 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuyong Gao
LVOS: A Benchmark for Large-scale Long-term Video Object Segmentation
May 01, 2024
Video object segmentation (VOS) aims to distinguish and track target objects in a video. Despite the excellent performance achieved by off-the-shell VOS models, existing VOS benchmarks mainly focus on short-term videos lasting about 5 seconds, where objects remain visible most of the time. However, these benchmarks poorly represent practical applications, and the absence of long-term datasets restricts further investigation of VOS in realistic scenarios. Thus, we propose a novel benchmark named LVOS, comprising 720 videos with 296,401 frames and 407,945 high-quality annotations. Videos in LVOS last 1.14 minutes on average, approximately 5 times longer than videos in existing datasets. Each video includes various attributes, especially challenges deriving from the wild, such as long-term reappearing and cross-temporal similar objects. Compared to previous benchmarks, our LVOS better reflects VOS models' performance in real scenarios. Based on LVOS, we evaluate 20 existing VOS models under 4 different settings and conduct a comprehensive analysis. On LVOS, these models suffer a large performance drop, highlighting the challenge of achieving precise tracking and segmentation in real-world scenarios. Attribute-based analysis indicates that key factor to accuracy decline is the increased video length, emphasizing LVOS's crucial role. We hope our LVOS can advance development of VOS in real scenes. Data and code are available at https://lingyihongfd.github.io/lvos.github.io/.
Improving Adversarial Transferability of Visual-Language Pre-training Models through Collaborative Multimodal Interaction
Mar 16, 2024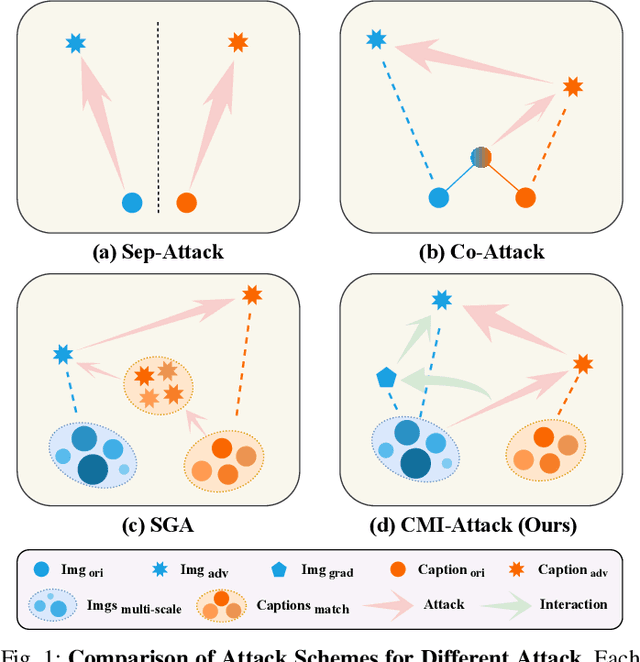
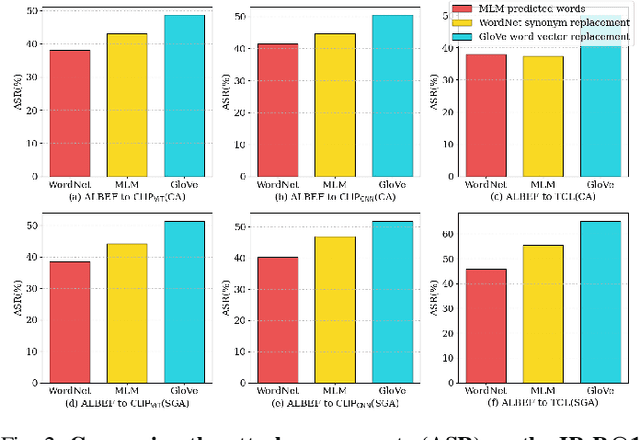
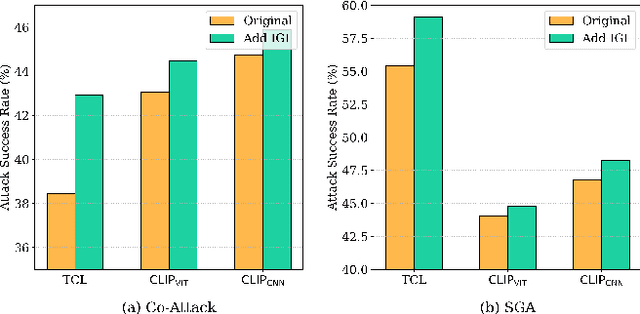

Despite the substantial advancements in Vision-Language Pre-training (VLP) models, their susceptibility to adversarial attacks poses a significant challenge. Existing work rarely studies the transferability of attacks on VLP models, resulting in a substantial performance gap from white-box attacks. We observe that prior work overlooks the interaction mechanisms between modalities, which plays a crucial role in understanding the intricacies of VLP models. In response, we propose a novel attack, called Collaborative Multimodal Interaction Attack (CMI-Attack), leveraging modality interaction through embedding guidance and interaction enhancement. Specifically, attacking text at the embedding level while preserving semantics, as well as utilizing interaction image gradients to enhance constraints on perturbations of texts and images. Significantly, in the image-text retrieval task on Flickr30K dataset, CMI-Attack raises the transfer success rates from ALBEF to TCL, $\text{CLIP}_{\text{ViT}}$ and $\text{CLIP}_{\text{CNN}}$ by 8.11%-16.75% over state-of-the-art methods. Moreover, CMI-Attack also demonstrates superior performance in cross-task generalization scenarios. Our work addresses the underexplored realm of transfer attacks on VLP models, shedding light on the importance of modality interaction for enhanced adversarial robustness.
ClickVOS: Click Video Object Segmentation
Mar 10, 2024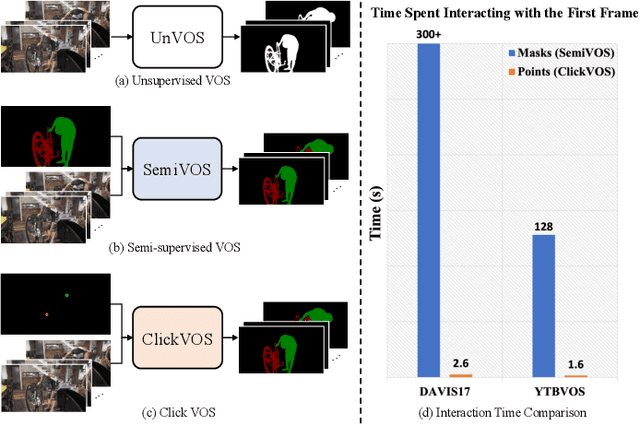
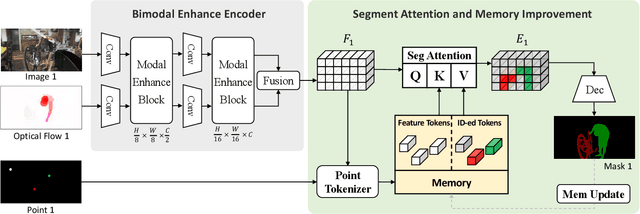
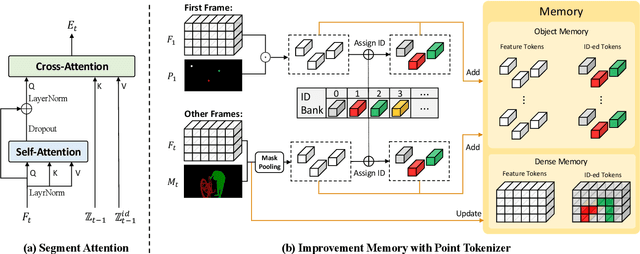
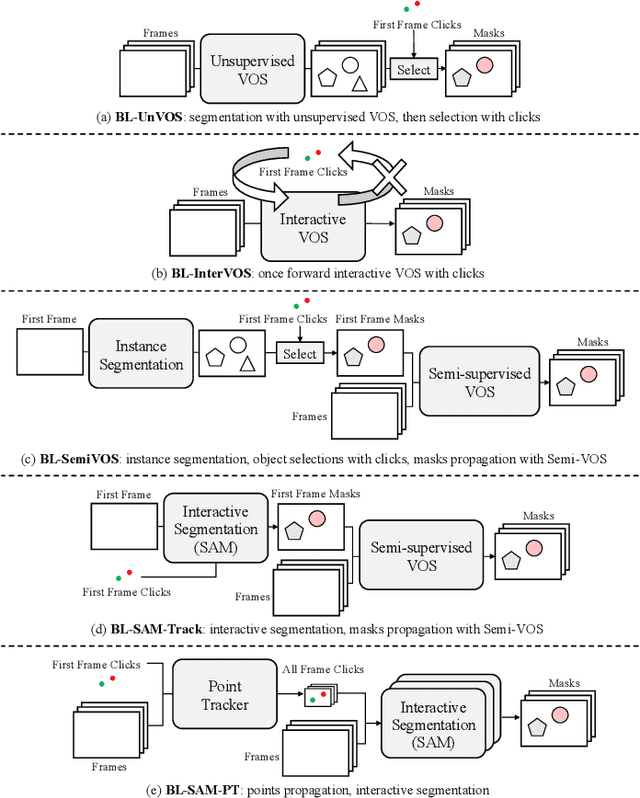
Video Object Segmentation (VOS) task aims to segment objects in videos. However, previous settings either require time-consuming manual masks of target objects at the first frame during inference or lack the flexibility to specify arbitrary objects of interest. To address these limitations, we propose the setting named Click Video Object Segmentation (ClickVOS) which segments objects of interest across the whole video according to a single click per object in the first frame. And we provide the extended datasets DAVIS-P and YouTubeVOSP that with point annotations to support this task. ClickVOS is of significant practical applications and research implications due to its only 1-2 seconds interaction time for indicating an object, comparing annotating the mask of an object needs several minutes. However, ClickVOS also presents increased challenges. To address this task, we propose an end-to-end baseline approach named called Attention Before Segmentation (ABS), motivated by the attention process of humans. ABS utilizes the given point in the first frame to perceive the target object through a concise yet effective segmentation attention. Although the initial object mask is possibly inaccurate, in our ABS, as the video goes on, the initially imprecise object mask can self-heal instead of deteriorating due to error accumulation, which is attributed to our designed improvement memory that continuously records stable global object memory and updates detailed dense memory. In addition, we conduct various baseline explorations utilizing off-the-shelf algorithms from related fields, which could provide insights for the further exploration of ClickVOS. The experimental results demonstrate the superiority of the proposed ABS approach. Extended datasets and codes will be available at https://github.com/PinxueGuo/ClickVOS.
SimulFlow: Simultaneously Extracting Feature and Identifying Target for Unsupervised Video Object Segmentation
Nov 30, 2023Unsupervised video object segmentation (UVOS) aims at detecting the primary objects in a given video sequence without any human interposing. Most existing methods rely on two-stream architectures that separately encode the appearance and motion information before fusing them to identify the target and generate object masks. However, this pipeline is computationally expensive and can lead to suboptimal performance due to the difficulty of fusing the two modalities properly. In this paper, we propose a novel UVOS model called SimulFlow that simultaneously performs feature extraction and target identification, enabling efficient and effective unsupervised video object segmentation. Concretely, we design a novel SimulFlow Attention mechanism to bridege the image and motion by utilizing the flexibility of attention operation, where coarse masks predicted from fused feature at each stage are used to constrain the attention operation within the mask area and exclude the impact of noise. Because of the bidirectional information flow between visual and optical flow features in SimulFlow Attention, no extra hand-designed fusing module is required and we only adopt a light decoder to obtain the final prediction. We evaluate our method on several benchmark datasets and achieve state-of-the-art results. Our proposed approach not only outperforms existing methods but also addresses the computational complexity and fusion difficulties caused by two-stream architectures. Our models achieve 87.4% J & F on DAVIS-16 with the highest speed (63.7 FPS on a 3090) and the lowest parameters (13.7 M). Our SimulFlow also obtains competitive results on video salient object detection datasets.
Towards End-to-End Unsupervised Saliency Detection with Self-Supervised Top-Down Context
Oct 14, 2023
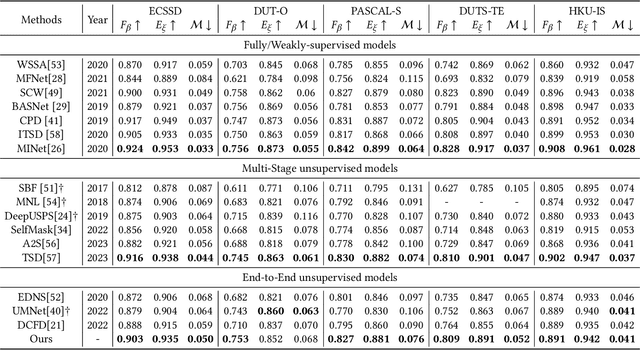

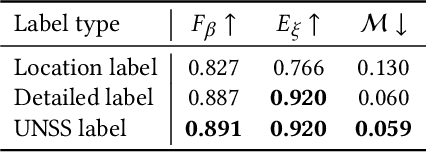
Unsupervised salient object detection aims to detect salient objects without using supervision signals eliminating the tedious task of manually labeling salient objects. To improve training efficiency, end-to-end methods for USOD have been proposed as a promising alternative. However, current solutions rely heavily on noisy handcraft labels and fail to mine rich semantic information from deep features. In this paper, we propose a self-supervised end-to-end salient object detection framework via top-down context. Specifically, motivated by contrastive learning, we exploit the self-localization from the deepest feature to construct the location maps which are then leveraged to learn the most instructive segmentation guidance. Further considering the lack of detailed information in deepest features, we exploit the detail-boosting refiner module to enrich the location labels with details. Moreover, we observe that due to lack of supervision, current unsupervised saliency models tend to detect non-salient objects that are salient in some other samples of corresponding scenarios. To address this widespread issue, we design a novel Unsupervised Non-Salient Suppression (UNSS) method developing the ability to ignore non-salient objects. Extensive experiments on benchmark datasets demonstrate that our method achieves leading performance among the recent end-to-end methods and most of the multi-stage solutions. The code is available.
Plug-and-Play Feature Generation for Few-Shot Medical Image Classification
Oct 14, 2023Few-shot learning (FSL) presents immense potential in enhancing model generalization and practicality for medical image classification with limited training data; however, it still faces the challenge of severe overfitting in classifier training due to distribution bias caused by the scarce training samples. To address the issue, we propose MedMFG, a flexible and lightweight plug-and-play method designed to generate sufficient class-distinctive features from limited samples. Specifically, MedMFG first re-represents the limited prototypes to assign higher weights for more important information features. Then, the prototypes are variationally generated into abundant effective features. Finally, the generated features and prototypes are together to train a more generalized classifier. Experiments demonstrate that MedMFG outperforms the previous state-of-the-art methods on cross-domain benchmarks involving the transition from natural images to medical images, as well as medical images with different lesions. Notably, our method achieves over 10% performance improvement compared to several baselines. Fusion experiments further validate the adaptability of MedMFG, as it seamlessly integrates into various backbones and baselines, consistently yielding improvements of over 2.9% across all results.
Weakly Supervised Video Salient Object Detection via Point Supervision
Jul 15, 2022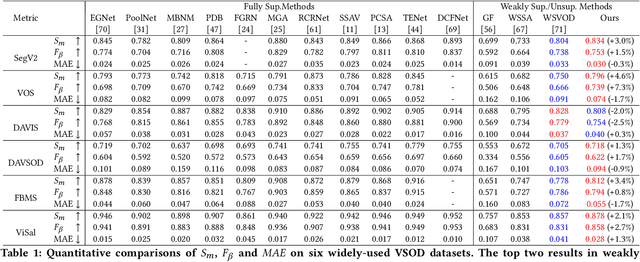
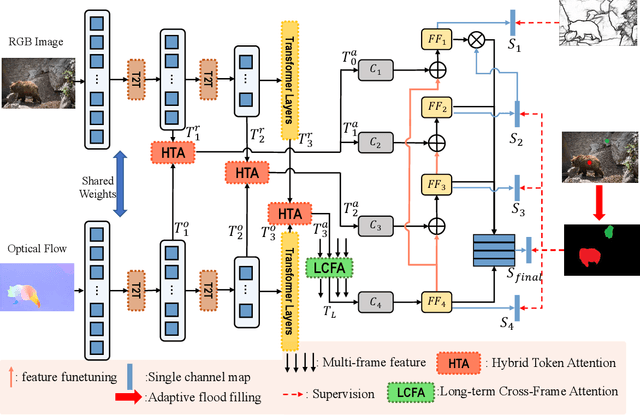
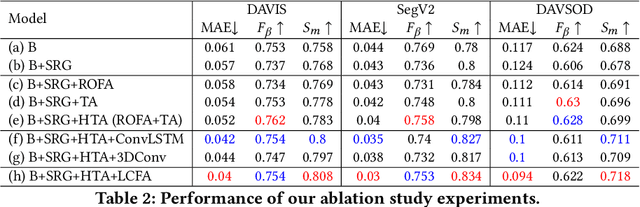
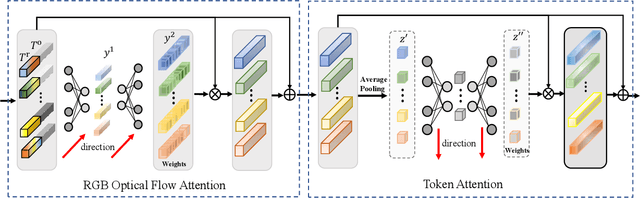
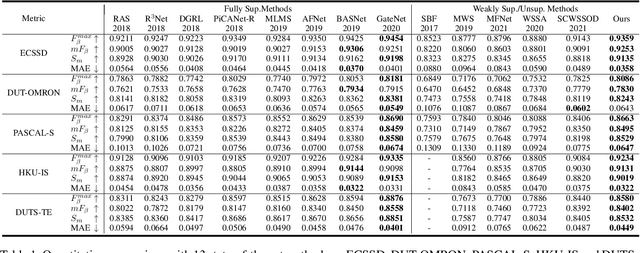
Video salient object detection models trained on pixel-wise dense annotation have achieved excellent performance, yet obtaining pixel-by-pixel annotated datasets is laborious. Several works attempt to use scribble annotations to mitigate this problem, but point supervision as a more labor-saving annotation method (even the most labor-saving method among manual annotation methods for dense prediction), has not been explored. In this paper, we propose a strong baseline model based on point supervision. To infer saliency maps with temporal information, we mine inter-frame complementary information from short-term and long-term perspectives, respectively. Specifically, we propose a hybrid token attention module, which mixes optical flow and image information from orthogonal directions, adaptively highlighting critical optical flow information (channel dimension) and critical token information (spatial dimension). To exploit long-term cues, we develop the Long-term Cross-Frame Attention module (LCFA), which assists the current frame in inferring salient objects based on multi-frame tokens. Furthermore, we label two point-supervised datasets, P-DAVIS and P-DAVSOD, by relabeling the DAVIS and the DAVSOD dataset. Experiments on the six benchmark datasets illustrate our method outperforms the previous state-of-the-art weakly supervised methods and even is comparable with some fully supervised approaches. Source code and datasets are available.
Weakly-Supervised Salient Object Detection Using Point Supervison
Mar 22, 2022
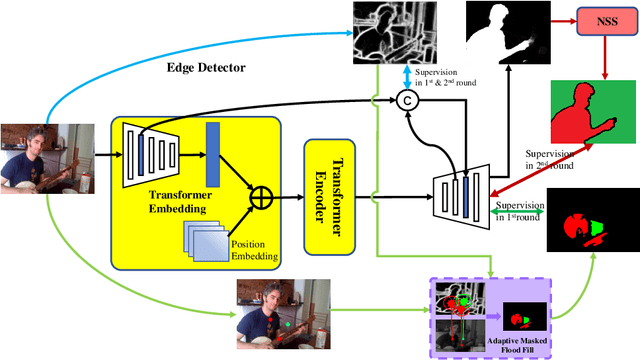
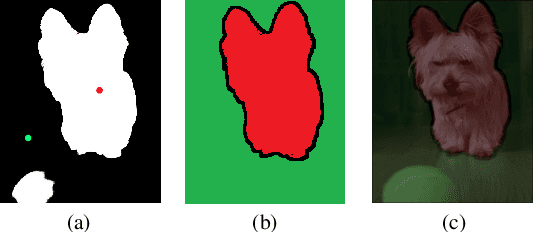
Current state-of-the-art saliency detection models rely heavily on large datasets of accurate pixel-wise annotations, but manually labeling pixels is time-consuming and labor-intensive. There are some weakly supervised methods developed for alleviating the problem, such as image label, bounding box label, and scribble label, while point label still has not been explored in this field. In this paper, we propose a novel weakly-supervised salient object detection method using point supervision. To infer the saliency map, we first design an adaptive masked flood filling algorithm to generate pseudo labels. Then we develop a transformer-based point-supervised saliency detection model to produce the first round of saliency maps. However, due to the sparseness of the label, the weakly supervised model tends to degenerate into a general foreground detection model. To address this issue, we propose a Non-Salient Suppression (NSS) method to optimize the erroneous saliency maps generated in the first round and leverage them for the second round of training. Moreover, we build a new point-supervised dataset (P-DUTS) by relabeling the DUTS dataset. In P-DUTS, there is only one labeled point for each salient object. Comprehensive experiments on five largest benchmark datasets demonstrate our method outperforms the previous state-of-the-art methods trained with the stronger supervision and even surpass several fully supervised state-of-the-art models. The code is available at: https://github.com/shuyonggao/PSOD.
FERV39k: A Large-Scale Multi-Scene Dataset for Facial Expression Recognition in Videos
Mar 20, 2022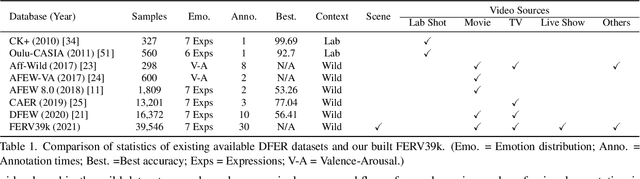
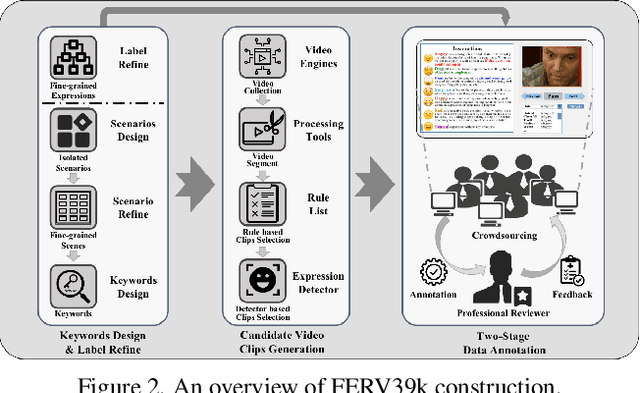
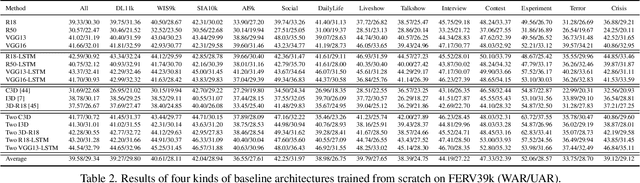
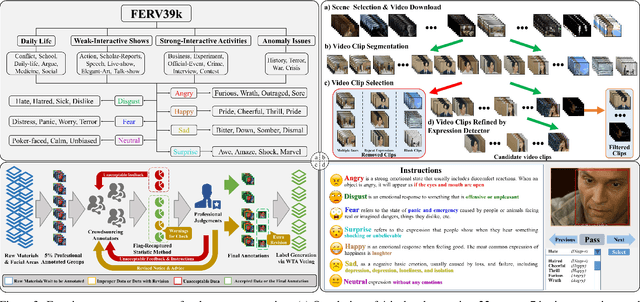
Current benchmarks for facial expression recognition (FER) mainly focus on static images, while there are limited datasets for FER in videos. It is still ambiguous to evaluate whether performances of existing methods remain satisfactory in real-world application-oriented scenes. For example, the "Happy" expression with high intensity in Talk-Show is more discriminating than the same expression with low intensity in Official-Event. To fill this gap, we build a large-scale multi-scene dataset, coined as FERV39k. We analyze the important ingredients of constructing such a novel dataset in three aspects: (1) multi-scene hierarchy and expression class, (2) generation of candidate video clips, (3) trusted manual labelling process. Based on these guidelines, we select 4 scenarios subdivided into 22 scenes, annotate 86k samples automatically obtained from 4k videos based on the well-designed workflow, and finally build 38,935 video clips labeled with 7 classic expressions. Experiment benchmarks on four kinds of baseline frameworks were also provided and further analysis on their performance across different scenes and some challenges for future research were given. Besides, we systematically investigate key components of DFER by ablation studies. The baseline framework and our project will be available.