 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSrikanth Ronanki
Retrieve and Copy: Scaling ASR Personalization to Large Catalogs
Nov 14, 2023




Personalization of automatic speech recognition (ASR) models is a widely studied topic because of its many practical applications. Most recently, attention-based contextual biasing techniques are used to improve the recognition of rare words and domain specific entities. However, due to performance constraints, the biasing is often limited to a few thousand entities, restricting real-world usability. To address this, we first propose a "Retrieve and Copy" mechanism to improve latency while retaining the accuracy even when scaled to a large catalog. We also propose a training strategy to overcome the degradation in recall at such scale due to an increased number of confusing entities. Overall, our approach achieves up to 6% more Word Error Rate reduction (WERR) and 3.6% absolute improvement in F1 when compared to a strong baseline. Our method also allows for large catalog sizes of up to 20K without significantly affecting WER and F1-scores, while achieving at least 20% inference speedup per acoustic frame.
Generalized zero-shot audio-to-intent classification
Nov 04, 2023Spoken language understanding systems using audio-only data are gaining popularity, yet their ability to handle unseen intents remains limited. In this study, we propose a generalized zero-shot audio-to-intent classification framework with only a few sample text sentences per intent. To achieve this, we first train a supervised audio-to-intent classifier by making use of a self-supervised pre-trained model. We then leverage a neural audio synthesizer to create audio embeddings for sample text utterances and perform generalized zero-shot classification on unseen intents using cosine similarity. We also propose a multimodal training strategy that incorporates lexical information into the audio representation to improve zero-shot performance. Our multimodal training approach improves the accuracy of zero-shot intent classification on unseen intents of SLURP by 2.75% and 18.2% for the SLURP and internal goal-oriented dialog datasets, respectively, compared to audio-only training.
DCTX-Conformer: Dynamic context carry-over for low latency unified streaming and non-streaming Conformer
Jun 13, 2023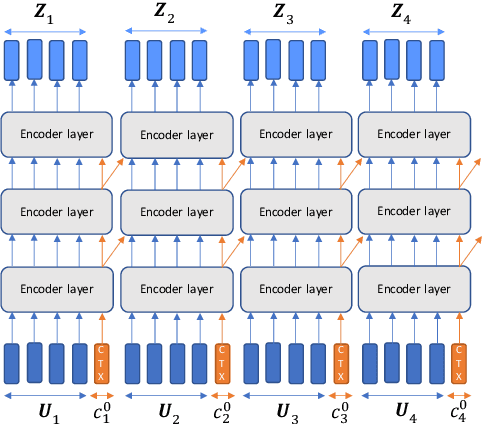

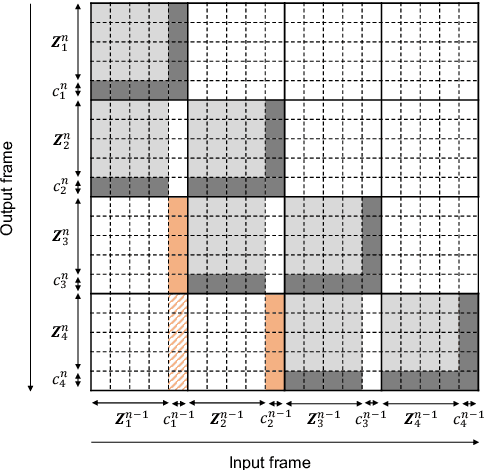
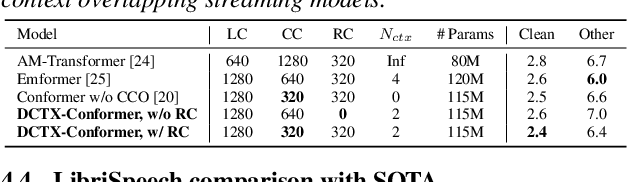
Conformer-based end-to-end models have become ubiquitous these days and are commonly used in both streaming and non-streaming automatic speech recognition (ASR). Techniques like dual-mode and dynamic chunk training helped unify streaming and non-streaming systems. However, there remains a performance gap between streaming with a full and limited past context. To address this issue, we propose the integration of a novel dynamic contextual carry-over mechanism in a state-of-the-art (SOTA) unified ASR system. Our proposed dynamic context Conformer (DCTX-Conformer) utilizes a non-overlapping contextual carry-over mechanism that takes into account both the left context of a chunk and one or more preceding context embeddings. We outperform the SOTA by a relative 25.0% word error rate, with a negligible latency impact due to the additional context embeddings.
Dynamic Chunk Convolution for Unified Streaming and Non-Streaming Conformer ASR
Apr 25, 2023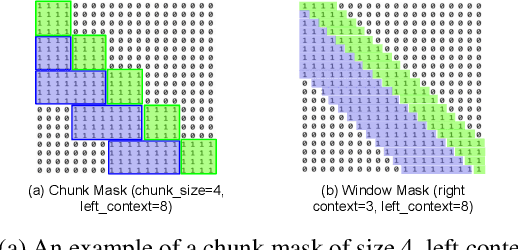
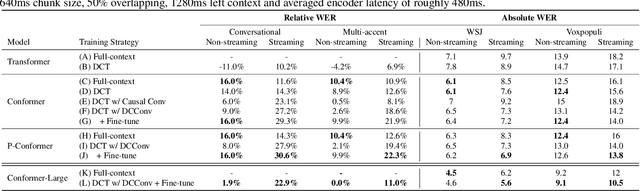
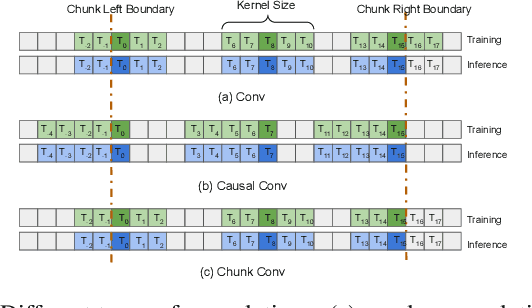
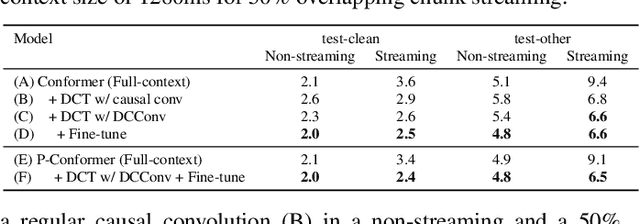
Recently, there has been an increasing interest in unifying streaming and non-streaming speech recognition models to reduce development, training and deployment cost. The best-known approaches rely on either window-based or dynamic chunk-based attention strategy and causal convolutions to minimize the degradation due to streaming. However, the performance gap still remains relatively large between non-streaming and a full-contextual model trained independently. To address this, we propose a dynamic chunk-based convolution replacing the causal convolution in a hybrid Connectionist Temporal Classification (CTC)-Attention Conformer architecture. Additionally, we demonstrate further improvements through initialization of weights from a full-contextual model and parallelization of the convolution and self-attention modules. We evaluate our models on the open-source Voxpopuli, LibriSpeech and in-house conversational datasets. Overall, our proposed model reduces the degradation of the streaming mode over the non-streaming full-contextual model from 41.7% and 45.7% to 16.7% and 26.2% on the LibriSpeech test-clean and test-other datasets respectively, while improving by a relative 15.5% WER over the previous state-of-the-art unified model.
Device Directedness with Contextual Cues for Spoken Dialog Systems
Nov 23, 2022
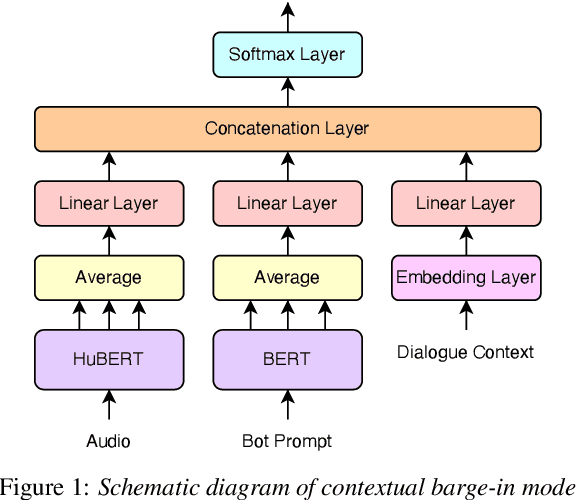
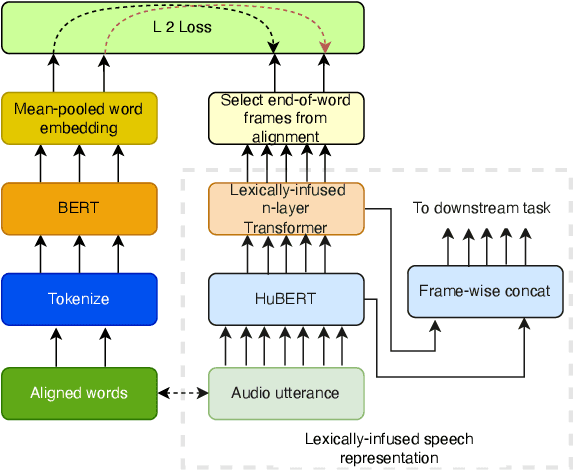

In this work, we define barge-in verification as a supervised learning task where audio-only information is used to classify user spoken dialogue into true and false barge-ins. Following the success of pre-trained models, we use low-level speech representations from a self-supervised representation learning model for our downstream classification task. Further, we propose a novel technique to infuse lexical information directly into speech representations to improve the domain-specific language information implicitly learned during pre-training. Experiments conducted on spoken dialog data show that our proposed model trained to validate barge-in entirely from speech representations is faster by 38% relative and achieves 4.5% relative F1 score improvement over a baseline LSTM model that uses both audio and Automatic Speech Recognition (ASR) 1-best hypotheses. On top of this, our best proposed model with lexically infused representations along with contextual features provides a further relative improvement of 5.7% in the F1 score but only 22% faster than the baseline.
Personalization of CTC Speech Recognition Models
Oct 18, 2022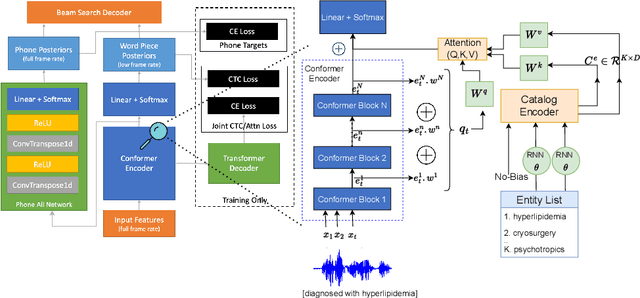

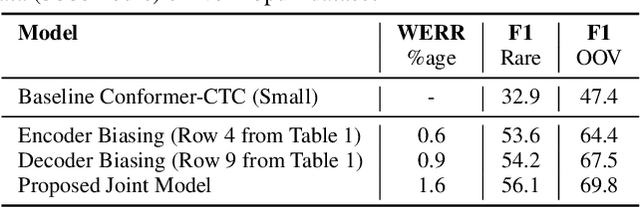
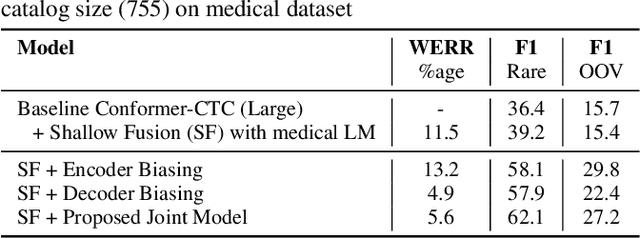
End-to-end speech recognition models trained using joint Connectionist Temporal Classification (CTC)-Attention loss have gained popularity recently. In these models, a non-autoregressive CTC decoder is often used at inference time due to its speed and simplicity. However, such models are hard to personalize because of their conditional independence assumption that prevents output tokens from previous time steps to influence future predictions. To tackle this, we propose a novel two-way approach that first biases the encoder with attention over a predefined list of rare long-tail and out-of-vocabulary (OOV) words and then uses dynamic boosting and phone alignment network during decoding to further bias the subword predictions. We evaluate our approach on open-source VoxPopuli and in-house medical datasets to showcase a 60% improvement in F1 score on domain-specific rare words over a strong CTC baseline.
"What's The Context?" : Long Context NLM Adaptation for ASR Rescoring in Conversational Agents
Apr 21, 2021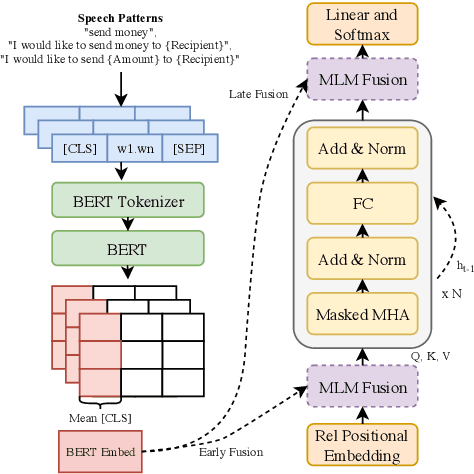

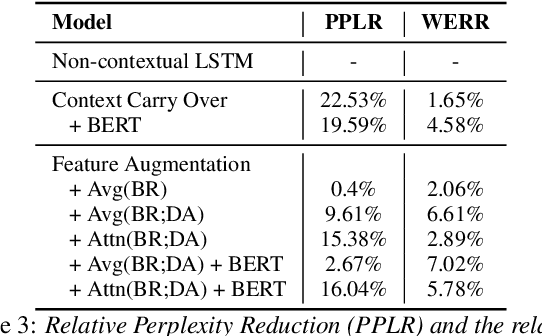
Neural Language Models (NLM), when trained and evaluated with context spanning multiple utterances, have been shown to consistently outperform both conventional n-gram language models and NLMs that use limited context. In this paper, we investigate various techniques to incorporate turn based context history into both recurrent (LSTM) and Transformer-XL based NLMs. For recurrent based NLMs, we explore context carry over mechanism and feature based augmentation, where we incorporate other forms of contextual information such as bot response and system dialogue acts as classified by a Natural Language Understanding (NLU) model. To mitigate the sharp nearby, fuzzy far away problem with contextual NLM, we propose the use of attention layer over lexical metadata to improve feature based augmentation. Additionally, we adapt our contextual NLM towards user provided on-the-fly speech patterns by leveraging encodings from a large pre-trained masked language model and performing fusion with a Transformer-XL based NLM. We test our proposed models using N-best rescoring of ASR hypotheses of task-oriented dialogues and also evaluate on downstream NLU tasks such as intent classification and slot labeling. The best performing model shows a relative WER between 1.6% and 9.1% and a slot labeling F1 score improvement of 4% over non-contextual baselines.
Transformer-Transducers for Code-Switched Speech Recognition
Nov 30, 2020
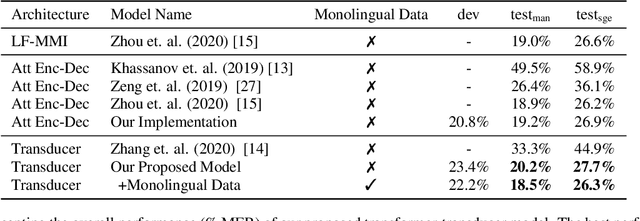


We live in a world where 60% of the population can speak two or more languages fluently. Members of these communities constantly switch between languages when having a conversation. As automatic speech recognition (ASR) systems are being deployed to the real-world, there is a need for practical systems that can handle multiple languages both within an utterance or across utterances. In this paper, we present an end-to-end ASR system using a transformer-transducer model architecture for code-switched speech recognition. We propose three modifications over the vanilla model in order to handle various aspects of code-switching. First, we introduce two auxiliary loss functions to handle the low-resource scenario of code-switching. Second, we propose a novel mask-based training strategy with language ID information to improve the label encoder training towards intra-sentential code-switching. Finally, we propose a multi-label/multi-audio encoder structure to leverage the vast monolingual speech corpora towards code-switching. We demonstrate the efficacy of our proposed approaches on the SEAME dataset, a public Mandarin-English code-switching corpus, achieving a mixed error rate of 18.5% and 26.3% on test_man and test_sge sets respectively.
Multimodal Semi-supervised Learning Framework for Punctuation Prediction in Conversational Speech
Aug 03, 2020



In this work, we explore a multimodal semi-supervised learning approach for punctuation prediction by learning representations from large amounts of unlabelled audio and text data. Conventional approaches in speech processing typically use forced alignment to encoder per frame acoustic features to word level features and perform multimodal fusion of the resulting acoustic and lexical representations. As an alternative, we explore attention based multimodal fusion and compare its performance with forced alignment based fusion. Experiments conducted on the Fisher corpus show that our proposed approach achieves ~6-9% and ~3-4% absolute improvement (F1 score) over the baseline BLSTM model on reference transcripts and ASR outputs respectively. We further improve the model robustness to ASR errors by performing data augmentation with N-best lists which achieves up to an additional ~2-6% improvement on ASR outputs. We also demonstrate the effectiveness of semi-supervised learning approach by performing ablation study on various sizes of the corpus. When trained on 1 hour of speech and text data, the proposed model achieved ~9-18% absolute improvement over baseline model.
Robust Prediction of Punctuation and Truecasing for Medical ASR
Jul 11, 2020



Automatic speech recognition (ASR) systems in the medical domain that focus on transcribing clinical dictations and doctor-patient conversations often pose many challenges due to the complexity of the domain. ASR output typically undergoes automatic punctuation to enable users to speak naturally, without having to vocalise awkward and explicit punctuation commands, such as "period", "add comma" or "exclamation point", while truecasing enhances user readability and improves the performance of downstream NLP tasks. This paper proposes a conditional joint modeling framework for prediction of punctuation and truecasing using pretrained masked language models such as BERT, BioBERT and RoBERTa. We also present techniques for domain and task specific adaptation by fine-tuning masked language models with medical domain data. Finally, we improve the robustness of the model against common errors made in ASR by performing data augmentation. Experiments performed on dictation and conversational style corpora show that our proposed model achieves ~5% absolute improvement on ground truth text and ~10% improvement on ASR outputs over baseline models under F1 metric.