 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiddhisanket Raskar
A Comprehensive Performance Study of Large Language Models on Novel AI Accelerators
Oct 06, 2023
Artificial intelligence (AI) methods have become critical in scientific applications to help accelerate scientific discovery. Large language models (LLMs) are being considered as a promising approach to address some of the challenging problems because of their superior generalization capabilities across domains. The effectiveness of the models and the accuracy of the applications is contingent upon their efficient execution on the underlying hardware infrastructure. Specialized AI accelerator hardware systems have recently become available for accelerating AI applications. However, the comparative performance of these AI accelerators on large language models has not been previously studied. In this paper, we systematically study LLMs on multiple AI accelerators and GPUs and evaluate their performance characteristics for these models. We evaluate these systems with (i) a micro-benchmark using a core transformer block, (ii) a GPT- 2 model, and (iii) an LLM-driven science use case, GenSLM. We present our findings and analyses of the models' performance to better understand the intrinsic capabilities of AI accelerators. Furthermore, our analysis takes into account key factors such as sequence lengths, scaling behavior, sparsity, and sensitivity to gradient accumulation steps.
Transfer Learning Across Heterogeneous Features For Efficient Tensor Program Generation
Apr 11, 2023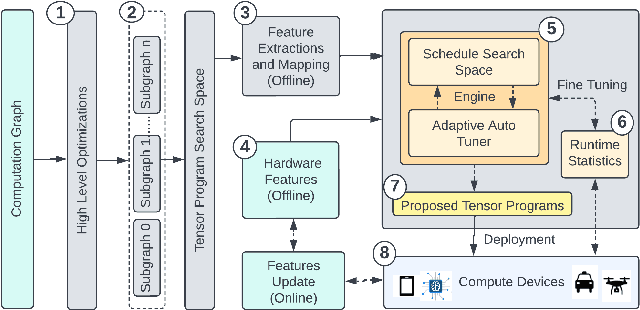
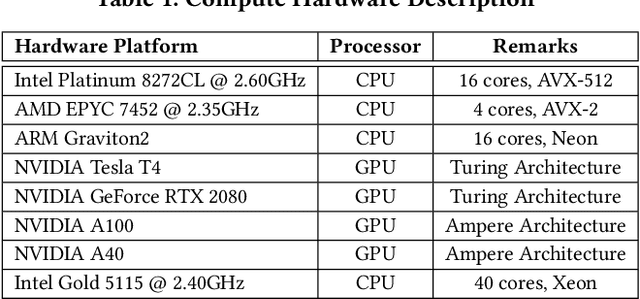
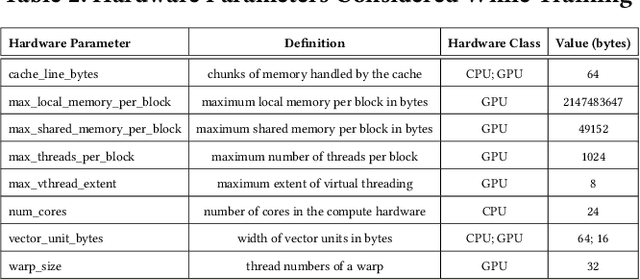
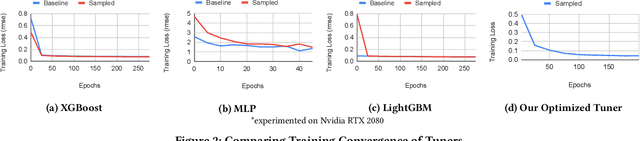
Tuning tensor program generation involves searching for various possible program transformation combinations for a given program on target hardware to optimize the tensor program execution. It is already a complex process because of the massive search space and exponential combinations of transformations make auto-tuning tensor program generation more challenging, especially when we have a heterogeneous target. In this research, we attempt to address these problems by learning the joint neural network and hardware features and transferring them to the new target hardware. We extensively study the existing state-of-the-art dataset, TenSet, perform comparative analysis on the test split strategies and propose methodologies to prune the dataset. We adopt an attention-inspired approach for tuning the tensor programs enabling them to embed neural network and hardware-specific features. Our approach could prune the dataset up to 45\% of the baseline without compromising the Pairwise Comparison Accuracy (PCA). Further, the proposed methodology can achieve on-par or improved mean inference time with 25%-40% of the baseline tuning time across different networks and target hardware.