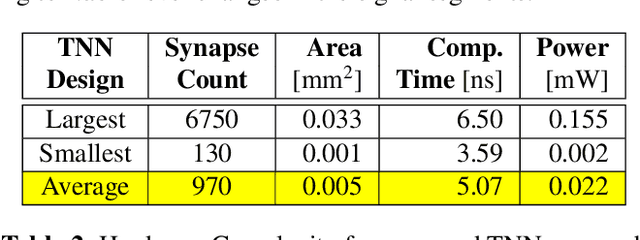
Unsupervised time series clustering is a challenging problem with diverse industrial applications such as anomaly detection, bio-wearables, etc. These applications typically involve small, low-power devices on the edge that collect and process real-time sensory signals. State-of-the-art time-series clustering methods perform some form of loss minimization that is extremely computationally intensive from the perspective of edge devices. In this work, we propose a neuromorphic approach to unsupervised time series clustering based on Temporal Neural Networks that is capable of ultra low-power, continuous online learning. We demonstrate its clustering performance on a subset of UCR Time Series Archive datasets. Our results show that the proposed approach either outperforms or performs similarly to most of the existing algorithms while being far more amenable for efficient hardware implementation. Our hardware assessment analysis shows that in 7 nm CMOS the proposed architecture, on average, consumes only about 0.005 mm^2 die area and 22 uW power and can process each signal with about 5 ns latency.
Off-Dynamics Reinforcement Learning: Training for Transfer with Domain Classifiers
Jun 24, 2020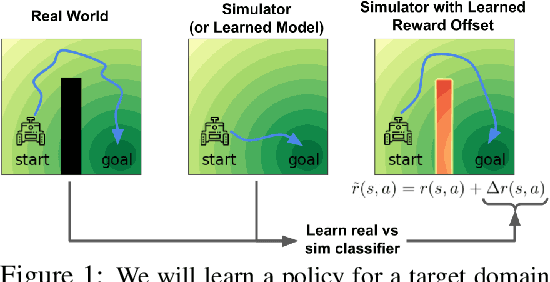
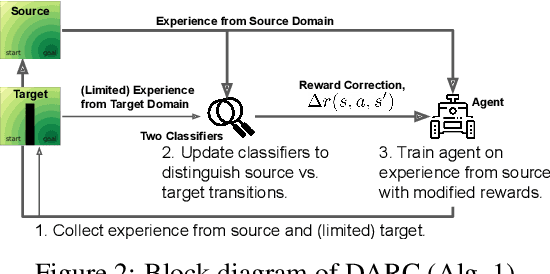
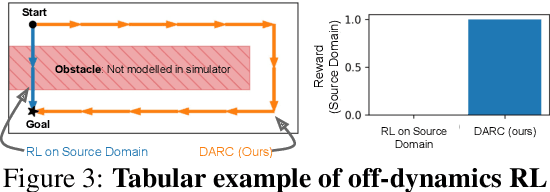
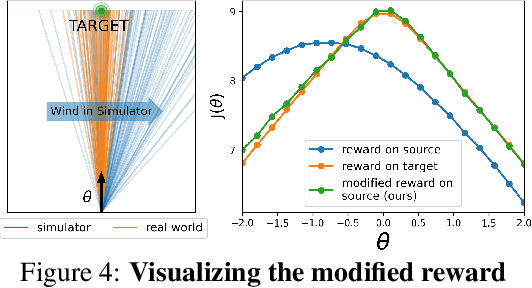
We propose a simple, practical, and intuitive approach for domain adaptation in reinforcement learning. Our approach stems from the idea that the agent's experience in the source domain should look similar to its experience in the target domain. Building off of a probabilistic view of RL, we formally show that we can achieve this goal by compensating for the difference in dynamics by modifying the reward function. This modified reward function is simple to estimate by learning auxiliary classifiers that distinguish source-domain transitions from target-domain transitions. Intuitively, the modified reward function penalizes the agent for visiting states and taking actions in the source domain which are not possible in the target domain. Said another way, the agent is penalized for transitions that would indicate that the agent is interacting with the source domain, rather than the target domain. Our approach is applicable to domains with continuous states and actions and does not require learning an explicit model of the dynamics. On discrete and continuous control tasks, we illustrate the mechanics of our approach and demonstrate its scalability to high-dimensional tasks.
Multi-Armed Bandits with Correlated Arms
Dec 03, 2019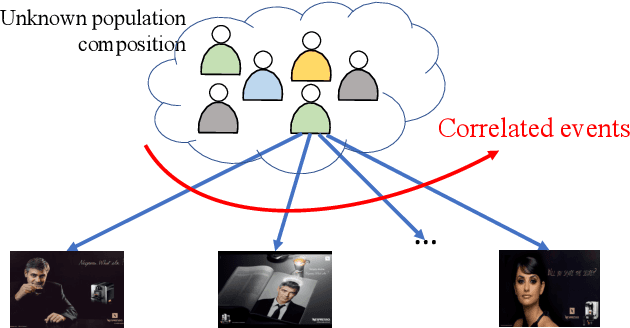

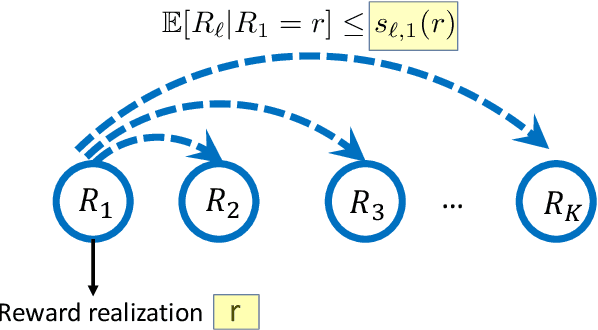
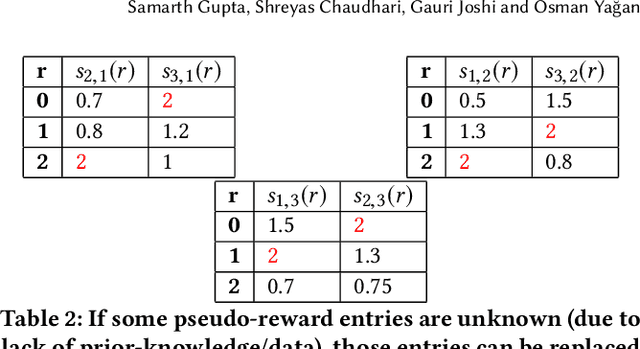
We consider a multi-armed bandit framework where the rewards obtained by pulling different arms are correlated. The correlation information is captured in terms of \textit{pseudo-rewards}, which are bounds on the rewards on the other arm given a reward realization and can capture many general correlation structures. We leverage these pseudo-rewards to design a novel approach that extends any classical bandit algorithm to the correlated multi-armed bandit setting studied in the framework. In each round, our proposed C-Bandit algorithm identifies some arms as empirically non-competitive, and avoids exploring them for that round. Through a unified regret analysis of the proposed C-Bandit algorithm, we show that C-UCB and C-TS (the correlated bandit versions of Upper-confidence-bound and Thompson sampling) pull certain arms called non-competitive arms, only O(1) times. As a result, we effectively reduce a $K$-armed bandit problem to a $C+1$-armed bandit problem, where $C$ is the number of competitive arms, as only $C$ sub-optimal arms are pulled O(log T) times. In many practical scenarios, $C$ can be zero due to which our proposed C-Bandit algorithms achieve bounded regret. In the special case where rewards are correlated through a latent random variable $X$, we give a regret lower bound that shows that bounded regret is possible only when $C = 0$. In addition to simulations, we validate the proposed algorithms via experiments on two real-world recommendation datasets, movielens and goodreads, and show that C-UCB and C-TS significantly outperform classical bandit algorithms.