 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuo Han
Covert Planning against Imperfect Observers
Nov 01, 2023
Covert planning refers to a class of constrained planning problems where an agent aims to accomplish a task with minimal information leaked to a passive observer to avoid detection. However, existing methods of covert planning often consider deterministic environments or do not exploit the observer's imperfect information. This paper studies how covert planning can leverage the coupling of stochastic dynamics and the observer's imperfect observation to achieve optimal task performance without being detected. Specifically, we employ a Markov decision process to model the interaction between the agent and its stochastic environment, and a partial observation function to capture the leaked information to a passive observer. Assuming the observer employs hypothesis testing to detect if the observation deviates from a nominal policy, the covert planning agent aims to maximize the total discounted reward while keeping the probability of being detected as an adversary below a given threshold. We prove that finite-memory policies are more powerful than Markovian policies in covert planning. Then, we develop a primal-dual proximal policy gradient method with a two-time-scale update to compute a (locally) optimal covert policy. We demonstrate the effectiveness of our methods using a stochastic gridworld example. Our experimental results illustrate that the proposed method computes a policy that maximizes the adversary's expected reward without violating the detection constraint, and empirically demonstrates how the environmental noises can influence the performance of the covert policies.
LoMAE: Low-level Vision Masked Autoencoders for Low-dose CT Denoising
Oct 19, 2023Low-dose computed tomography (LDCT) offers reduced X-ray radiation exposure but at the cost of compromised image quality, characterized by increased noise and artifacts. Recently, transformer models emerged as a promising avenue to enhance LDCT image quality. However, the success of such models relies on a large amount of paired noisy and clean images, which are often scarce in clinical settings. In the fields of computer vision and natural language processing, masked autoencoders (MAE) have been recognized as an effective label-free self-pretraining method for transformers, due to their exceptional feature representation ability. However, the original pretraining and fine-tuning design fails to work in low-level vision tasks like denoising. In response to this challenge, we redesign the classical encoder-decoder learning model and facilitate a simple yet effective low-level vision MAE, referred to as LoMAE, tailored to address the LDCT denoising problem. Moreover, we introduce an MAE-GradCAM method to shed light on the latent learning mechanisms of the MAE/LoMAE. Additionally, we explore the LoMAE's robustness and generability across a variety of noise levels. Experiments results show that the proposed LoMAE can enhance the transformer's denoising performance and greatly relieve the dependence on the ground truth clean data. It also demonstrates remarkable robustness and generalizability over a spectrum of noise levels.
Psychoacoustic Challenges Of Speech Enhancement On VoIP Platforms
Oct 11, 2023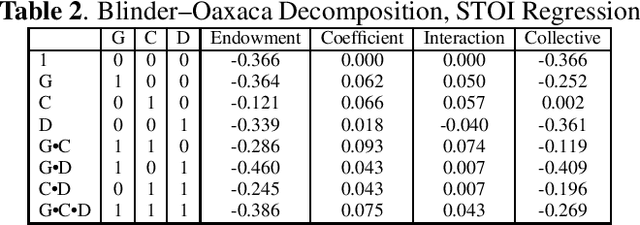
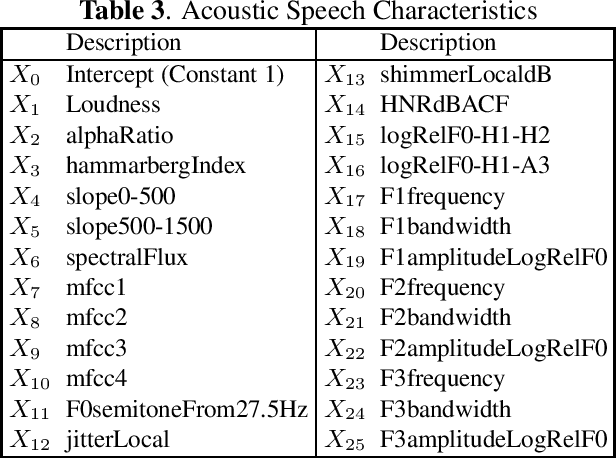

Within the ambit of VoIP (Voice over Internet Protocol) telecommunications, the complexities introduced by acoustic transformations merit rigorous analysis. This research, rooted in the exploration of proprietary sender-side denoising effects, meticulously evaluates platforms such as Google Meets and Zoom. The study draws upon the Deep Noise Suppression (DNS) 2020 dataset, ensuring a structured examination tailored to various denoising settings and receiver interfaces. A methodological novelty is introduced via the Oaxaca decomposition, traditionally an econometric tool, repurposed herein to analyze acoustic-phonetic perturbations within VoIP systems. To further ground the implications of these transformations, psychoacoustic metrics, specifically PESQ and STOI, were harnessed to furnish a comprehensive understanding of speech alterations. Cumulatively, the insights garnered underscore the intricate landscape of VoIP-influenced acoustic dynamics. In addition to the primary findings, a multitude of metrics are reported, extending the research purview. Moreover, out-of-domain benchmarking for both time and time-frequency domain speech enhancement models is included, thereby enhancing the depth and applicability of this inquiry.
Robust Electric Vehicle Balancing of Autonomous Mobility-On-Demand System: A Multi-Agent Reinforcement Learning Approach
Jul 30, 2023



Electric autonomous vehicles (EAVs) are getting attention in future autonomous mobility-on-demand (AMoD) systems due to their economic and societal benefits. However, EAVs' unique charging patterns (long charging time, high charging frequency, unpredictable charging behaviors, etc.) make it challenging to accurately predict the EAVs supply in E-AMoD systems. Furthermore, the mobility demand's prediction uncertainty makes it an urgent and challenging task to design an integrated vehicle balancing solution under supply and demand uncertainties. Despite the success of reinforcement learning-based E-AMoD balancing algorithms, state uncertainties under the EV supply or mobility demand remain unexplored. In this work, we design a multi-agent reinforcement learning (MARL)-based framework for EAVs balancing in E-AMoD systems, with adversarial agents to model both the EAVs supply and mobility demand uncertainties that may undermine the vehicle balancing solutions. We then propose a robust E-AMoD Balancing MARL (REBAMA) algorithm to train a robust EAVs balancing policy to balance both the supply-demand ratio and charging utilization rate across the whole city. Experiments show that our proposed robust method performs better compared with a non-robust MARL method that does not consider state uncertainties; it improves the reward, charging utilization fairness, and supply-demand fairness by 19.28%, 28.18%, and 3.97%, respectively. Compared with a robust optimization-based method, the proposed MARL algorithm can improve the reward, charging utilization fairness, and supply-demand fairness by 8.21%, 8.29%, and 9.42%, respectively.
Robust Multi-Agent Reinforcement Learning with State Uncertainty
Jul 30, 2023

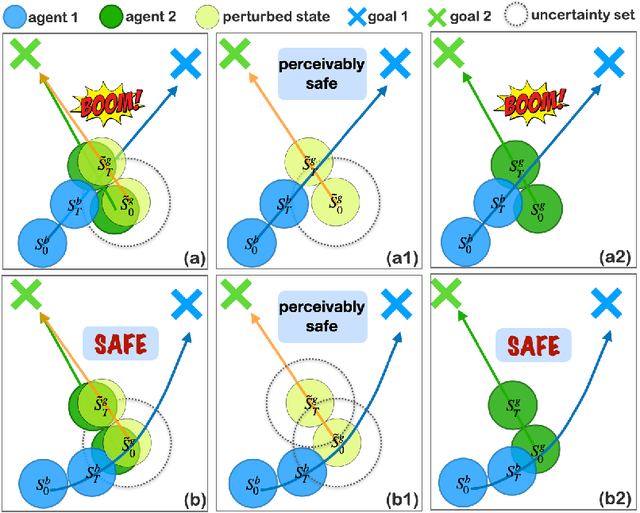

In real-world multi-agent reinforcement learning (MARL) applications, agents may not have perfect state information (e.g., due to inaccurate measurement or malicious attacks), which challenges the robustness of agents' policies. Though robustness is getting important in MARL deployment, little prior work has studied state uncertainties in MARL, neither in problem formulation nor algorithm design. Motivated by this robustness issue and the lack of corresponding studies, we study the problem of MARL with state uncertainty in this work. We provide the first attempt to the theoretical and empirical analysis of this challenging problem. We first model the problem as a Markov Game with state perturbation adversaries (MG-SPA) by introducing a set of state perturbation adversaries into a Markov Game. We then introduce robust equilibrium (RE) as the solution concept of an MG-SPA. We conduct a fundamental analysis regarding MG-SPA such as giving conditions under which such a robust equilibrium exists. Then we propose a robust multi-agent Q-learning (RMAQ) algorithm to find such an equilibrium, with convergence guarantees. To handle high-dimensional state-action space, we design a robust multi-agent actor-critic (RMAAC) algorithm based on an analytical expression of the policy gradient derived in the paper. Our experiments show that the proposed RMAQ algorithm converges to the optimal value function; our RMAAC algorithm outperforms several MARL and robust MARL methods in multiple multi-agent environments when state uncertainty is present. The source code is public on \url{https://github.com/sihongho/robust_marl_with_state_uncertainty}.
Transforming Graphs for Enhanced Attribute-Based Clustering: An Innovative Graph Transformer Method
Jun 21, 2023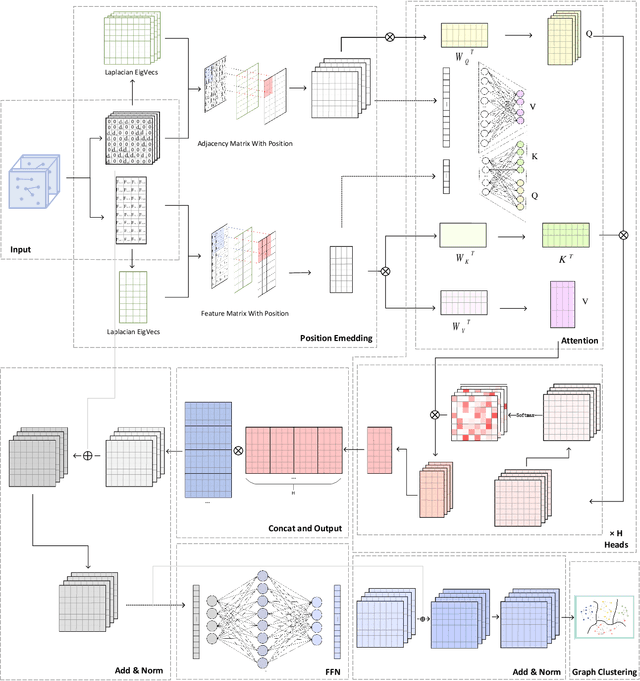

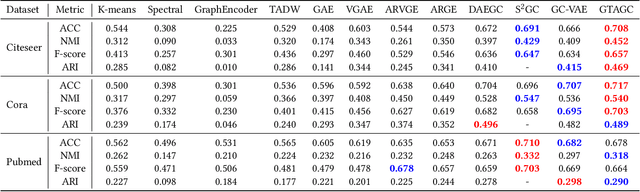

Graph Representation Learning (GRL) is an influential methodology, enabling a more profound understanding of graph-structured data and aiding graph clustering, a critical task across various domains. The recent incursion of attention mechanisms, originally an artifact of Natural Language Processing (NLP), into the realm of graph learning has spearheaded a notable shift in research trends. Consequently, Graph Attention Networks (GATs) and Graph Attention Auto-Encoders have emerged as preferred tools for graph clustering tasks. Yet, these methods primarily employ a local attention mechanism, thereby curbing their capacity to apprehend the intricate global dependencies between nodes within graphs. Addressing these impediments, this study introduces an innovative method known as the Graph Transformer Auto-Encoder for Graph Clustering (GTAGC). By melding the Graph Auto-Encoder with the Graph Transformer, GTAGC is adept at capturing global dependencies between nodes. This integration amplifies the graph representation and surmounts the constraints posed by the local attention mechanism. The architecture of GTAGC encompasses graph embedding, integration of the Graph Transformer within the autoencoder structure, and a clustering component. It strategically alternates between graph embedding and clustering, thereby tailoring the Graph Transformer for clustering tasks, whilst preserving the graph's global structural information. Through extensive experimentation on diverse benchmark datasets, GTAGC has exhibited superior performance against existing state-of-the-art graph clustering methodologies. This pioneering approach represents a novel contribution to the field of graph clustering, paving the way for promising avenues in future research.
Rapid Brain Meninges Surface Reconstruction with Layer Topology Guarantee
Apr 13, 2023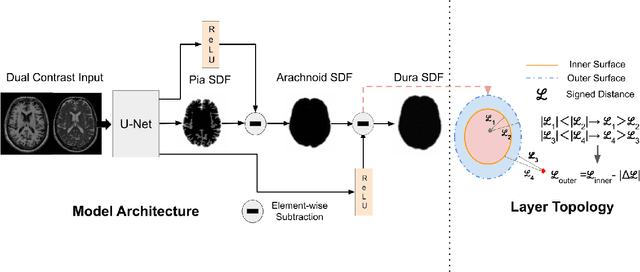
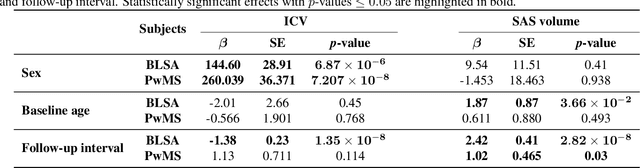
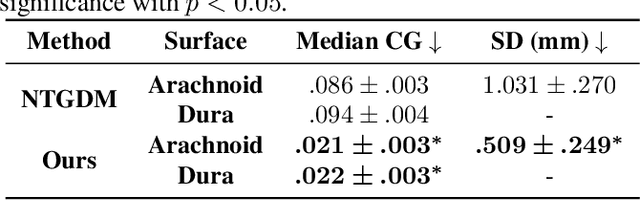
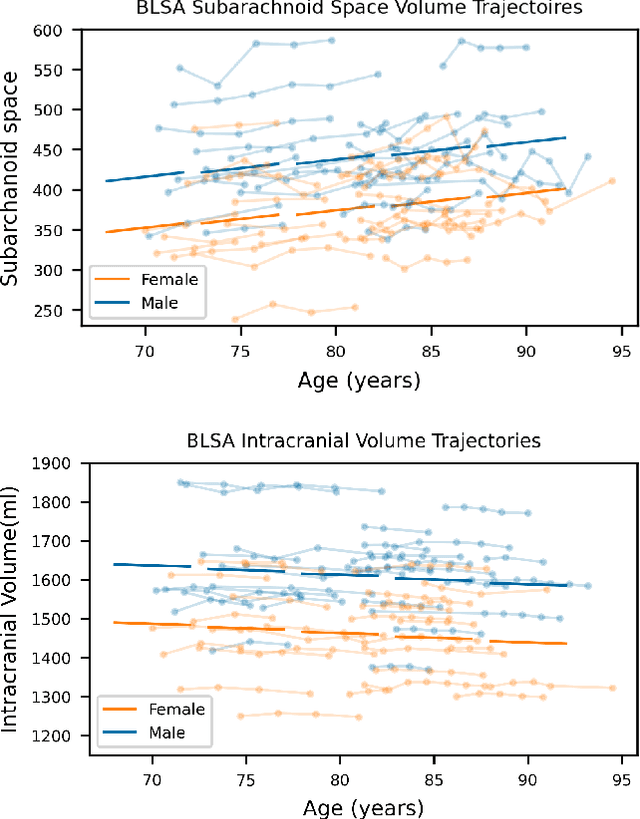
The meninges, located between the skull and brain, are composed of three membrane layers: the pia, the arachnoid, and the dura. Reconstruction of these layers can aid in studying volume differences between patients with neurodegenerative diseases and normal aging subjects. In this work, we use convolutional neural networks (CNNs) to reconstruct surfaces representing meningeal layer boundaries from magnetic resonance (MR) images. We first use the CNNs to predict the signed distance functions (SDFs) representing these surfaces while preserving their anatomical ordering. The marching cubes algorithm is then used to generate continuous surface representations; both the subarachnoid space (SAS) and the intracranial volume (ICV) are computed from these surfaces. The proposed method is compared to a state-of-the-art deformable model-based reconstruction method, and we show that our method can reconstruct smoother and more accurate surfaces using less computation time. Finally, we conduct experiments with volumetric analysis on both subjects with multiple sclerosis and healthy controls. For healthy and MS subjects, ICVs and SAS volumes are found to be significantly correlated to sex (p<0.01) and age (p<0.03) changes, respectively.
Improving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023



In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.
TAPLoss: A Temporal Acoustic Parameter Loss for Speech Enhancement
Feb 16, 2023
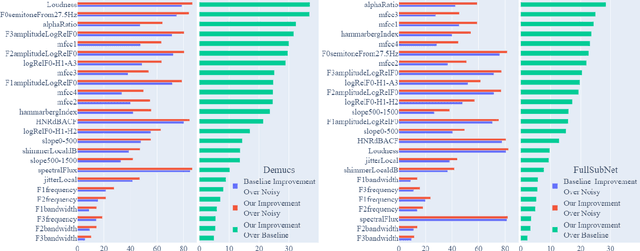

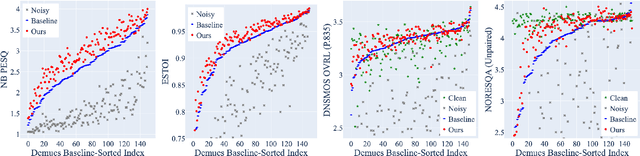
Speech enhancement models have greatly progressed in recent years, but still show limits in perceptual quality of their speech outputs. We propose an objective for perceptual quality based on temporal acoustic parameters. These are fundamental speech features that play an essential role in various applications, including speaker recognition and paralinguistic analysis. We provide a differentiable estimator for four categories of low-level acoustic descriptors involving: frequency-related parameters, energy or amplitude-related parameters, spectral balance parameters, and temporal features. Unlike prior work that looks at aggregated acoustic parameters or a few categories of acoustic parameters, our temporal acoustic parameter (TAP) loss enables auxiliary optimization and improvement of many fine-grain speech characteristics in enhancement workflows. We show that adding TAPLoss as an auxiliary objective in speech enhancement produces speech with improved perceptual quality and intelligibility. We use data from the Deep Noise Suppression 2020 Challenge to demonstrate that both time-domain models and time-frequency domain models can benefit from our method.
PAAPLoss: A Phonetic-Aligned Acoustic Parameter Loss for Speech Enhancement
Feb 16, 2023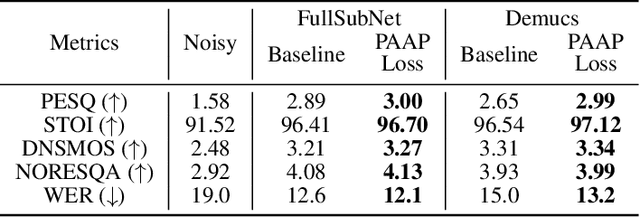
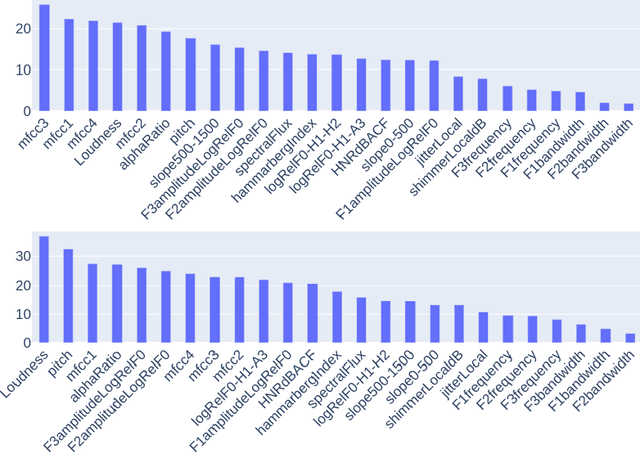

Despite rapid advancement in recent years, current speech enhancement models often produce speech that differs in perceptual quality from real clean speech. We propose a learning objective that formalizes differences in perceptual quality, by using domain knowledge of acoustic-phonetics. We identify temporal acoustic parameters -- such as spectral tilt, spectral flux, shimmer, etc. -- that are non-differentiable, and we develop a neural network estimator that can accurately predict their time-series values across an utterance. We also model phoneme-specific weights for each feature, as the acoustic parameters are known to show different behavior in different phonemes. We can add this criterion as an auxiliary loss to any model that produces speech, to optimize speech outputs to match the values of clean speech in these features. Experimentally we show that it improves speech enhancement workflows in both time-domain and time-frequency domain, as measured by standard evaluation metrics. We also provide an analysis of phoneme-dependent improvement on acoustic parameters, demonstrating the additional interpretability that our method provides. This analysis can suggest which features are currently the bottleneck for improvement.