 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteven James
MinePlanner: A Benchmark for Long-Horizon Planning in Large Minecraft Worlds
Dec 20, 2023
We propose a new benchmark for planning tasks based on the Minecraft game. Our benchmark contains 45 tasks overall, but also provides support for creating both propositional and numeric instances of new Minecraft tasks automatically. We benchmark numeric and propositional planning systems on these tasks, with results demonstrating that state-of-the-art planners are currently incapable of dealing with many of the challenges advanced by our new benchmark, such as scaling to instances with thousands of objects. Based on these results, we identify areas of improvement for future planners. Our framework is made available at https://github.com/IretonLiu/mine-pddl/.
Counting Reward Automata: Sample Efficient Reinforcement Learning Through the Exploitation of Reward Function Structure
Dec 18, 2023We present counting reward automata-a finite state machine variant capable of modelling any reward function expressible as a formal language. Unlike previous approaches, which are limited to the expression of tasks as regular languages, our framework allows for tasks described by unrestricted grammars. We prove that an agent equipped with such an abstract machine is able to solve a larger set of tasks than those utilising current approaches. We show that this increase in expressive power does not come at the cost of increased automaton complexity. A selection of learning algorithms are presented which exploit automaton structure to improve sample efficiency. We show that the state machines required in our formulation can be specified from natural language task descriptions using large language models. Empirical results demonstrate that our method outperforms competing approaches in terms of sample efficiency, automaton complexity, and task completion.
Dynamics Generalisation in Reinforcement Learning via Adaptive Context-Aware Policies
Oct 25, 2023While reinforcement learning has achieved remarkable successes in several domains, its real-world application is limited due to many methods failing to generalise to unfamiliar conditions. In this work, we consider the problem of generalising to new transition dynamics, corresponding to cases in which the environment's response to the agent's actions differs. For example, the gravitational force exerted on a robot depends on its mass and changes the robot's mobility. Consequently, in such cases, it is necessary to condition an agent's actions on extrinsic state information and pertinent contextual information reflecting how the environment responds. While the need for context-sensitive policies has been established, the manner in which context is incorporated architecturally has received less attention. Thus, in this work, we present an investigation into how context information should be incorporated into behaviour learning to improve generalisation. To this end, we introduce a neural network architecture, the Decision Adapter, which generates the weights of an adapter module and conditions the behaviour of an agent on the context information. We show that the Decision Adapter is a useful generalisation of a previously proposed architecture and empirically demonstrate that it results in superior generalisation performance compared to previous approaches in several environments. Beyond this, the Decision Adapter is more robust to irrelevant distractor variables than several alternative methods.
LLMatic: Neural Architecture Search via Large Language Models and Quality-Diversity Optimization
Jun 01, 2023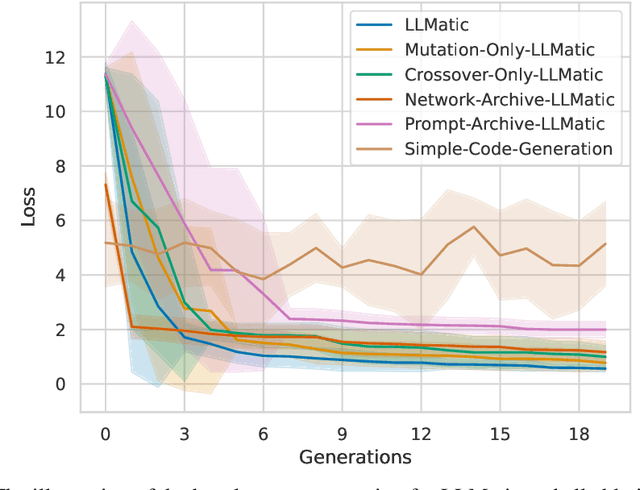
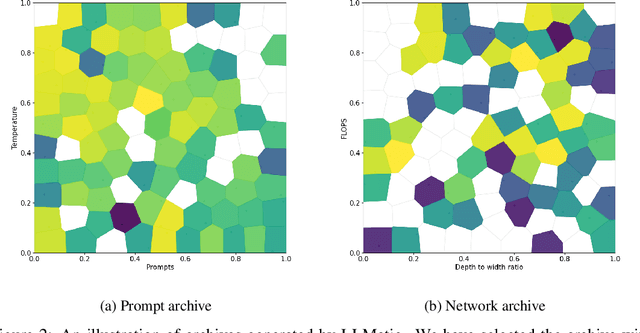
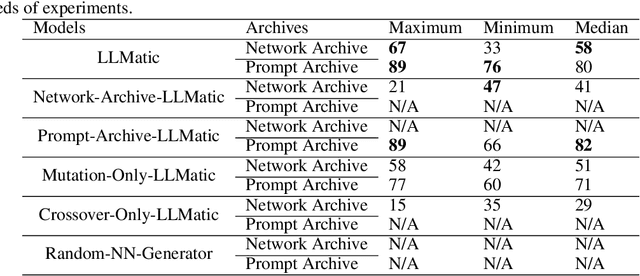
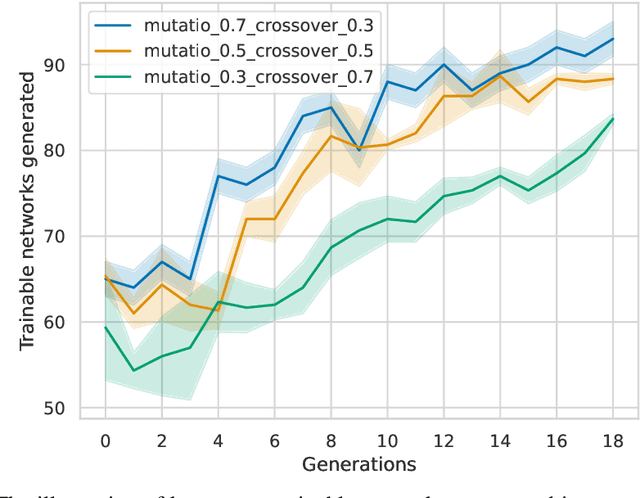
Large Language Models (LLMs) have emerged as powerful tools capable of accomplishing a broad spectrum of tasks. Their abilities span numerous areas, and one area where they have made a significant impact is in the domain of code generation. In this context, we view LLMs as mutation and crossover tools. Meanwhile, Quality-Diversity (QD) algorithms are known to discover diverse and robust solutions. By merging the code-generating abilities of LLMs with the diversity and robustness of QD solutions, we introduce LLMatic, a Neural Architecture Search (NAS) algorithm. While LLMs struggle to conduct NAS directly through prompts, LLMatic uses a procedural approach, leveraging QD for prompts and network architecture to create diverse and highly performant networks. We test LLMatic on the CIFAR-10 image classification benchmark, demonstrating that it can produce competitive networks with just $2,000$ searches, even without prior knowledge of the benchmark domain or exposure to any previous top-performing models for the benchmark.
ROSARL: Reward-Only Safe Reinforcement Learning
May 31, 2023
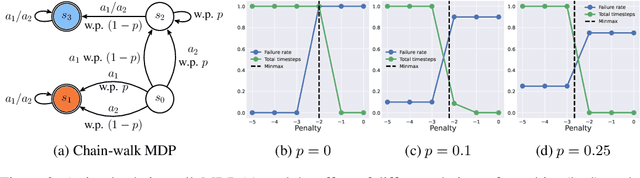
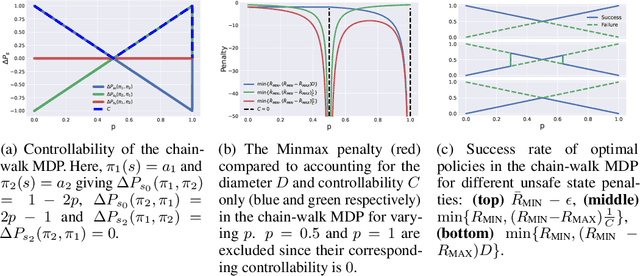

An important problem in reinforcement learning is designing agents that learn to solve tasks safely in an environment. A common solution is for a human expert to define either a penalty in the reward function or a cost to be minimised when reaching unsafe states. However, this is non-trivial, since too small a penalty may lead to agents that reach unsafe states, while too large a penalty increases the time to convergence. Additionally, the difficulty in designing reward or cost functions can increase with the complexity of the problem. Hence, for a given environment with a given set of unsafe states, we are interested in finding the upper bound of rewards at unsafe states whose optimal policies minimise the probability of reaching those unsafe states, irrespective of task rewards. We refer to this exact upper bound as the "Minmax penalty", and show that it can be obtained by taking into account both the controllability and diameter of an environment. We provide a simple practical model-free algorithm for an agent to learn this Minmax penalty while learning the task policy, and demonstrate that using it leads to agents that learn safe policies in high-dimensional continuous control environments.
Hierarchically Composing Level Generators for the Creation of Complex Structures
Feb 03, 2023
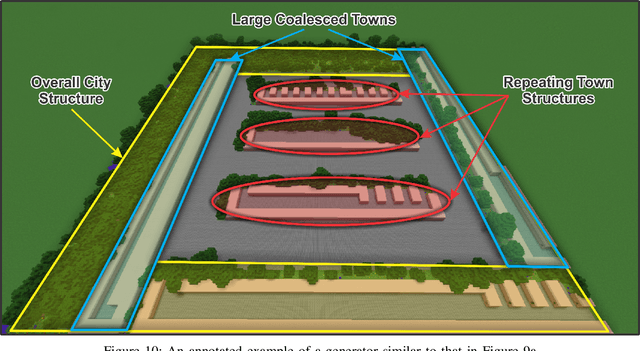

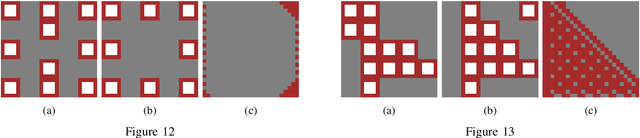
Procedural content generation (PCG) is a growing field, with numerous applications in the video game industry, and great potential to help create better games at a fraction of the cost of manual creation. However, much of the work in PCG is focused on generating relatively straightforward levels in simple games, as it is challenging to design an optimisable objective function for complex settings. This limits the applicability of PCG to more complex and modern titles, hindering its adoption in industry. Our work aims to address this limitation by introducing a compositional level generation method, which recursively composes simple, low-level generators together to construct large and complex creations. This approach allows for easily-optimisable objectives and the ability to design a complex structure in an interpretable way by referencing lower-level components. We empirically demonstrate that our method outperforms a non-compositional baseline by more accurately satisfying a designer's functional requirements in several tasks. Finally, we provide a qualitative showcase (in Minecraft) illustrating the large and complex, but still coherent, structures that were generated using simple base generators.
Augmentative Topology Agents For Open-Ended Learning
Oct 20, 2022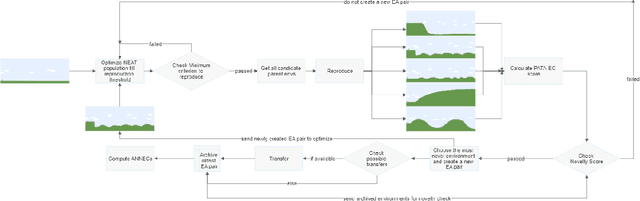
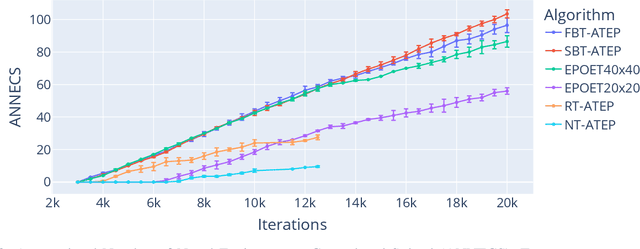
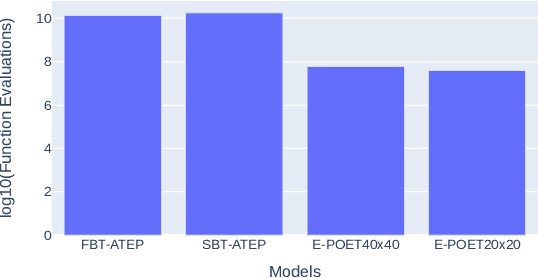
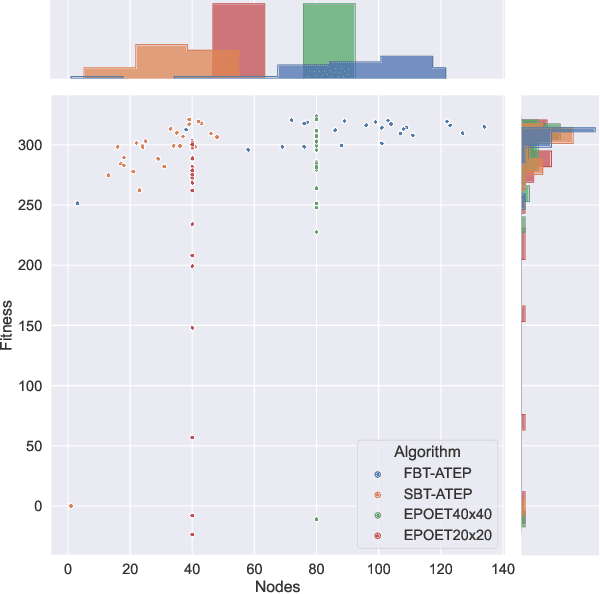
In this work, we tackle the problem of open-ended learning by introducing a method that simultaneously evolves agents and increasingly challenging environments. Unlike previous open-ended approaches that optimize agents using a fixed neural network topology, we hypothesize that generalization can be improved by allowing agents' controllers to become more complex as they encounter more difficult environments. Our method, Augmentative Topology EPOET (ATEP), extends the Enhanced Paired Open-Ended Trailblazer (EPOET) algorithm by allowing agents to evolve their own neural network structures over time, adding complexity and capacity as necessary. Empirical results demonstrate that ATEP results in general agents capable of solving more environments than a fixed-topology baseline. We also investigate mechanisms for transferring agents between environments and find that a species-based approach further improves the performance and generalization of agents.
Combining Evolutionary Search with Behaviour Cloning for Procedurally Generated Content
Jul 29, 2022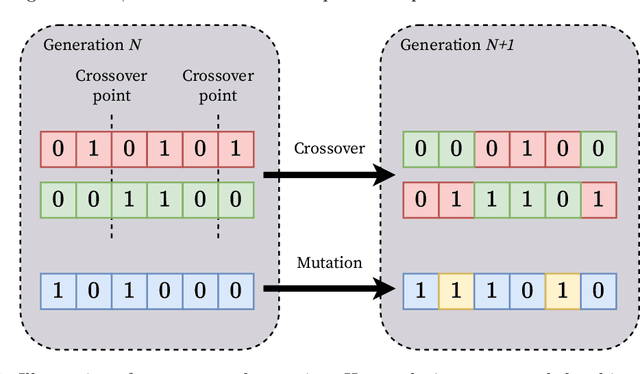

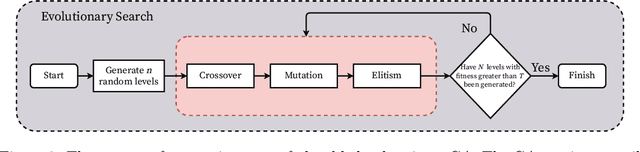

In this work, we consider the problem of procedural content generation for video game levels. Prior approaches have relied on evolutionary search (ES) methods capable of generating diverse levels, but this generation procedure is slow, which is problematic in real-time settings. Reinforcement learning (RL) has also been proposed to tackle the same problem, and while level generation is fast, training time can be prohibitively expensive. We propose a framework to tackle the procedural content generation problem that combines the best of ES and RL. In particular, our approach first uses ES to generate a sequence of levels evolved over time, and then uses behaviour cloning to distil these levels into a policy, which can then be queried to produce new levels quickly. We apply our approach to a maze game and Super Mario Bros, with our results indicating that our approach does in fact decrease the time required for level generation, especially when an increasing number of valid levels are required.
World Value Functions: Knowledge Representation for Learning and Planning
Jun 23, 2022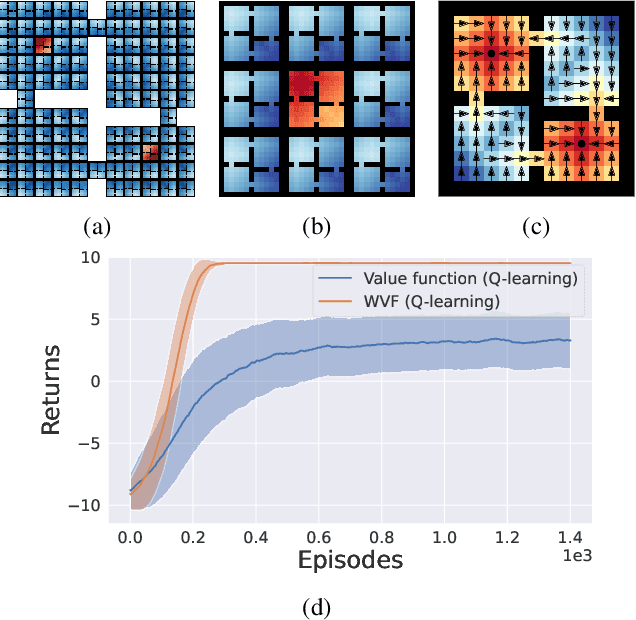

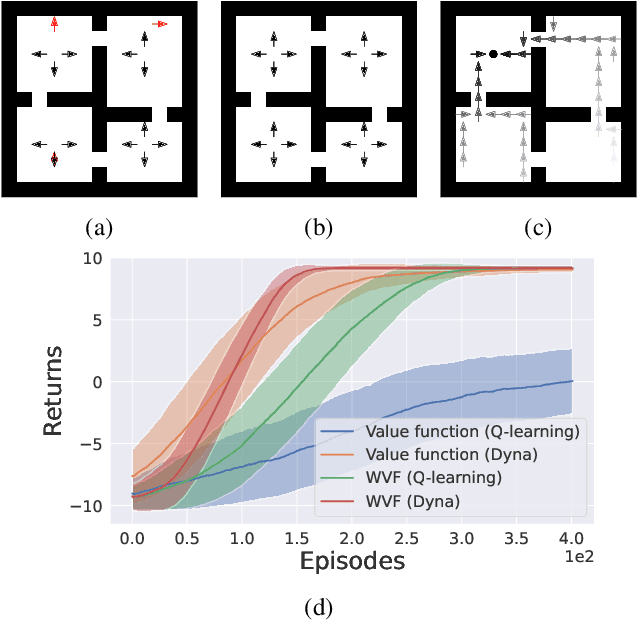
We propose world value functions (WVFs), a type of goal-oriented general value function that represents how to solve not just a given task, but any other goal-reaching task in an agent's environment. This is achieved by equipping an agent with an internal goal space defined as all the world states where it experiences a terminal transition. The agent can then modify the standard task rewards to define its own reward function, which provably drives it to learn how to achieve all reachable internal goals, and the value of doing so in the current task. We demonstrate two key benefits of WVFs in the context of learning and planning. In particular, given a learned WVF, an agent can compute the optimal policy in a new task by simply estimating the task's reward function. Furthermore, we show that WVFs also implicitly encode the transition dynamics of the environment, and so can be used to perform planning. Experimental results show that WVFs can be learned faster than regular value functions, while their ability to infer the environment's dynamics can be used to integrate learning and planning methods to further improve sample efficiency.
Skill Machines: Temporal Logic Composition in Reinforcement Learning
May 25, 2022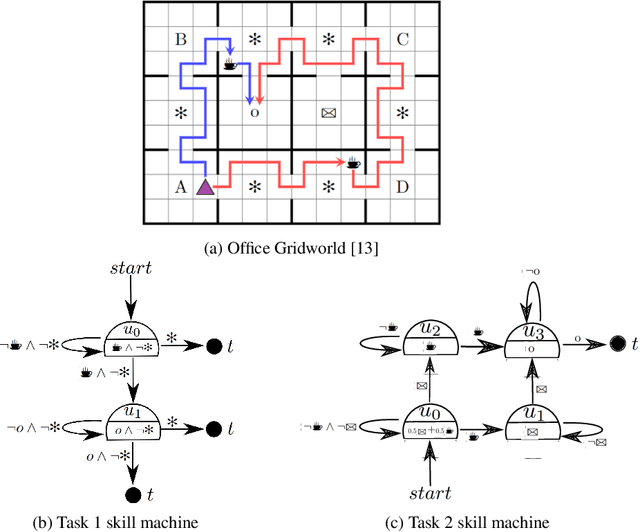

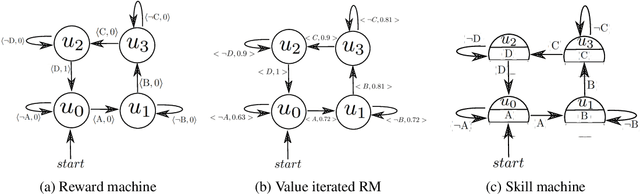

A major challenge in reinforcement learning is specifying tasks in a manner that is both interpretable and verifiable. One common approach is to specify tasks through reward machines -- finite state machines that encode the task to be solved. We introduce skill machines, a representation that can be learned directly from these reward machines that encode the solution to such tasks. We propose a framework where an agent first learns a set of base skills in a reward-free setting, and then combines these skills with the learned skill machine to produce composite behaviours specified by any regular language, such as linear temporal logics. This provides the agent with the ability to map from complex logical task specifications to near-optimal behaviours zero-shot. We demonstrate our approach in both a tabular and high-dimensional video game environment, where an agent is faced with several of these complex, long-horizon tasks. Our results indicate that the agent is capable of satisfying extremely complex task specifications, producing near optimal performance with no further learning. Finally, we demonstrate that the performance of skill machines can be improved with regular offline reinforcement learning algorithms when optimal behaviours are desired.