 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStefan Jansen
Voice EHR: Introducing Multimodal Audio Data for Health
Apr 02, 2024
Large AI models trained on audio data may have the potential to rapidly classify patients, enhancing medical decision-making and potentially improving outcomes through early detection. Existing technologies depend on limited datasets using expensive recording equipment in high-income, English-speaking countries. This challenges deployment in resource-constrained, high-volume settings where audio data may have a profound impact. This report introduces a novel data type and a corresponding collection system that captures health data through guided questions using only a mobile/web application. This application ultimately results in an audio electronic health record (voice EHR) which may contain complex biomarkers of health from conventional voice/respiratory features, speech patterns, and language with semantic meaning - compensating for the typical limitations of unimodal clinical datasets. This report introduces a consortium of partners for global work, presents the application used for data collection, and showcases the potential of informative voice EHR to advance the scalability and diversity of audio AI.
Word and Phrase Translation with word2vec
Apr 24, 2018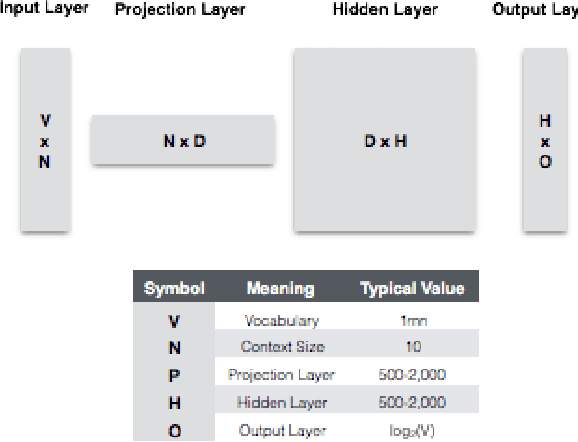

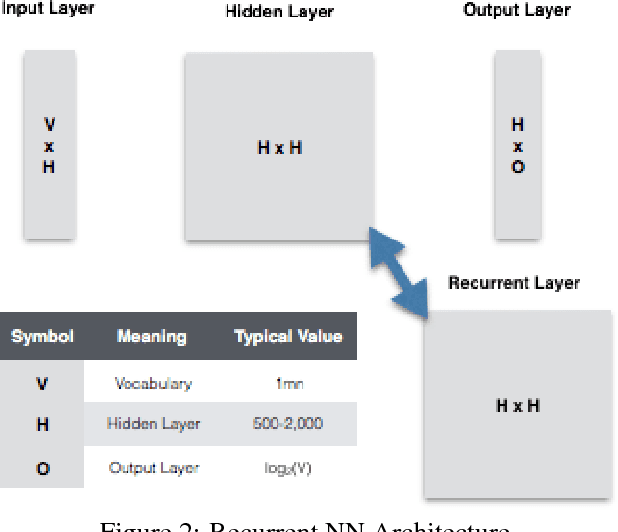
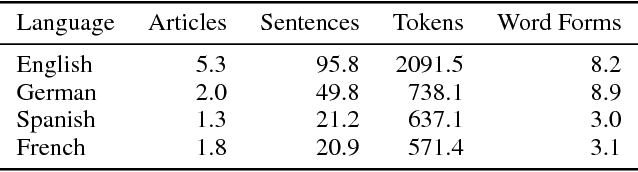
Word and phrase tables are key inputs to machine translations, but costly to produce. New unsupervised learning methods represent words and phrases in a high-dimensional vector space, and these monolingual embeddings have been shown to encode syntactic and semantic relationships between language elements. The information captured by these embeddings can be exploited for bilingual translation by learning a transformation matrix that allows matching relative positions across two monolingual vector spaces. This method aims to identify high-quality candidates for word and phrase translation more cost-effectively from unlabeled data. This paper expands the scope of previous attempts of bilingual translation to four languages (English, German, Spanish, and French). It shows how to process the source data, train a neural network to learn the high-dimensional embeddings for individual languages and expands the framework for testing their quality beyond the English language. Furthermore, it shows how to learn bilingual transformation matrices and obtain candidates for word and phrase translation, and assess their quality.