 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiyang Jiang
Dual Adversarial Alignment for Realistic Support-Query Shift Few-shot Learning
Sep 05, 2023


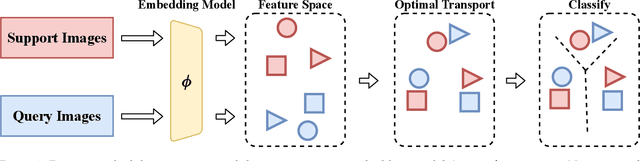
Support-query shift few-shot learning aims to classify unseen examples (query set) to labeled data (support set) based on the learned embedding in a low-dimensional space under a distribution shift between the support set and the query set. However, in real-world scenarios the shifts are usually unknown and varied, making it difficult to estimate in advance. Therefore, in this paper, we propose a novel but more difficult challenge, RSQS, focusing on Realistic Support-Query Shift few-shot learning. The key feature of RSQS is that the individual samples in a meta-task are subjected to multiple distribution shifts in each meta-task. In addition, we propose a unified adversarial feature alignment method called DUal adversarial ALignment framework (DuaL) to relieve RSQS from two aspects, i.e., inter-domain bias and intra-domain variance. On the one hand, for the inter-domain bias, we corrupt the original data in advance and use the synthesized perturbed inputs to train the repairer network by minimizing distance in the feature level. On the other hand, for intra-domain variance, we proposed a generator network to synthesize hard, i.e., less similar, examples from the support set in a self-supervised manner and introduce regularized optimal transportation to derive a smooth optimal transportation plan. Lastly, a benchmark of RSQS is built with several state-of-the-art baselines among three datasets (CIFAR100, mini-ImageNet, and Tiered-Imagenet). Experiment results show that DuaL significantly outperforms the state-of-the-art methods in our benchmark.
PGADA: Perturbation-Guided Adversarial Alignment for Few-shot Learning Under the Support-Query Shift
May 08, 2022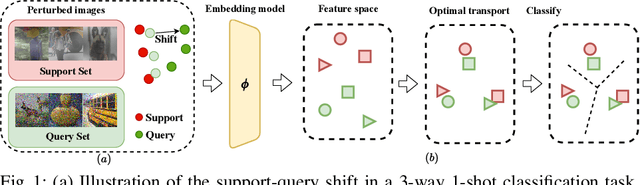
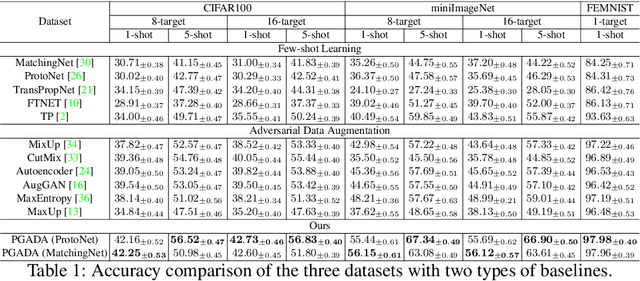
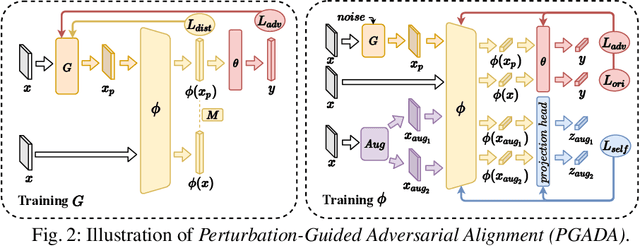
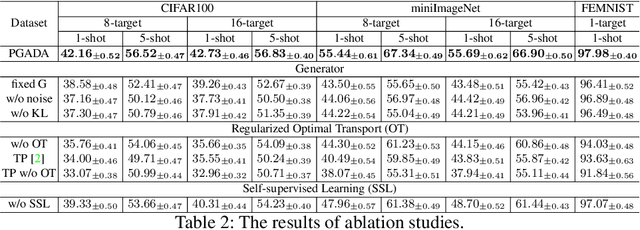
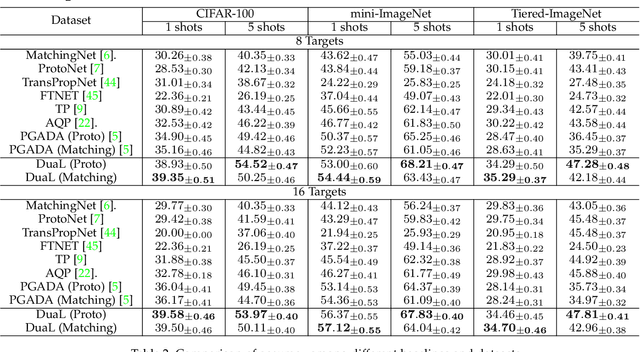
Few-shot learning methods aim to embed the data to a low-dimensional embedding space and then classify the unseen query data to the seen support set. While these works assume that the support set and the query set lie in the same embedding space, a distribution shift usually occurs between the support set and the query set, i.e., the Support-Query Shift, in the real world. Though optimal transportation has shown convincing results in aligning different distributions, we find that the small perturbations in the images would significantly misguide the optimal transportation and thus degrade the model performance. To relieve the misalignment, we first propose a novel adversarial data augmentation method, namely Perturbation-Guided Adversarial Alignment (PGADA), which generates the hard examples in a self-supervised manner. In addition, we introduce Regularized Optimal Transportation to derive a smooth optimal transportation plan. Extensive experiments on three benchmark datasets manifest that our framework significantly outperforms the eleven state-of-the-art methods on three datasets.
RIIT: Rethinking the Importance of Implementation Tricks in Multi-Agent Reinforcement Learning
Mar 01, 2021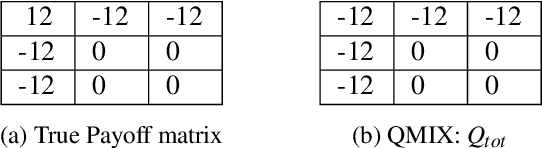


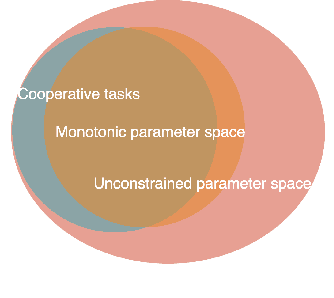
In recent years, Multi-Agent Deep Reinforcement Learning (MADRL) has been successfully applied to various complex scenarios such as computer games and robot swarms. We investigate the impact of "implementation tricks" of state-of-the-art (SOTA) QMIX-based algorithms. Firstly, we find that such tricks, described as auxiliary details to the core algorithm, seemingly of secondary importance, have a major impact. Our finding demonstrates that, after minimal tuning, QMIX attains extraordinarily high win rates and achieves SOTA in the StarCraft Multi-Agent Challenge (SMAC). Furthermore, we find QMIX's monotonicity condition helps improve sample efficiency in some cooperative tasks, and we propose a new policy-based algorithm, called: RIIT, to prove the importance of the monotonicity condition. RIIT also achieves SOTA in policy-based algorithms. At last, we propose a hypothesis to explain the monotonicity condition. We open-sourced the code at \url{https://github.com/hijkzzz/pymarl2}.