 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSina Akbari
Recursive Causal Discovery
Mar 14, 2024
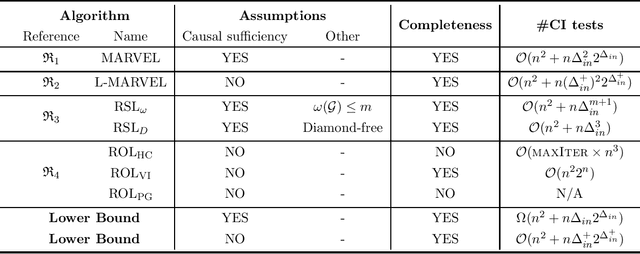
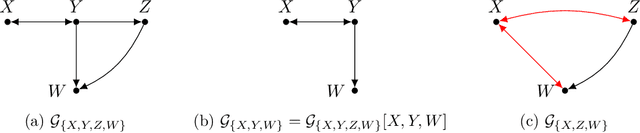
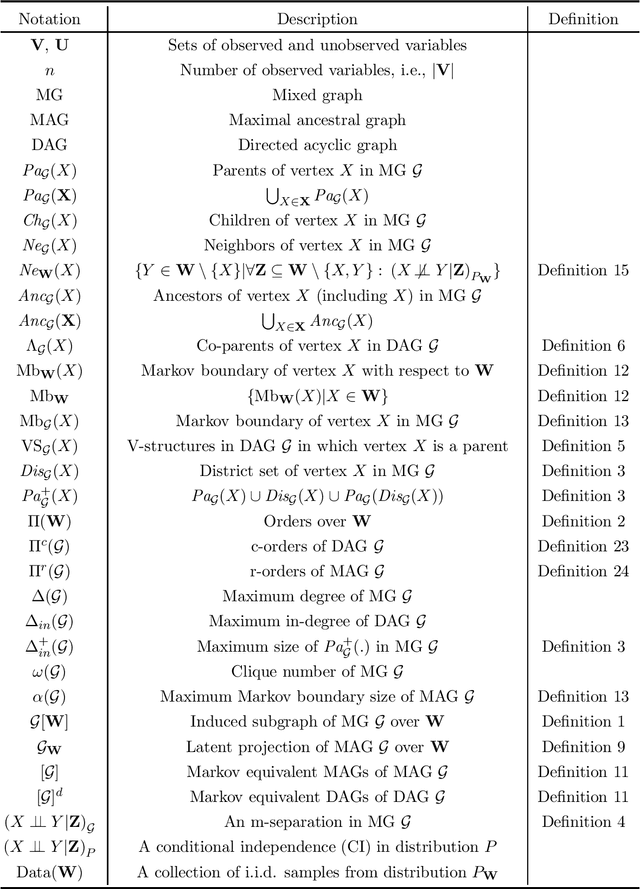
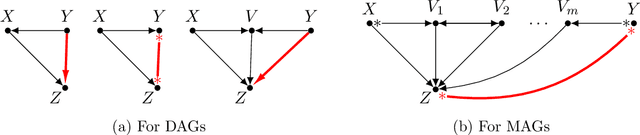
Causal discovery, i.e., learning the causal graph from data, is often the first step toward the identification and estimation of causal effects, a key requirement in numerous scientific domains. Causal discovery is hampered by two main challenges: limited data results in errors in statistical testing and the computational complexity of the learning task is daunting. This paper builds upon and extends four of our prior publications (Mokhtarian et al., 2021; Akbari et al., 2021; Mokhtarian et al., 2022, 2023a). These works introduced the concept of removable variables, which are the only variables that can be removed recursively for the purpose of causal discovery. Presence and identification of removable variables allow recursive approaches for causal discovery, a promising solution that helps to address the aforementioned challenges by reducing the problem size successively. This reduction not only minimizes conditioning sets in each conditional independence (CI) test, leading to fewer errors but also significantly decreases the number of required CI tests. The worst-case performances of these methods nearly match the lower bound. In this paper, we present a unified framework for the proposed algorithms, refined with additional details and enhancements for a coherent presentation. A comprehensive literature review is also included, comparing the computational complexity of our methods with existing approaches, showcasing their state-of-the-art efficiency. Another contribution of this paper is the release of RCD, a Python package that efficiently implements these algorithms. This package is designed for practitioners and researchers interested in applying these methods in practical scenarios. The package is available at github.com/ban-epfl/rcd, with comprehensive documentation provided at rcdpackage.com.
Causal Imitability Under Context-Specific Independence Relations
Jun 11, 2023Drawbacks of ignoring the causal mechanisms when performing imitation learning have recently been acknowledged. Several approaches both to assess the feasibility of imitation and to circumvent causal confounding and causal misspecifications have been proposed in the literature. However, the potential benefits of the incorporation of additional information about the underlying causal structure are left unexplored. An example of such overlooked information is context-specific independence (CSI), i.e., independence that holds only in certain contexts. We consider the problem of causal imitation learning when CSI relations are known. We prove that the decision problem pertaining to the feasibility of imitation in this setting is NP-hard. Further, we provide a necessary graphical criterion for imitation learning under CSI and show that under a structural assumption, this criterion is also sufficient. Finally, we propose a sound algorithmic approach for causal imitation learning which takes both CSI relations and data into account.
Learning Causal Graphs via Monotone Triangular Transport Maps
May 26, 2023



We study the problem of causal structure learning from data using optimal transport (OT). Specifically, we first provide a constraint-based method which builds upon lower-triangular monotone parametric transport maps to design conditional independence tests which are agnostic to the noise distribution. We provide an algorithm for causal discovery up to Markov Equivalence with no assumptions on the structural equations/noise distributions, which allows for settings with latent variables. Our approach also extends to score-based causal discovery by providing a novel means for defining scores. This allows us to uniquely recover the causal graph under additional identifiability and structural assumptions, such as additive noise or post-nonlinear models. We provide experimental results to compare the proposed approach with the state of the art on both synthetic and real-world datasets.
Causal Discovery in Probabilistic Networks with an Identifiable Causal Effect
Aug 13, 2022



Causal identification is at the core of the causal inference literature, where complete algorithms have been proposed to identify causal queries of interest. The validity of these algorithms hinges on the restrictive assumption of having access to a correctly specified causal structure. In this work, we study the setting where a probabilistic model of the causal structure is available. Specifically, the edges in a causal graph are assigned probabilities which may, for example, represent degree of belief from domain experts. Alternatively, the uncertainly about an edge may reflect the confidence of a particular statistical test. The question that naturally arises in this setting is: Given such a probabilistic graph and a specific causal effect of interest, what is the subgraph which has the highest plausibility and for which the causal effect is identifiable? We show that answering this question reduces to solving an NP-hard combinatorial optimization problem which we call the edge ID problem. We propose efficient algorithms to approximate this problem, and evaluate our proposed algorithms against real-world networks and randomly generated graphs.
Minimum Cost Intervention Design for Causal Effect Identification
May 04, 2022



Pearl's do calculus is a complete axiomatic approach to learn the identifiable causal effects from observational data. When such an effect is not identifiable, it is necessary to perform a collection of often costly interventions in the system to learn the causal effect. In this work, we consider the problem of designing the collection of interventions with the minimum cost to identify the desired effect. First, we prove that this problem is NP-hard, and subsequently propose an algorithm that can either find the optimal solution or a logarithmic-factor approximation of it. This is done by establishing a connection between our problem and the minimum hitting set problem. Additionally, we propose several polynomial-time heuristic algorithms to tackle the computational complexity of the problem. Although these algorithms could potentially stumble on sub-optimal solutions, our simulations show that they achieve small regrets on random graphs.
A Free Lunch with Influence Functions? Improving Neural Network Estimates with Concepts from Semiparametric Statistics
Feb 18, 2022



Parameter estimation in the empirical fields is usually undertaken using parametric models, and such models are convenient because they readily facilitate statistical inference. Unfortunately, they are unlikely to have a sufficiently flexible functional form to be able to adequately model real-world phenomena, and their usage may therefore result in biased estimates and invalid inference. Unfortunately, whilst non-parametric machine learning models may provide the needed flexibility to adapt to the complexity of real-world phenomena, they do not readily facilitate statistical inference, and may still exhibit residual bias. We explore the potential for semiparametric theory (in particular, the Influence Function) to be used to improve neural networks and machine learning algorithms in terms of (a) improving initial estimates without needing more data (b) increasing the robustness of our models, and (c) yielding confidence intervals for statistical inference. We propose a new neural network method MultiNet, which seeks the flexibility and diversity of an ensemble using a single architecture. Results on causal inference tasks indicate that MultiNet yields better performance than other approaches, and that all considered methods are amenable to improvement from semiparametric techniques under certain conditions. In other words, with these techniques we show that we can improve existing neural networks for `free', without needing more data, and without needing to retrain them. Finally, we provide the expression for deriving influence functions for estimands from a general graph, and the code to do so automatically.
Learning Bayesian Networks in the Presence of Structural Side Information
Dec 20, 2021



We study the problem of learning a Bayesian network (BN) of a set of variables when structural side information about the system is available. It is well known that learning the structure of a general BN is both computationally and statistically challenging. However, often in many applications, side information about the underlying structure can potentially reduce the learning complexity. In this paper, we develop a recursive constraint-based algorithm that efficiently incorporates such knowledge (i.e., side information) into the learning process. In particular, we study two types of structural side information about the underlying BN: (I) an upper bound on its clique number is known, or (II) it is diamond-free. We provide theoretical guarantees for the learning algorithms, including the worst-case number of tests required in each scenario. As a consequence of our work, we show that bounded treewidth BNs can be learned with polynomial complexity. Furthermore, we evaluate the performance and the scalability of our algorithms in both synthetic and real-world structures and show that they outperform the state-of-the-art structure learning algorithms.
Recursive Causal Structure Learning in the Presence of Latent Variables and Selection Bias
Oct 22, 2021



We consider the problem of learning the causal MAG of a system from observational data in the presence of latent variables and selection bias. Constraint-based methods are one of the main approaches for solving this problem, but the existing methods are either computationally impractical when dealing with large graphs or lacking completeness guarantees. We propose a novel computationally efficient recursive constraint-based method that is sound and complete. The key idea of our approach is that at each iteration a specific type of variable is identified and removed. This allows us to learn the structure efficiently and recursively, as this technique reduces both the number of required conditional independence (CI) tests and the size of the conditioning sets. The former substantially reduces the computational complexity, while the latter results in more reliable CI tests. We provide an upper bound on the number of required CI tests in the worst case. To the best of our knowledge, this is the tightest bound in the literature. We further provide a lower bound on the number of CI tests required by any constraint-based method. The upper bound of our proposed approach and the lower bound at most differ by a factor equal to the number of variables in the worst case. We provide experimental results to compare the proposed approach with the state of the art on both synthetic and real-world structures.
A Recursive Markov Blanket-Based Approach to Causal Structure Learning
Oct 10, 2020



One of the main approaches for causal structure learning is constraint-based methods. These methods are particularly valued as they are guaranteed to asymptotically find a structure which is statistically equivalent to the ground truth. However, they may require exponentially large number of conditional independence (CI) tests in the number of variables of the system. In this paper, we propose a novel recursive constraint-based method for causal structure learning. The key idea of the proposed approach is to recursively use Markov blanket information in order to identify a variable that can be removed from the set of variables without changing the statistical relations among the remaining variables. Once such a variable is found, its neighbors are identified, the removable variable is removed, and the Markov blanket information of the remaining variables is updated. Our proposed approach reduces the required number of conditional independence tests for structure learning compared to the state of the art. We also provide a lower bound on the number of CI tests required by any constraint-based method. Comparing this lower bound to our achievable bound demonstrates the efficiency of our approach. We evaluate and compare the performance of the proposed method on both synthetic and real world structures against the state of the art.