 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilvia Chiappa
Additive Causal Bandits with Unknown Graph
Jun 13, 2023
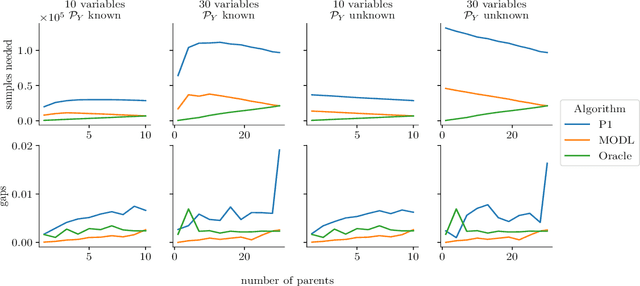
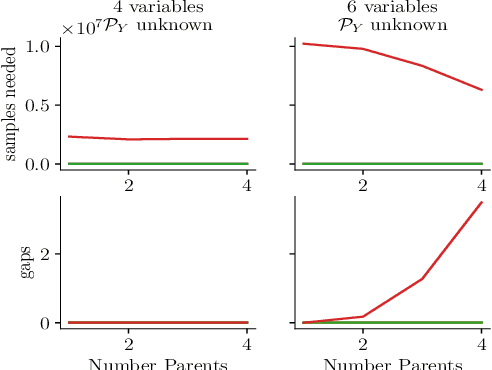
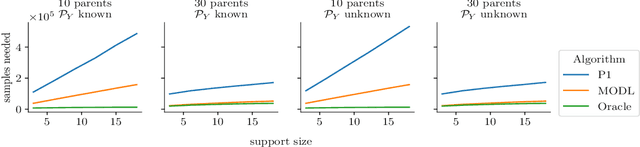
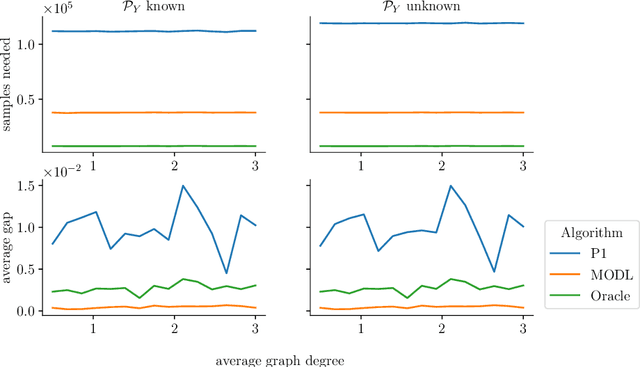
We explore algorithms to select actions in the causal bandit setting where the learner can choose to intervene on a set of random variables related by a causal graph, and the learner sequentially chooses interventions and observes a sample from the interventional distribution. The learner's goal is to quickly find the intervention, among all interventions on observable variables, that maximizes the expectation of an outcome variable. We depart from previous literature by assuming no knowledge of the causal graph except that latent confounders between the outcome and its ancestors are not present. We first show that the unknown graph problem can be exponentially hard in the parents of the outcome. To remedy this, we adopt an additional additive assumption on the outcome which allows us to solve the problem by casting it as an additive combinatorial linear bandit problem with full-bandit feedback. We propose a novel action-elimination algorithm for this setting, show how to apply this algorithm to the causal bandit problem, provide sample complexity bounds, and empirically validate our findings on a suite of randomly generated causal models, effectively showing that one does not need to explicitly learn the parents of the outcome to identify the best intervention.
Functional Causal Bayesian Optimization
Jun 10, 2023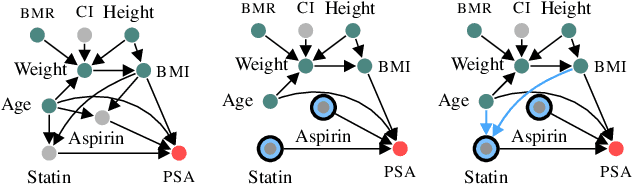

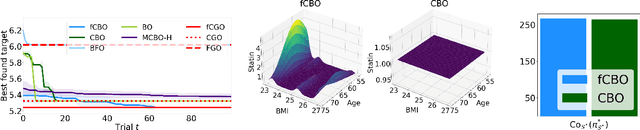
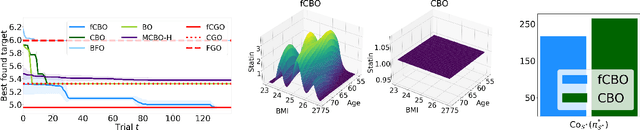
We propose functional causal Bayesian optimization (fCBO), a method for finding interventions that optimize a target variable in a known causal graph. fCBO extends the CBO family of methods to enable functional interventions, which set a variable to be a deterministic function of other variables in the graph. fCBO models the unknown objectives with Gaussian processes whose inputs are defined in a reproducing kernel Hilbert space, thus allowing to compute distances among vector-valued functions. In turn, this enables to sequentially select functions to explore by maximizing an expected improvement acquisition functional while keeping the typical computational tractability of standard BO settings. We introduce graphical criteria that establish when considering functional interventions allows attaining better target effects, and conditions under which selected interventions are also optimal for conditional target effects. We demonstrate the benefits of the method in a synthetic and in a real-world causal graph.
Constrained Causal Bayesian Optimization
May 31, 2023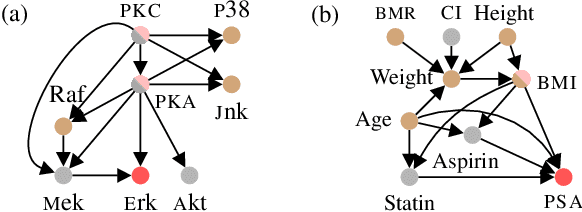

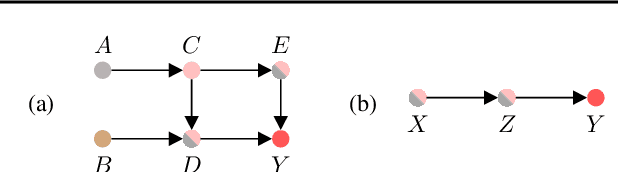
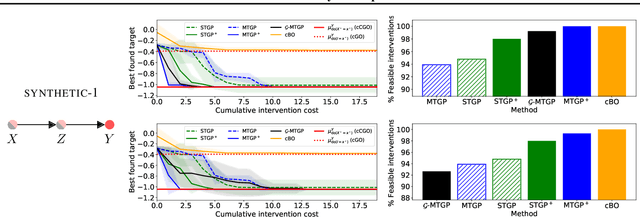
We propose constrained causal Bayesian optimization (cCBO), an approach for finding interventions in a known causal graph that optimize a target variable under some constraints. cCBO first reduces the search space by exploiting the graph structure and, if available, an observational dataset; and then solves the restricted optimization problem by modelling target and constraint quantities using Gaussian processes and by sequentially selecting interventions via a constrained expected improvement acquisition function. We propose different surrogate models that enable to integrate observational and interventional data while capturing correlation among effects with increasing levels of sophistication. We evaluate cCBO on artificial and real-world causal graphs showing successful trade off between fast convergence and percentage of feasible interventions.
DiscoGen: Learning to Discover Gene Regulatory Networks
Apr 12, 2023Accurately inferring Gene Regulatory Networks (GRNs) is a critical and challenging task in biology. GRNs model the activatory and inhibitory interactions between genes and are inherently causal in nature. To accurately identify GRNs, perturbational data is required. However, most GRN discovery methods only operate on observational data. Recent advances in neural network-based causal discovery methods have significantly improved causal discovery, including handling interventional data, improvements in performance and scalability. However, applying state-of-the-art (SOTA) causal discovery methods in biology poses challenges, such as noisy data and a large number of samples. Thus, adapting the causal discovery methods is necessary to handle these challenges. In this paper, we introduce DiscoGen, a neural network-based GRN discovery method that can denoise gene expression measurements and handle interventional data. We demonstrate that our model outperforms SOTA neural network-based causal discovery methods.
Pragmatic Fairness: Developing Policies with Outcome Disparity Control
Jan 28, 2023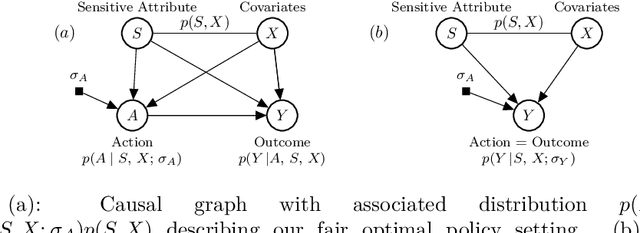
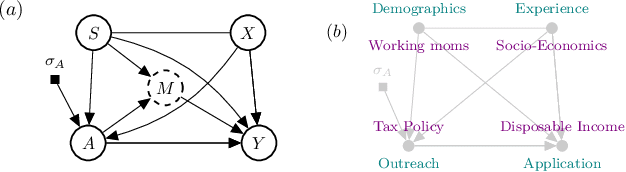
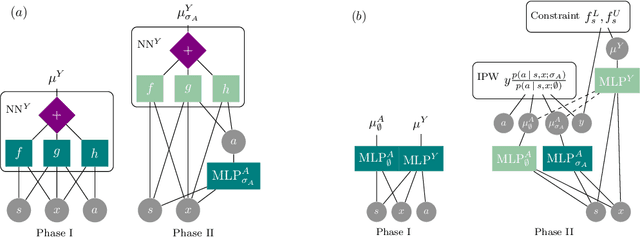
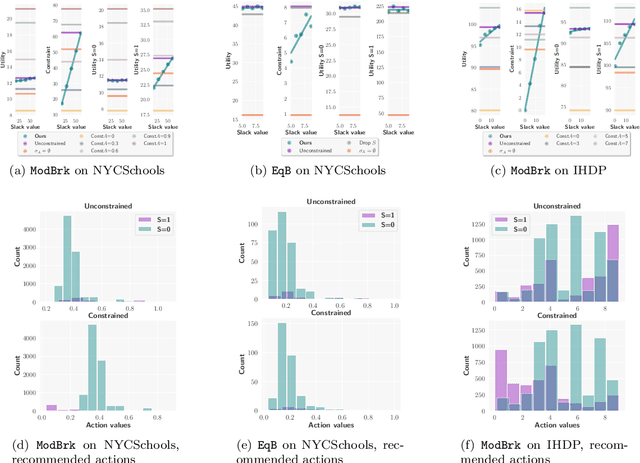
We introduce a causal framework for designing optimal policies that satisfy fairness constraints. We take a pragmatic approach asking what we can do with an action space available to us and only with access to historical data. We propose two different fairness constraints: a moderation breaking constraint which aims at blocking moderation paths from the action and sensitive attribute to the outcome, and by that at reducing disparity in outcome levels as much as the provided action space permits; and an equal benefit constraint which aims at distributing gain from the new and maximized policy equally across sensitive attribute levels, and thus at keeping pre-existing preferential treatment in place or avoiding the introduction of new disparity. We introduce practical methods for implementing the constraints and illustrate their uses on experiments with semi-synthetic models.
Learning to Induce Causal Structure
Apr 11, 2022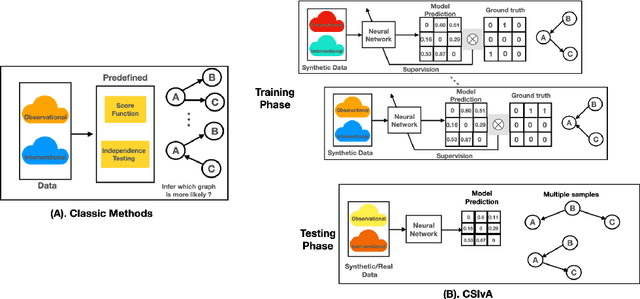
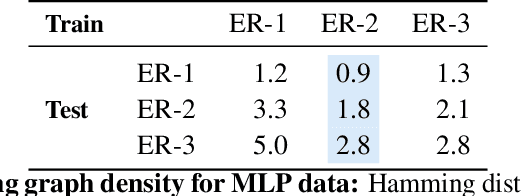
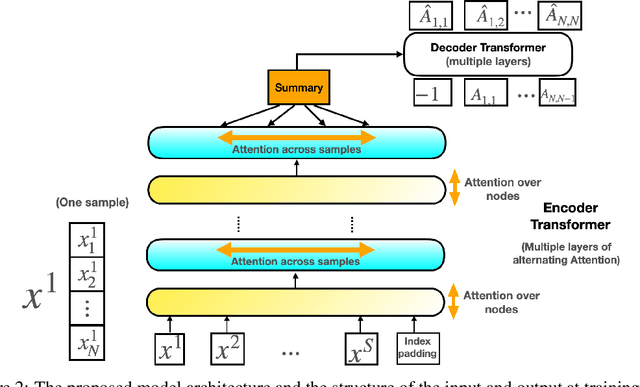
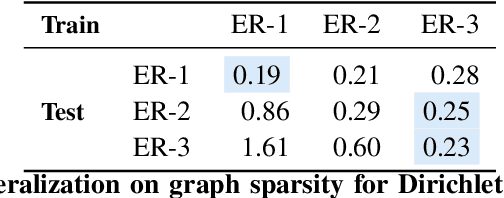
The fundamental challenge in causal induction is to infer the underlying graph structure given observational and/or interventional data. Most existing causal induction algorithms operate by generating candidate graphs and then evaluating them using either score-based methods (including continuous optimization) or independence tests. In this work, instead of proposing scoring function or independence tests, we treat the inference process as a black box and design a neural network architecture that learns the mapping from both observational and interventional data to graph structures via supervised training on synthetic graphs. We show that the proposed model generalizes not only to new synthetic graphs but also to naturalistic graphs.
Why Fair Labels Can Yield Unfair Predictions: Graphical Conditions for Introduced Unfairness
Feb 23, 2022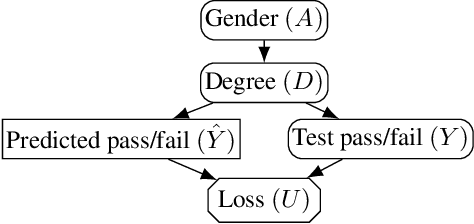

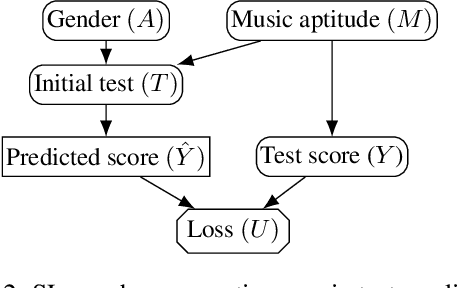
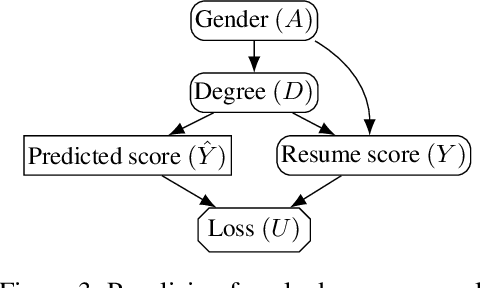
In addition to reproducing discriminatory relationships in the training data, machine learning systems can also introduce or amplify discriminatory effects. We refer to this as introduced unfairness, and investigate the conditions under which it may arise. To this end, we propose introduced total variation as a measure of introduced unfairness, and establish graphical conditions under which it may be incentivised to occur. These criteria imply that adding the sensitive attribute as a feature removes the incentive for introduced variation under well-behaved loss functions. Additionally, taking a causal perspective, introduced path-specific effects shed light on the issue of when specific paths should be considered fair.
Maintaining fairness across distribution shift: do we have viable solutions for real-world applications?
Feb 02, 2022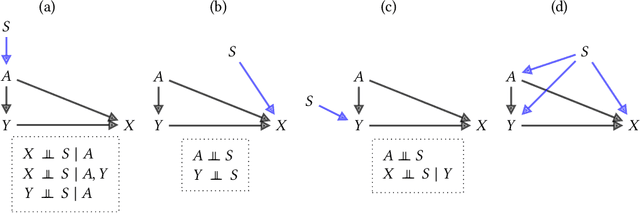
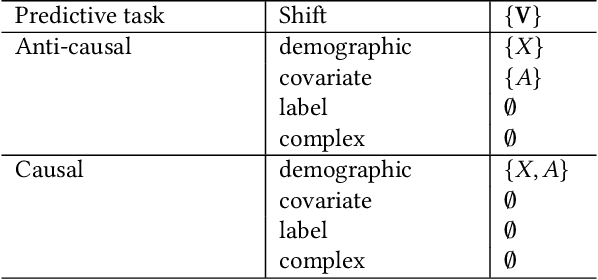
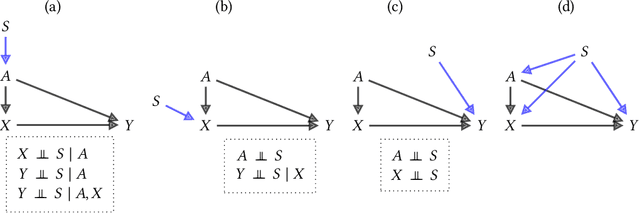
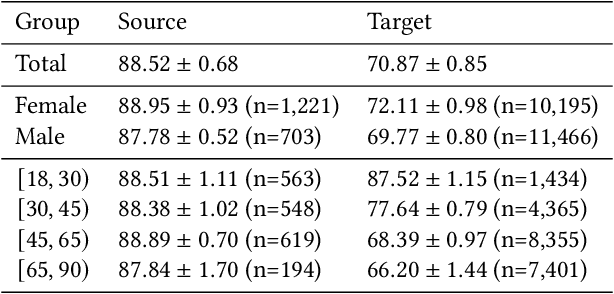
Fairness and robustness are often considered as orthogonal dimensions when evaluating machine learning models. However, recent work has revealed interactions between fairness and robustness, showing that fairness properties are not necessarily maintained under distribution shift. In healthcare settings, this can result in e.g. a model that performs fairly according to a selected metric in "hospital A" showing unfairness when deployed in "hospital B". While a nascent field has emerged to develop provable fair and robust models, it typically relies on strong assumptions about the shift, limiting its impact for real-world applications. In this work, we explore the settings in which recently proposed mitigation strategies are applicable by referring to a causal framing. Using examples of predictive models in dermatology and electronic health records, we show that real-world applications are complex and often invalidate the assumptions of such methods. Our work hence highlights technical, practical, and engineering gaps that prevent the development of robustly fair machine learning models for real-world applications. Finally, we discuss potential remedies at each step of the machine learning pipeline.
Statistical discrimination in learning agents
Oct 21, 2021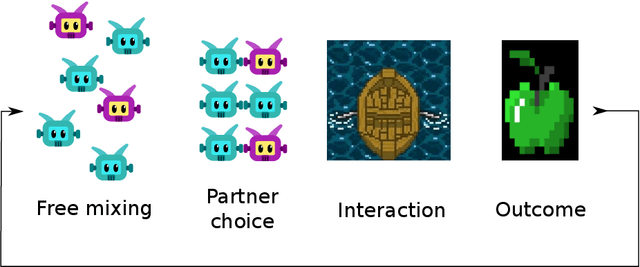
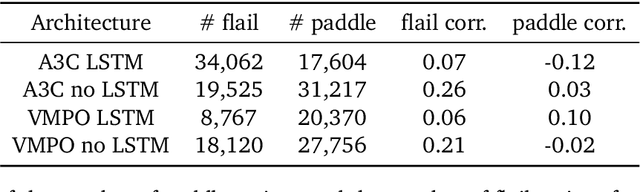
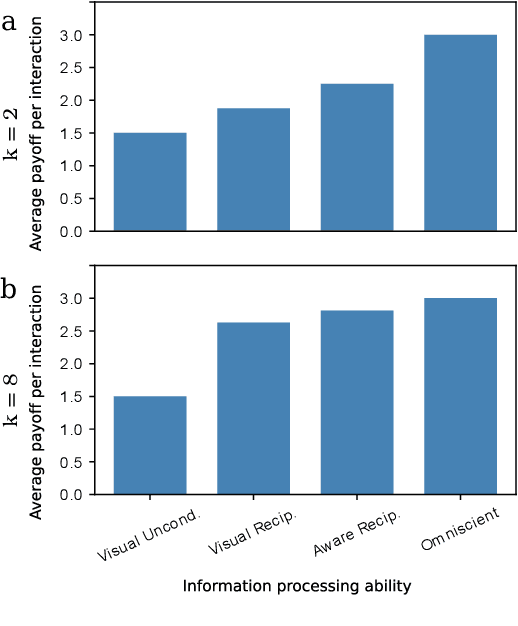
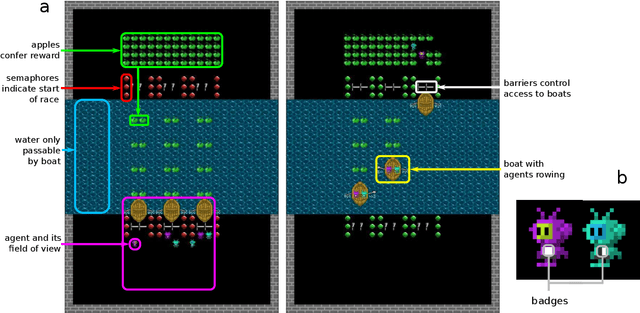
Undesired bias afflicts both human and algorithmic decision making, and may be especially prevalent when information processing trade-offs incentivize the use of heuristics. One primary example is \textit{statistical discrimination} -- selecting social partners based not on their underlying attributes, but on readily perceptible characteristics that covary with their suitability for the task at hand. We present a theoretical model to examine how information processing influences statistical discrimination and test its predictions using multi-agent reinforcement learning with various agent architectures in a partner choice-based social dilemma. As predicted, statistical discrimination emerges in agent policies as a function of both the bias in the training population and of agent architecture. All agents showed substantial statistical discrimination, defaulting to using the readily available correlates instead of the outcome relevant features. We show that less discrimination emerges with agents that use recurrent neural networks, and when their training environment has less bias. However, all agent algorithms we tried still exhibited substantial bias after learning in biased training populations.
Prequential MDL for Causal Structure Learning with Neural Networks
Jul 02, 2021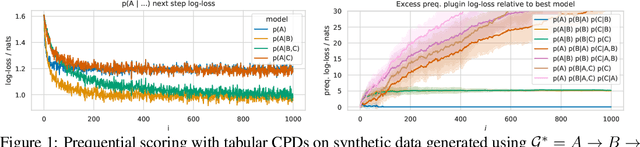

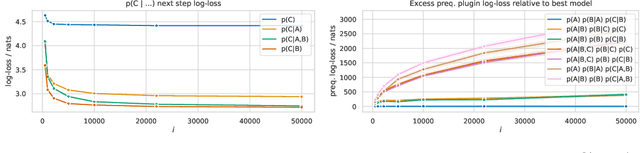
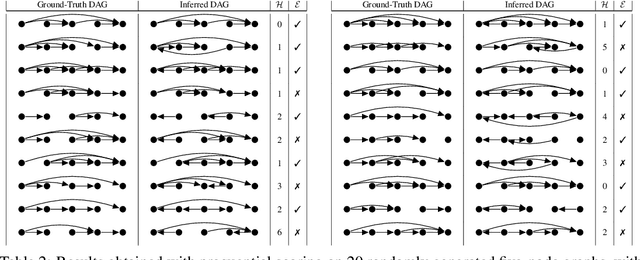
Learning the structure of Bayesian networks and causal relationships from observations is a common goal in several areas of science and technology. We show that the prequential minimum description length principle (MDL) can be used to derive a practical scoring function for Bayesian networks when flexible and overparametrized neural networks are used to model the conditional probability distributions between observed variables. MDL represents an embodiment of Occam's Razor and we obtain plausible and parsimonious graph structures without relying on sparsity inducing priors or other regularizers which must be tuned. Empirically we demonstrate competitive results on synthetic and real-world data. The score often recovers the correct structure even in the presence of strongly nonlinear relationships between variables; a scenario were prior approaches struggle and usually fail. Furthermore we discuss how the the prequential score relates to recent work that infers causal structure from the speed of adaptation when the observations come from a source undergoing distributional shift.