 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlobodan Beliga
Evaluation of Croatian Word Embeddings
Nov 07, 2017

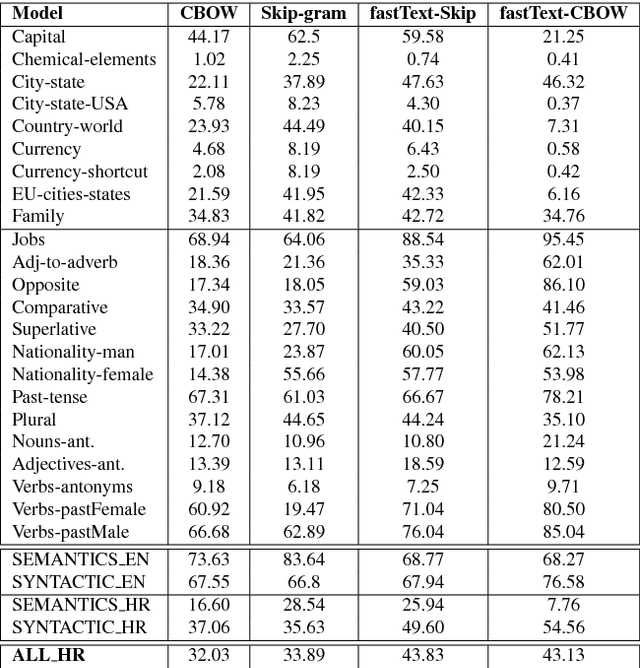
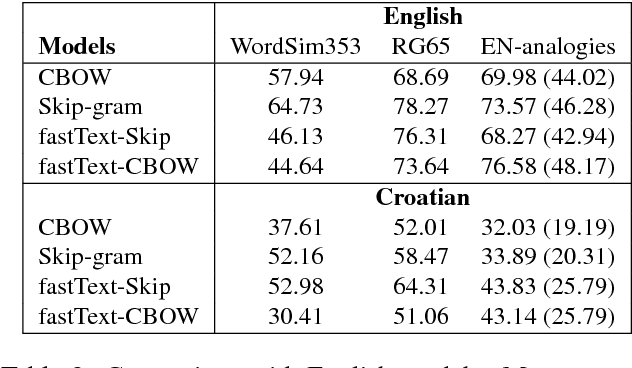
Croatian is poorly resourced and highly inflected language from Slavic language family. Nowadays, research is focusing mostly on English. We created a new word analogy corpus based on the original English Word2vec word analogy corpus and added some of the specific linguistic aspects from Croatian language. Next, we created Croatian WordSim353 and RG65 corpora for a basic evaluation of word similarities. We compared created corpora on two popular word representation models, based on Word2Vec tool and fastText tool. Models has been trained on 1.37B tokens training data corpus and tested on a new robust Croatian word analogy corpus. Results show that models are able to create meaningful word representation. This research has shown that free word order and the higher morphological complexity of Croatian language influences the quality of resulting word embeddings.
Normalization of Non-Standard Words in Croatian Texts
Mar 30, 2015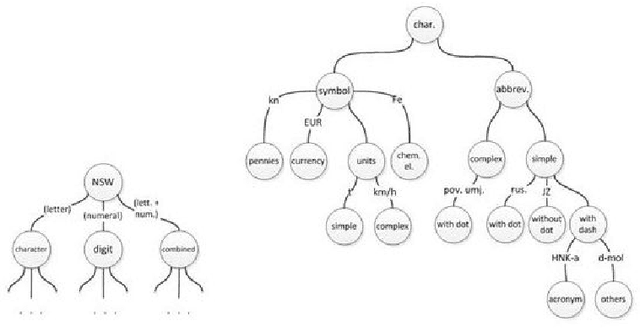
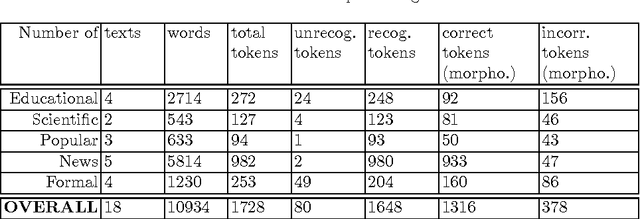

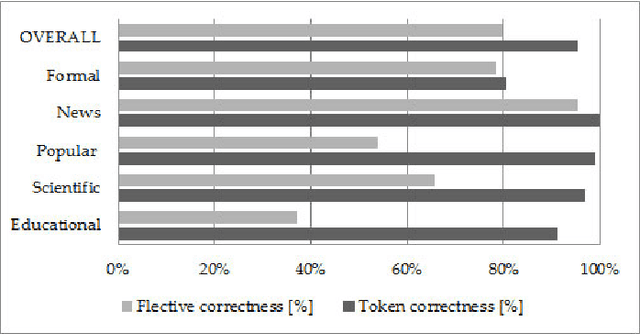
This paper presents text normalization which is an integral part of any text-to-speech synthesis system. Text normalization is a set of methods with a task to write non-standard words, like numbers, dates, times, abbreviations, acronyms and the most common symbols, in their full expanded form are presented. The whole taxonomy for classification of non-standard words in Croatian language together with rule-based normalization methods combined with a lookup dictionary are proposed. Achieved token rate for normalization of Croatian texts is 95%, where 80% of expanded words are in correct morphological form.
Non-Standard Words as Features for Text Categorization
Nov 16, 2014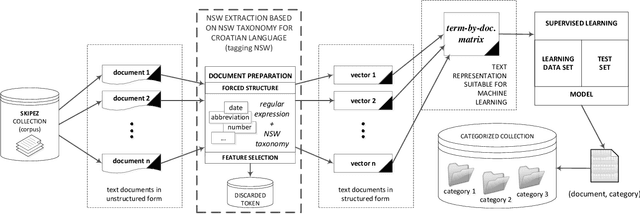
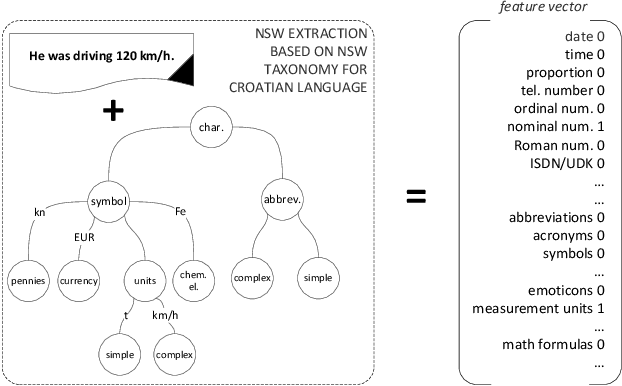
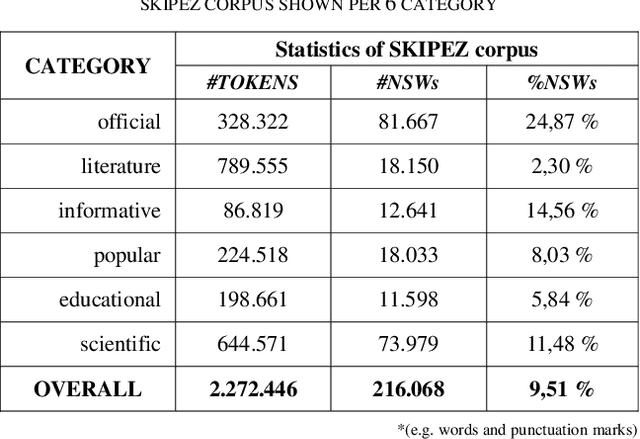
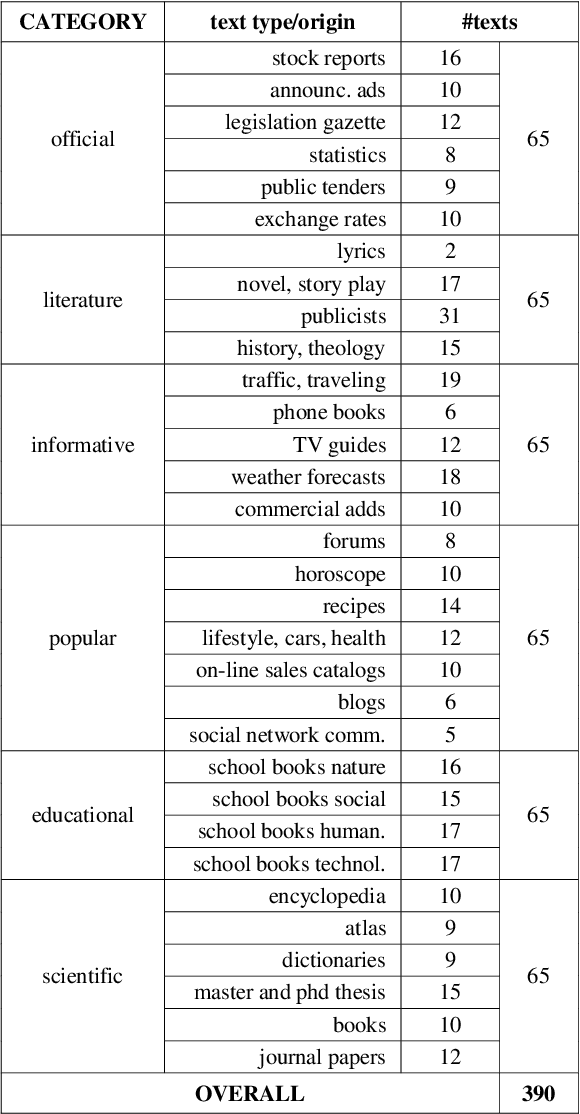
This paper presents categorization of Croatian texts using Non-Standard Words (NSW) as features. Non-Standard Words are: numbers, dates, acronyms, abbreviations, currency, etc. NSWs in Croatian language are determined according to Croatian NSW taxonomy. For the purpose of this research, 390 text documents were collected and formed the SKIPEZ collection with 6 classes: official, literary, informative, popular, educational and scientific. Text categorization experiment was conducted on three different representations of the SKIPEZ collection: in the first representation, the frequencies of NSWs are used as features; in the second representation, the statistic measures of NSWs (variance, coefficient of variation, standard deviation, etc.) are used as features; while the third representation combines the first two feature sets. Naive Bayes, CN2, C4.5, kNN, Classification Trees and Random Forest algorithms were used in text categorization experiments. The best categorization results are achieved using the first feature set (NSW frequencies) with the categorization accuracy of 87%. This suggests that the NSWs should be considered as features in highly inflectional languages, such as Croatian. NSW based features reduce the dimensionality of the feature space without standard lemmatization procedures, and therefore the bag-of-NSWs should be considered for further Croatian texts categorization experiments.
* IEEE 37th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO 2014), pp. 1415-1419, 2014
Toward Selectivity Based Keyword Extraction for Croatian News
Jul 17, 2014
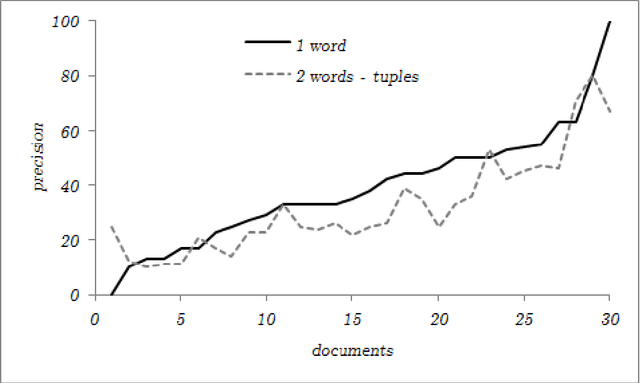
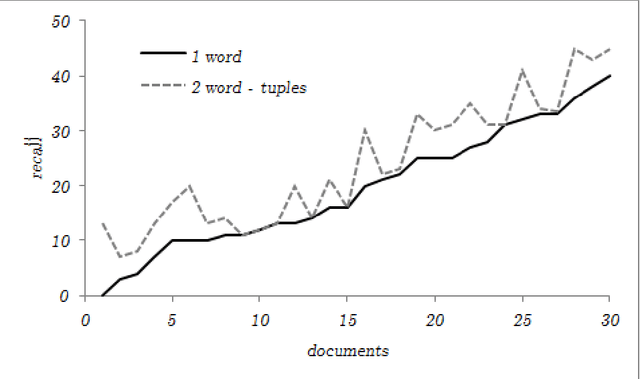

Preliminary report on network based keyword extraction for Croatian is an unsupervised method for keyword extraction from the complex network. We build our approach with a new network measure the node selectivity, motivated by the research of the graph based centrality approaches. The node selectivity is defined as the average weight distribution on the links of the single node. We extract nodes (keyword candidates) based on the selectivity value. Furthermore, we expand extracted nodes to word-tuples ranked with the highest in/out selectivity values. Selectivity based extraction does not require linguistic knowledge while it is purely derived from statistical and structural information en-compassed in the source text which is reflected into the structure of the network. Obtained sets are evaluated on a manually annotated keywords: for the set of extracted keyword candidates average F1 score is 24,63%, and average F2 score is 21,19%; for the exacted words-tuples candidates average F1 score is 25,9% and average F2 score is 24,47%.