 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkander Moalla
No Representation, No Trust: Connecting Representation, Collapse, and Trust Issues in PPO
May 01, 2024
Reinforcement learning (RL) is inherently rife with non-stationarity since the states and rewards the agent observes during training depend on its changing policy. Therefore, networks in deep RL must be capable of adapting to new observations and fitting new targets. However, previous works have observed that networks in off-policy deep value-based methods exhibit a decrease in representation rank, often correlated with an inability to continue learning or a collapse in performance. Although this phenomenon has generally been attributed to neural network learning under non-stationarity, it has been overlooked in on-policy policy optimization methods which are often thought capable of training indefinitely. In this work, we empirically study representation dynamics in Proximal Policy Optimization (PPO) on the Atari and MuJoCo environments, revealing that PPO agents are also affected by feature rank deterioration and loss of plasticity. We show that this is aggravated with stronger non-stationarity, ultimately driving the actor's performance to collapse, regardless of the performance of the critic. We draw connections between representation collapse, performance collapse, and trust region issues in PPO, and present Proximal Feature Optimization (PFO), a novel auxiliary loss, that along with other interventions shows that regularizing the representation dynamics improves the performance of PPO agents.
SMACv2: An Improved Benchmark for Cooperative Multi-Agent Reinforcement Learning
Dec 14, 2022
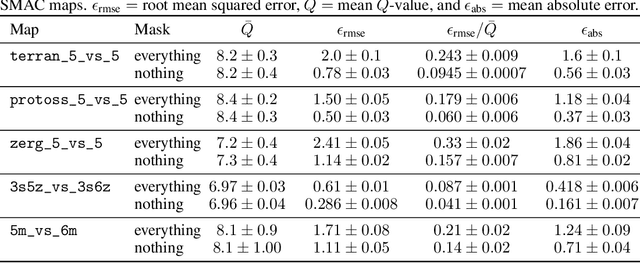
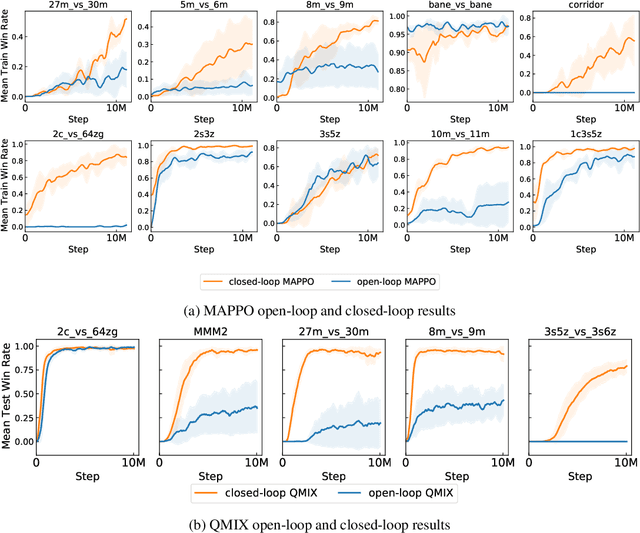
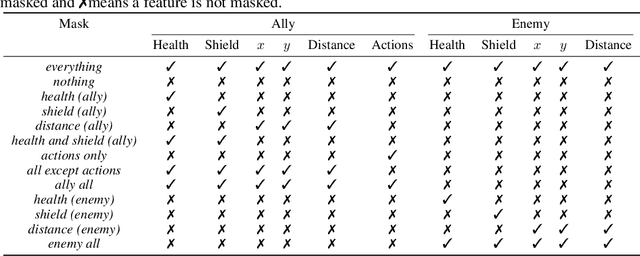
The availability of challenging benchmarks has played a key role in the recent progress of machine learning. In cooperative multi-agent reinforcement learning, the StarCraft Multi-Agent Challenge (SMAC) has become a popular testbed for centralised training with decentralised execution. However, after years of sustained improvement on SMAC, algorithms now achieve near-perfect performance. In this work, we conduct new analysis demonstrating that SMAC is not sufficiently stochastic to require complex closed-loop policies. In particular, we show that an open-loop policy conditioned only on the timestep can achieve non-trivial win rates for many SMAC scenarios. To address this limitation, we introduce SMACv2, a new version of the benchmark where scenarios are procedurally generated and require agents to generalise to previously unseen settings (from the same distribution) during evaluation. We show that these changes ensure the benchmark requires the use of closed-loop policies. We evaluate state-of-the-art algorithms on SMACv2 and show that it presents significant challenges not present in the original benchmark. Our analysis illustrates that SMACv2 addresses the discovered deficiencies of SMAC and can help benchmark the next generation of MARL methods. Videos of training are available at https://sites.google.com/view/smacv2