 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuhao Chen
Large Language Models as Visual Cross-Domain Learners
Jan 06, 2024
Recent advances achieved by deep learning models rely on the independent and identically distributed assumption, hindering their applications in real-world scenarios with domain shifts. To address the above issues, cross-domain learning aims at extracting domain-invariant knowledge to reduce the domain shift between training and testing data. However, in visual cross-domain learning, traditional methods concentrate solely on the image modality, neglecting the use of the text modality to alleviate the domain shift. In this work, we propose Large Language models as Visual cross-dOmain learners (LLaVO). LLaVO uses vision-language models to convert images into detailed textual descriptions. A large language model is then finetuned on textual descriptions of the source/target domain generated by a designed instruction template. Extensive experimental results on various cross-domain tasks under the domain generalization and unsupervised domain adaptation settings have demonstrated the effectiveness of the proposed method.
Domain-Guided Conditional Diffusion Model for Unsupervised Domain Adaptation
Sep 23, 2023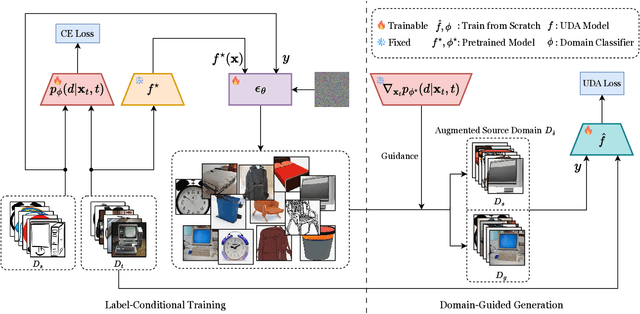
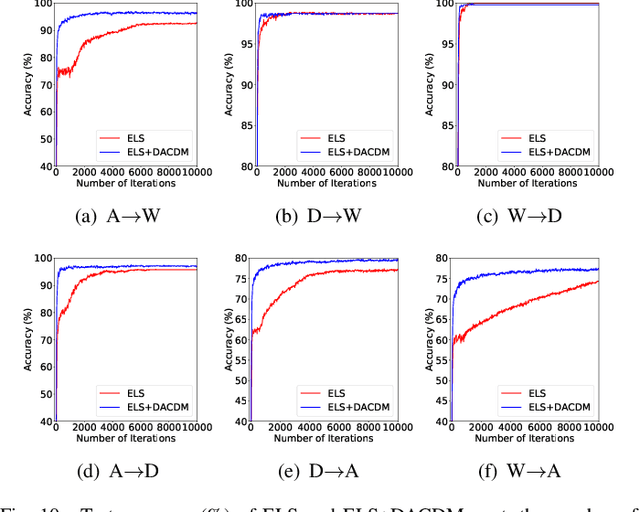
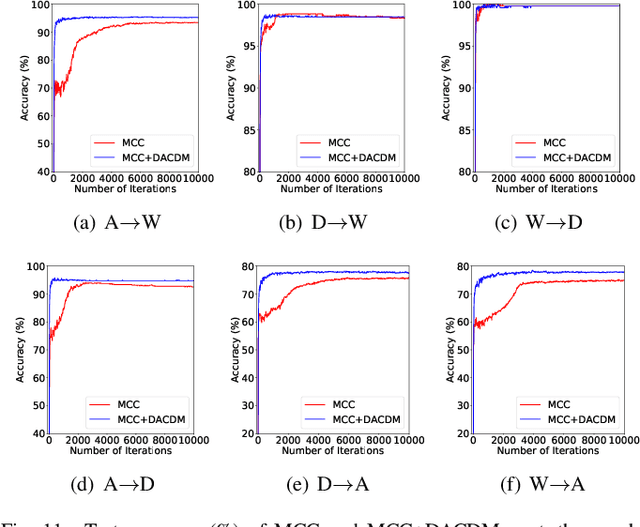
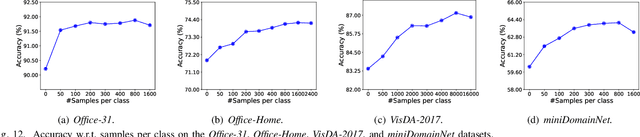
Limited transferability hinders the performance of deep learning models when applied to new application scenarios. Recently, Unsupervised Domain Adaptation (UDA) has achieved significant progress in addressing this issue via learning domain-invariant features. However, the performance of existing UDA methods is constrained by the large domain shift and limited target domain data. To alleviate these issues, we propose DomAin-guided Conditional Diffusion Model (DACDM) to generate high-fidelity and diversity samples for the target domain. In the proposed DACDM, by introducing class information, the labels of generated samples can be controlled, and a domain classifier is further introduced in DACDM to guide the generated samples for the target domain. The generated samples help existing UDA methods transfer from the source domain to the target domain more easily, thus improving the transfer performance. Extensive experiments on various benchmarks demonstrate that DACDM brings a large improvement to the performance of existing UDA methods.
Diffusion-based Target Sampler for Unsupervised Domain Adaptation
Mar 17, 2023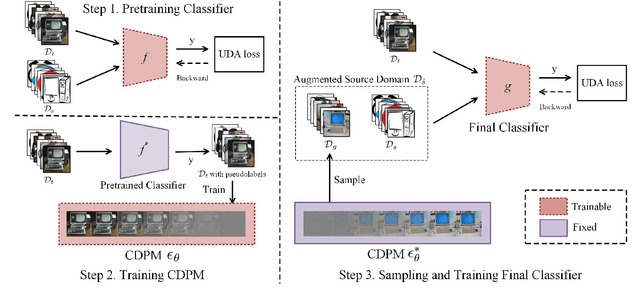
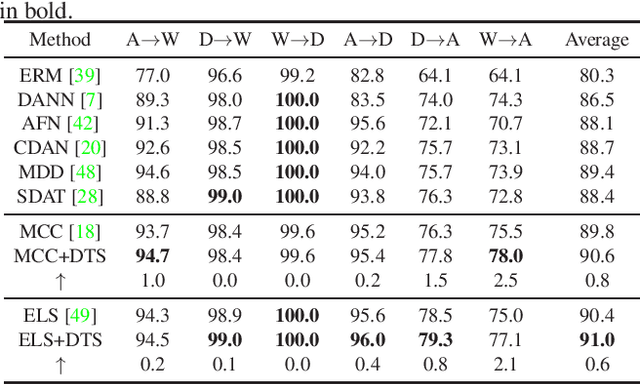
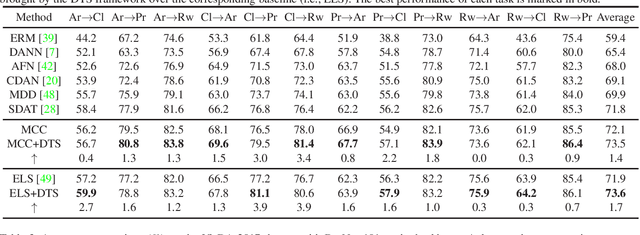

Limited transferability hinders the performance of deep learning models when applied to new application scenarios. Recently, unsupervised domain adaptation (UDA) has achieved significant progress in addressing this issue via learning domain-invariant features. However, large domain shifts and the sample scarcity in the target domain make existing UDA methods achieve suboptimal performance. To alleviate these issues, we propose a plug-and-play Diffusion-based Target Sampler (DTS) to generate high fidelity and diversity pseudo target samples. By introducing class-conditional information, the labels of the generated target samples can be controlled. The generated samples can well simulate the data distribution of the target domain and help existing UDA methods transfer from the source domain to the target domain more easily, thus improving the transfer performance. Extensive experiments on various benchmarks demonstrate that the performance of existing UDA methods can be greatly improved through the proposed DTS method.