 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSri Harsha Dumpala
VISLA Benchmark: Evaluating Embedding Sensitivity to Semantic and Lexical Alterations
Apr 25, 2024
Despite their remarkable successes, state-of-the-art language models face challenges in grasping certain important semantic details. This paper introduces the VISLA (Variance and Invariance to Semantic and Lexical Alterations) benchmark, designed to evaluate the semantic and lexical understanding of language models. VISLA presents a 3-way semantic (in)equivalence task with a triplet of sentences associated with an image, to evaluate both vision-language models (VLMs) and unimodal language models (ULMs). An evaluation involving 34 VLMs and 20 ULMs reveals surprising difficulties in distinguishing between lexical and semantic variations. Spatial semantics encoded by language models also appear to be highly sensitive to lexical information. Notably, text encoders of VLMs demonstrate greater sensitivity to semantic and lexical variations than unimodal text encoders. Our contributions include the unification of image-to-text and text-to-text retrieval tasks, an off-the-shelf evaluation without fine-tuning, and assessing LMs' semantic (in)variance in the presence of lexical alterations. The results highlight strengths and weaknesses across diverse vision and unimodal language models, contributing to a deeper understanding of their capabilities. % VISLA enables a rigorous evaluation, shedding light on language models' capabilities in handling semantic and lexical nuances. Data and code will be made available at https://github.com/Sri-Harsha/visla_benchmark.
Test-Time Training for Depression Detection
Apr 07, 2024Previous works on depression detection use datasets collected in similar environments to train and test the models. In practice, however, the train and test distributions cannot be guaranteed to be identical. Distribution shifts can be introduced due to variations such as recording environment (e.g., background noise) and demographics (e.g., gender, age, etc). Such distributional shifts can surprisingly lead to severe performance degradation of the depression detection models. In this paper, we analyze the application of test-time training (TTT) to improve robustness of models trained for depression detection. When compared to regular testing of the models, we find TTT can significantly improve the robustness of the model under a variety of distributional shifts introduced due to: (a) background-noise, (b) gender-bias, and (c) data collection and curation procedure (i.e., train and test samples are from separate datasets).
Test-Time Training for Speech
Sep 28, 2023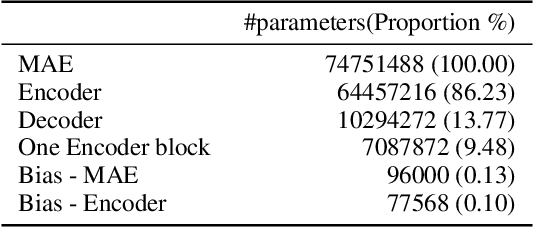
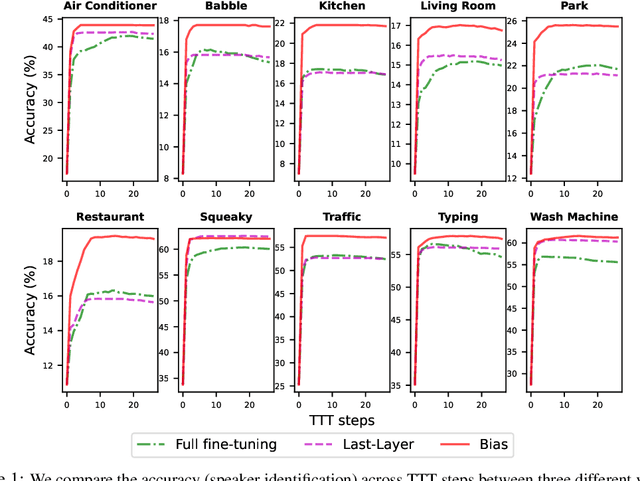
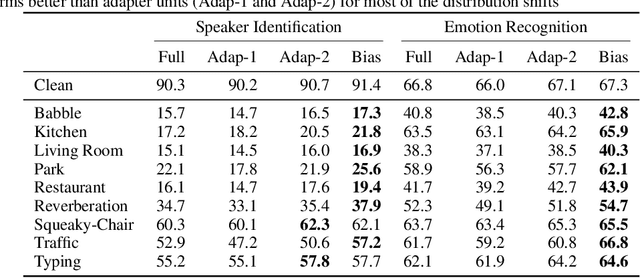
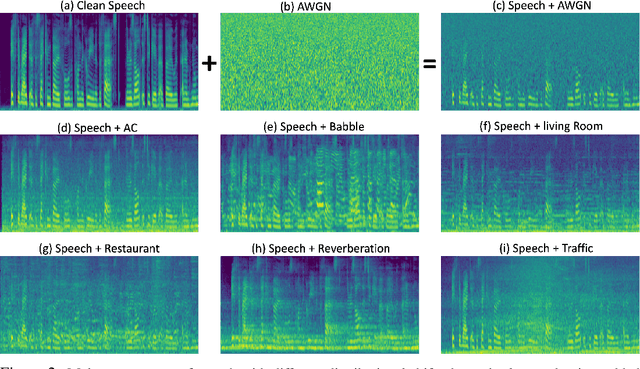
In this paper, we study the application of Test-Time Training (TTT) as a solution to handling distribution shifts in speech applications. In particular, we introduce distribution-shifts to the test datasets of standard speech-classification tasks -- for example, speaker-identification and emotion-detection -- and explore how Test-Time Training (TTT) can help adjust to the distribution-shift. In our experiments that include distribution shifts due to background noise and natural variations in speech such as gender and age, we identify some key-challenges with TTT including sensitivity to optimization hyperparameters (e.g., number of optimization steps and subset of parameters chosen for TTT) and scalability (e.g., as each example gets its own set of parameters, TTT is not scalable). Finally, we propose using BitFit -- a parameter-efficient fine-tuning algorithm proposed for text applications that only considers the bias parameters for fine-tuning -- as a solution to the aforementioned challenges and demonstrate that it is consistently more stable than fine-tuning all the parameters of the model.
Training Diffusion Classifiers with Denoising Assistance
Jun 15, 2023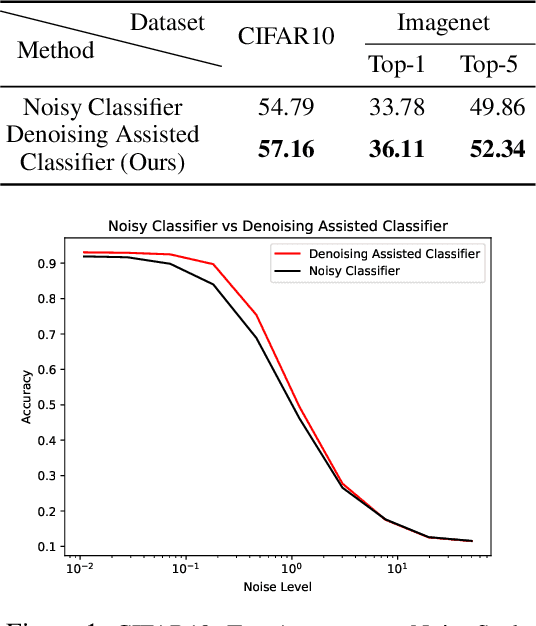



Score-matching and diffusion models have emerged as state-of-the-art generative models for both conditional and unconditional generation. Classifier-guided diffusion models are created by training a classifier on samples obtained from the forward-diffusion process (i.e., from data to noise). In this paper, we propose denoising-assisted (DA) classifiers wherein the diffusion classifier is trained using both noisy and denoised examples as simultaneous inputs to the model. We differentiate between denoising-assisted (DA) classifiers and noisy classifiers, which are diffusion classifiers that are only trained on noisy examples. Our experiments on Cifar10 and Imagenet show that DA-classifiers improve over noisy classifiers both quantitatively in terms of generalization to test data and qualitatively in terms of perceptually-aligned classifier-gradients and generative modeling metrics. Finally, we describe a semi-supervised framework for training diffusion classifiers and our experiments, that also include positive-unlabeled settings, demonstrate improved generalization of DA-classifiers over noisy classifiers.
Musical Speech: A Transformer-based Composition Tool
Aug 02, 2021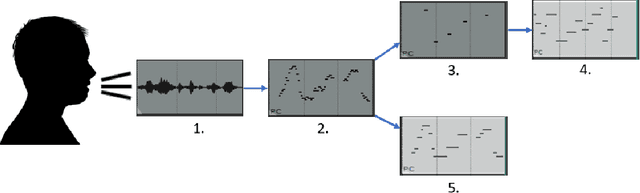
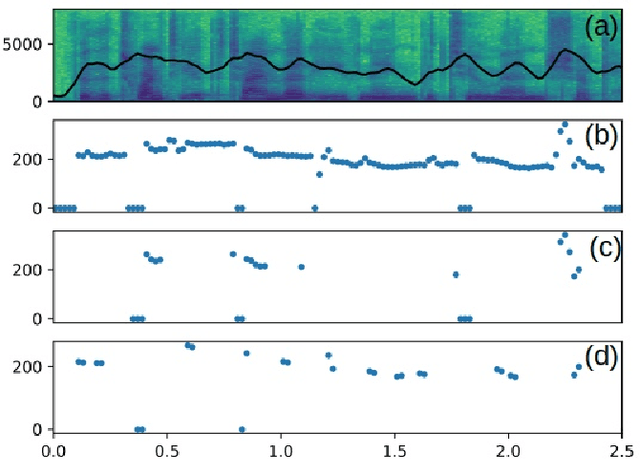
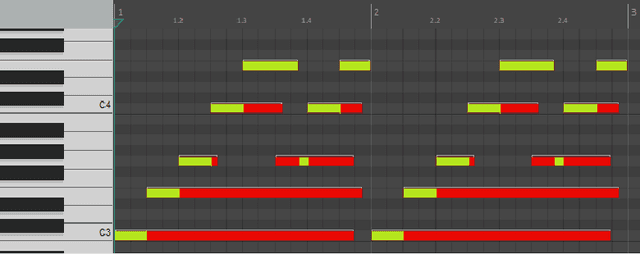
In this paper, we propose a new compositional tool that will generate a musical outline of speech recorded/provided by the user for use as a musical building block in their compositions. The tool allows any user to use their own speech to generate musical material, while still being able to hear the direct connection between their recorded speech and the resulting music. The tool is built on our proposed pipeline. This pipeline begins with speech-based signal processing, after which some simple musical heuristics are applied, and finally these pre-processed signals are passed through Transformer models trained on new musical tasks. We illustrate the effectiveness of our pipeline -- which does not require a paired dataset for training -- through examples of music created by musicians making use of our tool.
Significance of Speaker Embeddings and Temporal Context for Depression Detection
Jul 24, 2021



Depression detection from speech has attracted a lot of attention in recent years. However, the significance of speaker-specific information in depression detection has not yet been explored. In this work, we analyze the significance of speaker embeddings for the task of depression detection from speech. Experimental results show that the speaker embeddings provide important cues to achieve state-of-the-art performance in depression detection. We also show that combining conventional OpenSMILE and COVAREP features, which carry complementary information, with speaker embeddings further improves the depression detection performance. The significance of temporal context in the training of deep learning models for depression detection is also analyzed in this paper.
A Cycle-GAN Approach to Model Natural Perturbations in Speech for ASR Applications
Dec 18, 2019



Naturally introduced perturbations in audio signal, caused by emotional and physical states of the speaker, can significantly degrade the performance of Automatic Speech Recognition (ASR) systems. In this paper, we propose a front-end based on Cycle-Consistent Generative Adversarial Network (CycleGAN) which transforms naturally perturbed speech into normal speech, and hence improves the robustness of an ASR system. The CycleGAN model is trained on non-parallel examples of perturbed and normal speech. Experiments on spontaneous laughter-speech and creaky-speech datasets show that the performance of four different ASR systems improve by using speech obtained from CycleGAN based front-end, as compared to directly using the original perturbed speech. Visualization of the features of the laughter perturbed speech and those generated by the proposed front-end further demonstrates the effectiveness of our approach.
A Novel Approach for Effective Learning in Low Resourced Scenarios
Dec 15, 2017

Deep learning based discriminative methods, being the state-of-the-art machine learning techniques, are ill-suited for learning from lower amounts of data. In this paper, we propose a novel framework, called simultaneous two sample learning (s2sL), to effectively learn the class discriminative characteristics, even from very low amount of data. In s2sL, more than one sample (here, two samples) are simultaneously considered to both, train and test the classifier. We demonstrate our approach for speech/music discrimination and emotion classification through experiments. Further, we also show the effectiveness of s2sL approach for classification in low-resource scenario, and for imbalanced data.
k-FFNN: A priori knowledge infused Feed-forward Neural Networks
Apr 24, 2017



Recurrent neural network (RNN) are being extensively used over feed-forward neural networks (FFNN) because of their inherent capability to capture temporal relationships that exist in the sequential data such as speech. This aspect of RNN is advantageous especially when there is no a priori knowledge about the temporal correlations within the data. However, RNNs require large amount of data to learn these temporal correlations, limiting their advantage in low resource scenarios. It is not immediately clear (a) how a priori temporal knowledge can be used in a FFNN architecture (b) how a FFNN performs when provided with this knowledge about temporal correlations (assuming available) during training. The objective of this paper is to explore k-FFNN, namely a FFNN architecture that can incorporate the a priori knowledge of the temporal relationships within the data sequence during training and compare k-FFNN performance with RNN in a low resource scenario. We evaluate the performance of k-FFNN and RNN by extensive experimentation on MediaEval 2016 audio data ("Emotional Impact of Movies" task). Experimental results show that the performance of k-FFNN is comparable to RNN, and in some scenarios k-FFNN performs better than RNN when temporal knowledge is injected into FFNN architecture. The main contributions of this paper are (a) fusing a priori knowledge into FFNN architecture to construct a k-FFNN and (b) analyzing the performance of k-FFNN with respect to RNN for different size of training data.