 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoledad Villar
Approximately Equivariant Graph Networks
Sep 03, 2023


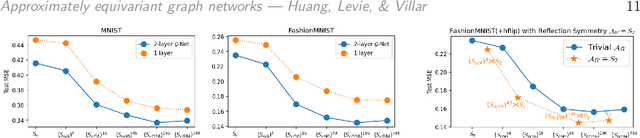

Graph neural networks (GNNs) are commonly described as being permutation equivariant with respect to node relabeling in the graph. This symmetry of GNNs is often compared to the translation equivariance symmetry of Euclidean convolution neural networks (CNNs). However, these two symmetries are fundamentally different: The translation equivariance of CNNs corresponds to symmetries of the fixed domain acting on the image signal (sometimes known as active symmetries), whereas in GNNs any permutation acts on both the graph signals and the graph domain (sometimes described as passive symmetries). In this work, we focus on the active symmetries of GNNs, by considering a learning setting where signals are supported on a fixed graph. In this case, the natural symmetries of GNNs are the automorphisms of the graph. Since real-world graphs tend to be asymmetric, we relax the notion of symmetries by formalizing approximate symmetries via graph coarsening. We present a bias-variance formula that quantifies the tradeoff between the loss in expressivity and the gain in the regularity of the learned estimator, depending on the chosen symmetry group. To illustrate our approach, we conduct extensive experiments on image inpainting, traffic flow prediction, and human pose estimation with different choices of symmetries. We show theoretically and empirically that the best generalization performance can be achieved by choosing a suitably larger group than the graph automorphism group, but smaller than the full permutation group.
Structuring Representation Geometry with Rotationally Equivariant Contrastive Learning
Jun 24, 2023Self-supervised learning converts raw perceptual data such as images to a compact space where simple Euclidean distances measure meaningful variations in data. In this paper, we extend this formulation by adding additional geometric structure to the embedding space by enforcing transformations of input space to correspond to simple (i.e., linear) transformations of embedding space. Specifically, in the contrastive learning setting, we introduce an equivariance objective and theoretically prove that its minima forces augmentations on input space to correspond to rotations on the spherical embedding space. We show that merely combining our equivariant loss with a non-collapse term results in non-trivial representations, without requiring invariance to data augmentations. Optimal performance is achieved by also encouraging approximate invariance, where input augmentations correspond to small rotations. Our method, CARE: Contrastive Augmentation-induced Rotational Equivariance, leads to improved performance on downstream tasks, and ensures sensitivity in embedding space to important variations in data (e.g., color) that standard contrastive methods do not achieve. Code is available at https://github.com/Sharut/CARE.
Fine-grained Expressivity of Graph Neural Networks
Jun 06, 2023

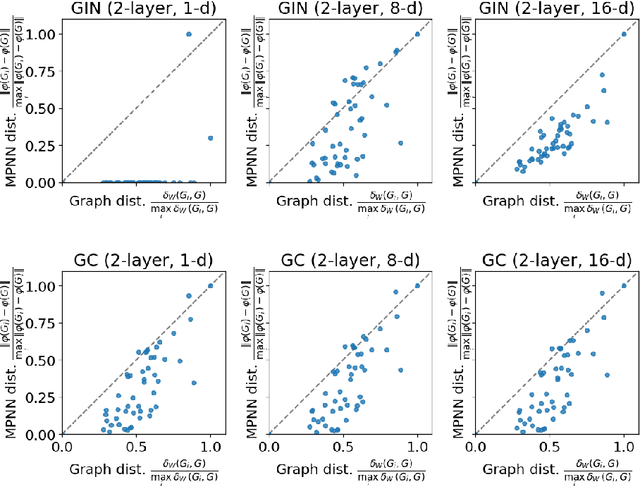
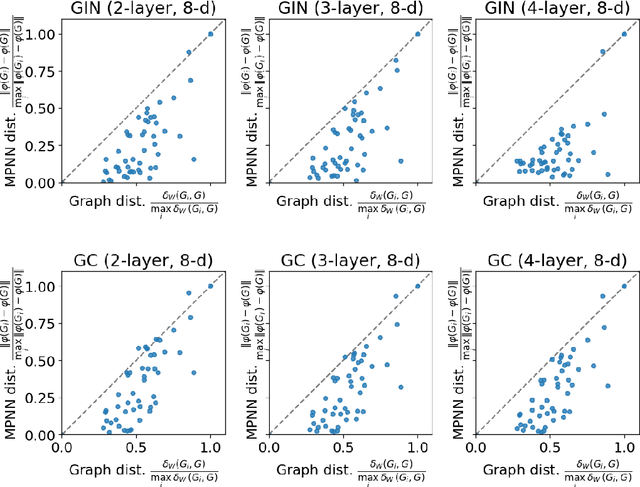
Numerous recent works have analyzed the expressive power of message-passing graph neural networks (MPNNs), primarily utilizing combinatorial techniques such as the $1$-dimensional Weisfeiler-Leman test ($1$-WL) for the graph isomorphism problem. However, the graph isomorphism objective is inherently binary, not giving insights into the degree of similarity between two given graphs. This work resolves this issue by considering continuous extensions of both $1$-WL and MPNNs to graphons. Concretely, we show that the continuous variant of $1$-WL delivers an accurate topological characterization of the expressive power of MPNNs on graphons, revealing which graphs these networks can distinguish and the level of difficulty in separating them. We identify the finest topology where MPNNs separate points and prove a universal approximation theorem. Consequently, we provide a theoretical framework for graph and graphon similarity combining various topological variants of classical characterizations of the $1$-WL. In particular, we characterize the expressive power of MPNNs in terms of the tree distance, which is a graph distance based on the concepts of fractional isomorphisms, and substructure counts via tree homomorphisms, showing that these concepts have the same expressive power as the $1$-WL and MPNNs on graphons. Empirically, we validate our theoretical findings by showing that randomly initialized MPNNs, without training, exhibit competitive performance compared to their trained counterparts. Moreover, we evaluate different MPNN architectures based on their ability to preserve graph distances, highlighting the significance of our continuous $1$-WL test in understanding MPNNs' expressivity.
GeometricImageNet: Extending convolutional neural networks to vector and tensor images
May 21, 2023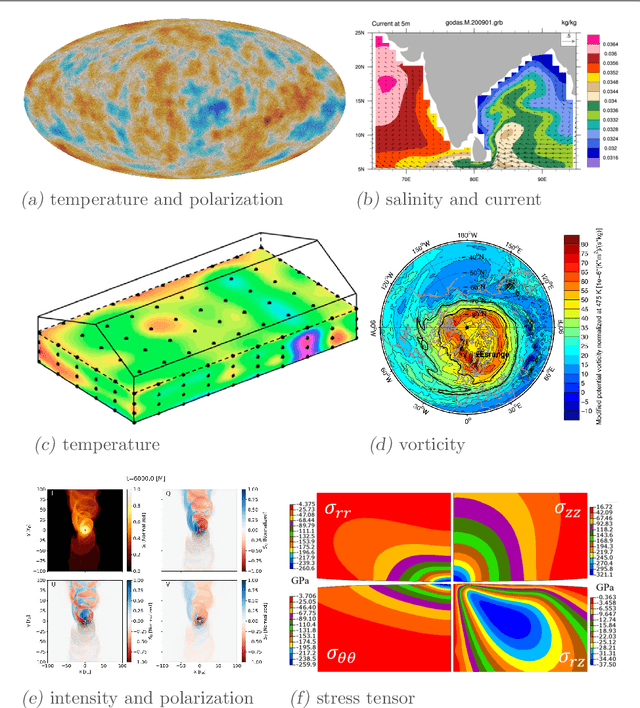

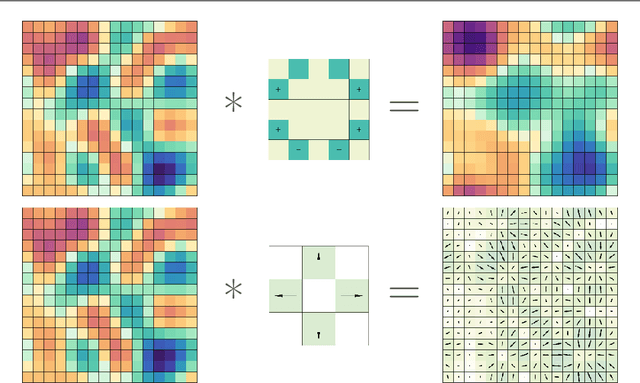

Convolutional neural networks and their ilk have been very successful for many learning tasks involving images. These methods assume that the input is a scalar image representing the intensity in each pixel, possibly in multiple channels for color images. In natural-science domains however, image-like data sets might have vectors (velocity, say), tensors (polarization, say), pseudovectors (magnetic field, say), or other geometric objects in each pixel. Treating the components of these objects as independent channels in a CNN neglects their structure entirely. Our formulation -- the GeometricImageNet -- combines a geometric generalization of convolution with outer products, tensor index contractions, and tensor index permutations to construct geometric-image functions of geometric images that use and benefit from the tensor structure. The framework permits, with a very simple adjustment, restriction to function spaces that are exactly equivariant to translations, discrete rotations, and reflections. We use representation theory to quantify the dimension of the space of equivariant polynomial functions on 2-dimensional vector images. We give partial results on the expressivity of GeometricImageNet on small images. In numerical experiments, we find that GeometricImageNet has good generalization for a small simulated physics system, even when trained with a small training set. We expect this tool will be valuable for scientific and engineering machine learning, for example in cosmology or ocean dynamics.
The passive symmetries of machine learning
Jan 31, 2023

Any representation of data involves arbitrary investigator choices. Because those choices are external to the data-generating process, each choice leads to an exact symmetry, corresponding to the group of transformations that takes one possible representation to another. These are the passive symmetries; they include coordinate freedom, gauge symmetry and units covariance, all of which have led to important results in physics. Our goal is to understand the implications of passive symmetries for machine learning: Which passive symmetries play a role (e.g., permutation symmetry in graph neural networks)? What are dos and don'ts in machine learning practice? We assay conditions under which passive symmetries can be implemented as group equivariances. We also discuss links to causal modeling, and argue that the implementation of passive symmetries is particularly valuable when the goal of the learning problem is to generalize out of sample. While this paper is purely conceptual, we believe that it can have a significant impact on helping machine learning make the transition that took place for modern physics in the first half of the Twentieth century.
Sketch-and-solve approaches to k-means clustering by semidefinite programming
Nov 28, 2022


We introduce a sketch-and-solve approach to speed up the Peng-Wei semidefinite relaxation of k-means clustering. When the data is appropriately separated we identify the k-means optimal clustering. Otherwise, our approach provides a high-confidence lower bound on the optimal k-means value. This lower bound is data-driven; it does not make any assumption on the data nor how it is generated. We provide code and an extensive set of numerical experiments where we use this approach to certify approximate optimality of clustering solutions obtained by k-means++.
Graph Neural Networks for Community Detection on Sparse Graphs
Nov 10, 2022
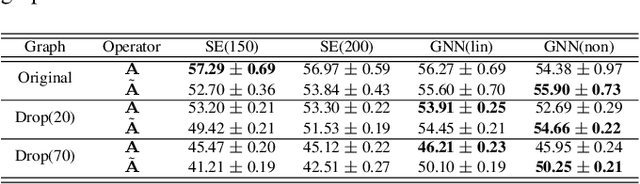
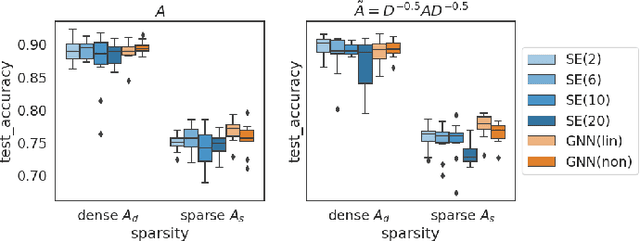
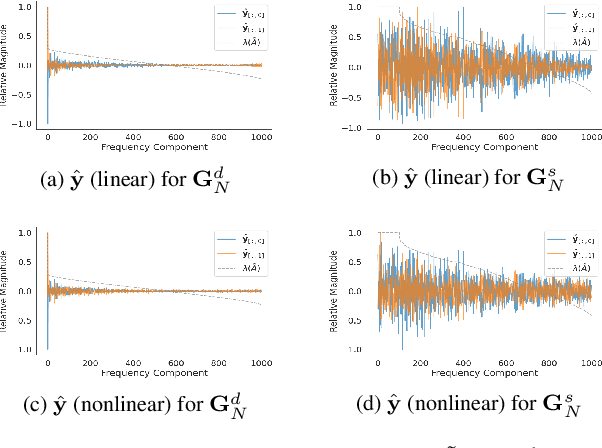
Spectral methods provide consistent estimators for community detection in dense graphs. However, their performance deteriorates as the graphs become sparser. In this work we consider a random graph model that can produce graphs at different levels of sparsity, and we show that graph neural networks can outperform spectral methods on sparse graphs. We illustrate the results with numerical examples in both synthetic and real graphs.
Deep Learning is Provably Robust to Symmetric Label Noise
Oct 26, 2022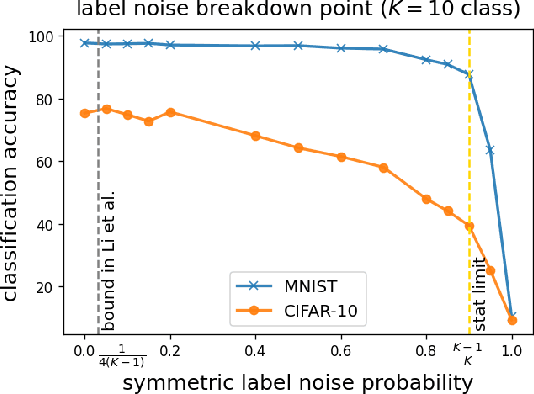
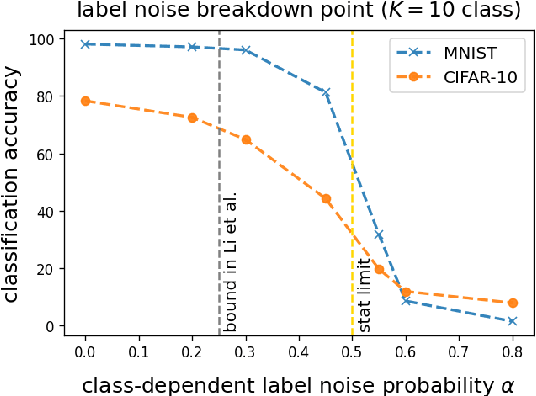
Deep neural networks (DNNs) are capable of perfectly fitting the training data, including memorizing noisy data. It is commonly believed that memorization hurts generalization. Therefore, many recent works propose mitigation strategies to avoid noisy data or correct memorization. In this work, we step back and ask the question: Can deep learning be robust against massive label noise without any mitigation? We provide an affirmative answer for the case of symmetric label noise: We find that certain DNNs, including under-parameterized and over-parameterized models, can tolerate massive symmetric label noise up to the information-theoretic threshold. By appealing to classical statistical theory and universal consistency of DNNs, we prove that for multiclass classification, $L_1$-consistent DNN classifiers trained under symmetric label noise can achieve Bayes optimality asymptotically if the label noise probability is less than $\frac{K-1}{K}$, where $K \ge 2$ is the number of classes. Our results show that for symmetric label noise, no mitigation is necessary for $L_1$-consistent estimators. We conjecture that for general label noise, mitigation strategies that make use of the noisy data will outperform those that ignore the noisy data.
Shuffled linear regression through graduated convex relaxation
Sep 30, 2022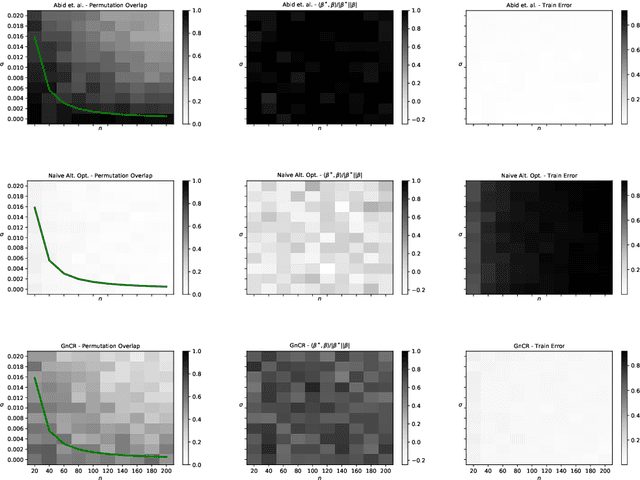

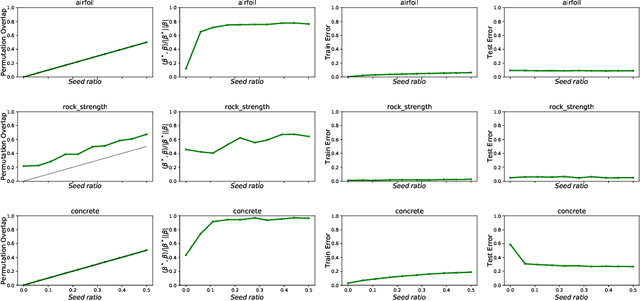
The shuffled linear regression problem aims to recover linear relationships in datasets where the correspondence between input and output is unknown. This problem arises in a wide range of applications including survey data, in which one needs to decide whether the anonymity of the responses can be preserved while uncovering significant statistical connections. In this work, we propose a novel optimization algorithm for shuffled linear regression based on a posterior-maximizing objective function assuming Gaussian noise prior. We compare and contrast our approach with existing methods on synthetic and real data. We show that our approach performs competitively while achieving empirical running-time improvements. Furthermore, we demonstrate that our algorithm is able to utilize the side information in the form of seeds, which recently came to prominence in related problems.
Equivariant maps from invariant functions
Sep 29, 2022In equivariant machine learning the idea is to restrict the learning to a hypothesis class where all the functions are equivariant with respect to some group action. Irreducible representations or invariant theory are typically used to parameterize the space of such functions. In this note, we explicate a general procedure, attributed to Malgrange, to express all polynomial maps between linear spaces that are equivariant with respect to the action of a group $G$, given a characterization of the invariant polynomials on a bigger space. The method also parametrizes smooth equivariant maps in the case that $G$ is a compact Lie group.