 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimon Olofsson
Design of Dynamic Experiments for Black-Box Model Discrimination
Feb 07, 2021
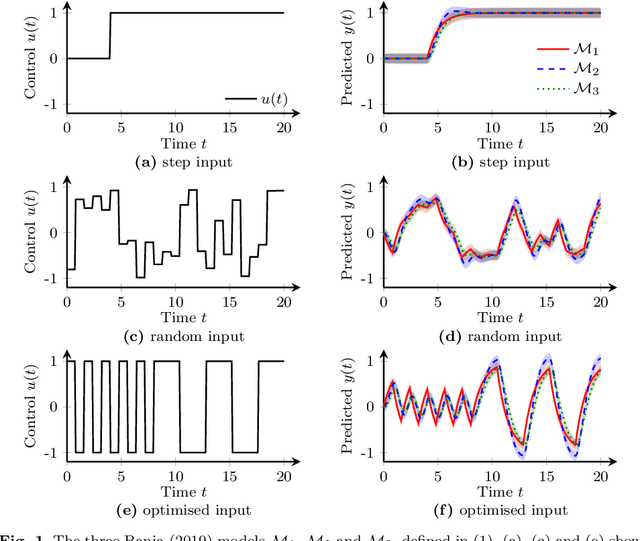
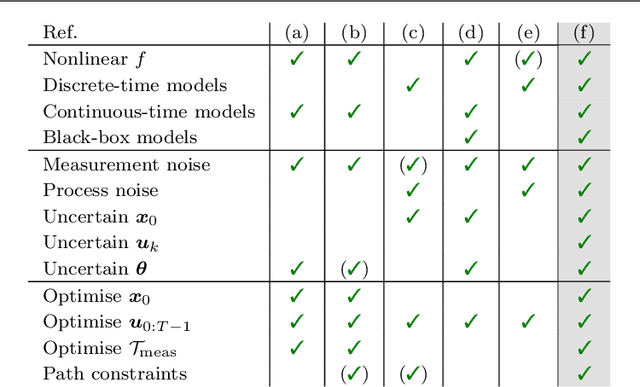
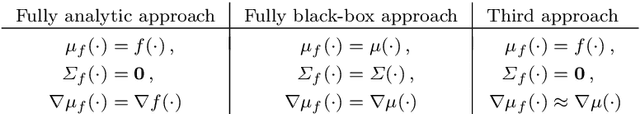
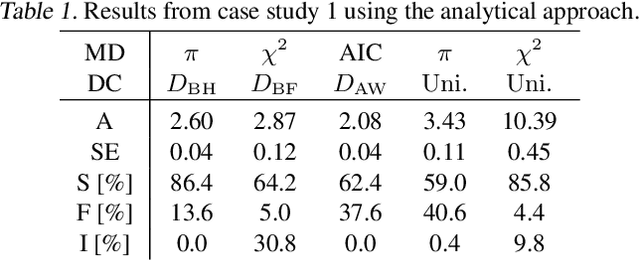
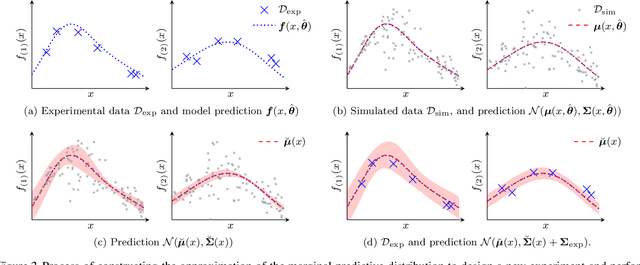
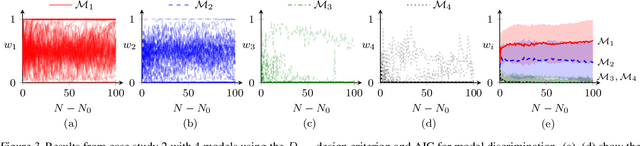
Diverse domains of science and engineering require and use mechanistic mathematical models, e.g. systems of differential algebraic equations. Such models often contain uncertain parameters to be estimated from data. Consider a dynamic model discrimination setting where we wish to chose: (i) what is the best mechanistic, time-varying model and (ii) what are the best model parameter estimates. These tasks are often termed model discrimination/selection/validation/verification. Typically, several rival mechanistic models can explain data, so we incorporate available data and also run new experiments to gather more data. Design of dynamic experiments for model discrimination helps optimally collect data. For rival mechanistic models where we have access to gradient information, we extend existing methods to incorporate a wider range of problem uncertainty and show that our proposed approach is equivalent to historical approaches when limiting the types of considered uncertainty. We also consider rival mechanistic models as dynamic black boxes that we can evaluate, e.g. by running legacy code, but where gradient or other advanced information is unavailable. We replace these black-box models with Gaussian process surrogate models and thereby extend the model discrimination setting to additionally incorporate rival black-box model. We also explore the consequences of using Gaussian process surrogates to approximate gradient-based methods.
Design of Experiments for Model Discrimination Hybridising Analytical and Data-Driven Approaches
May 31, 2018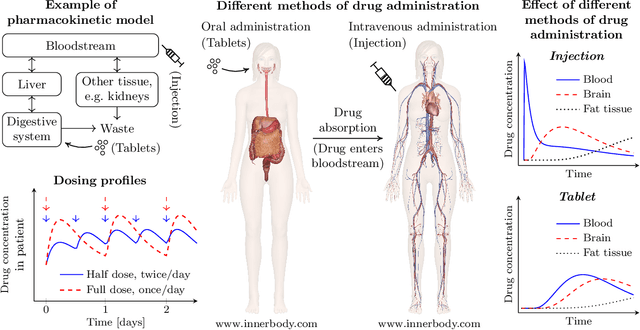
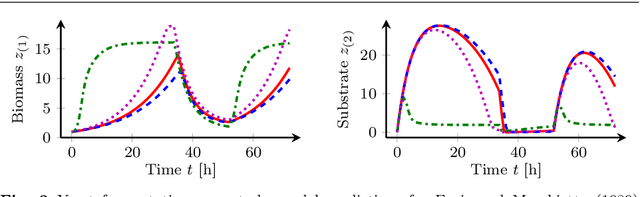
Healthcare companies must submit pharmaceutical drugs or medical devices to regulatory bodies before marketing new technology. Regulatory bodies frequently require transparent and interpretable computational modelling to justify a new healthcare technology, but researchers may have several competing models for a biological system and too little data to discriminate between the models. In design of experiments for model discrimination, the goal is to design maximally informative physical experiments in order to discriminate between rival predictive models. Prior work has focused either on analytical approaches, which cannot manage all functions, or on data-driven approaches, which may have computational difficulties or lack interpretable marginal predictive distributions. We develop a methodology introducing Gaussian process surrogates in lieu of the original mechanistic models. We thereby extend existing design and model discrimination methods developed for analytical models to cases of non-analytical models in a computationally efficient manner.