 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubhadeep Koley
You'll Never Walk Alone: A Sketch and Text Duet for Fine-Grained Image Retrieval
Mar 20, 2024
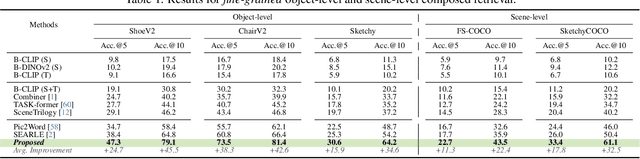
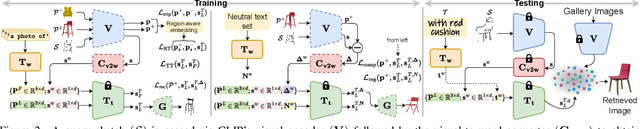

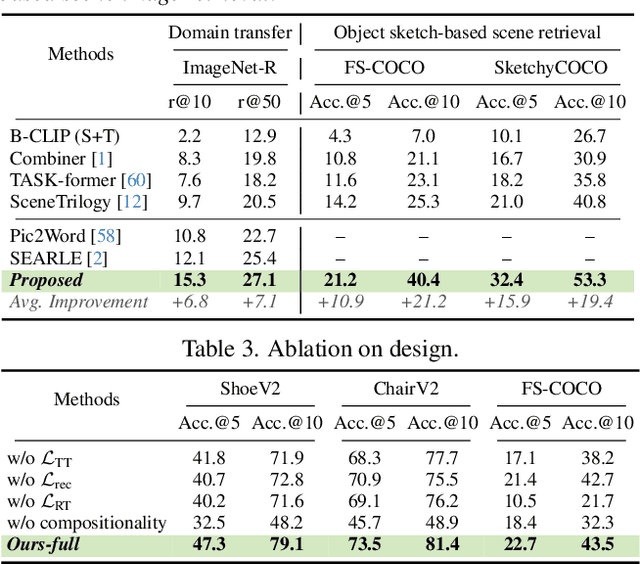
Two primary input modalities prevail in image retrieval: sketch and text. While text is widely used for inter-category retrieval tasks, sketches have been established as the sole preferred modality for fine-grained image retrieval due to their ability to capture intricate visual details. In this paper, we question the reliance on sketches alone for fine-grained image retrieval by simultaneously exploring the fine-grained representation capabilities of both sketch and text, orchestrating a duet between the two. The end result enables precise retrievals previously unattainable, allowing users to pose ever-finer queries and incorporate attributes like colour and contextual cues from text. For this purpose, we introduce a novel compositionality framework, effectively combining sketches and text using pre-trained CLIP models, while eliminating the need for extensive fine-grained textual descriptions. Last but not least, our system extends to novel applications in composed image retrieval, domain attribute transfer, and fine-grained generation, providing solutions for various real-world scenarios.
How to Handle Sketch-Abstraction in Sketch-Based Image Retrieval?
Mar 20, 2024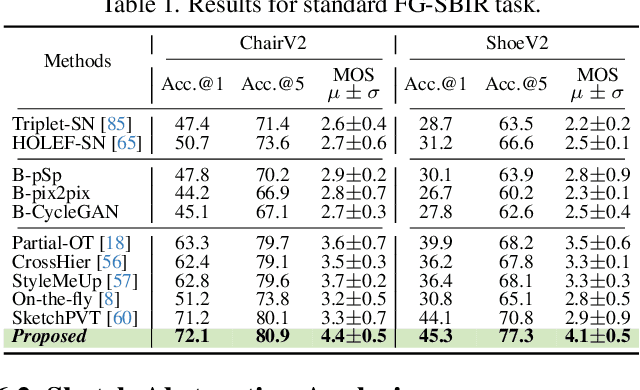
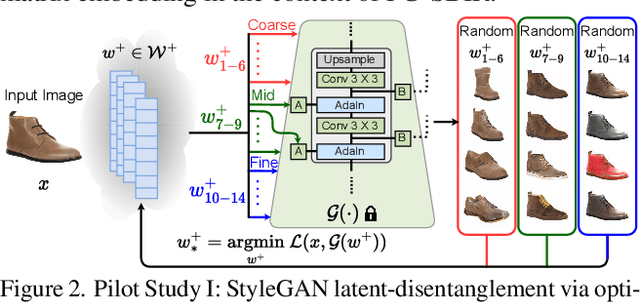
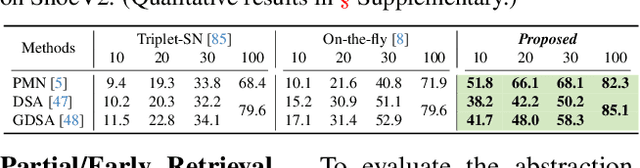
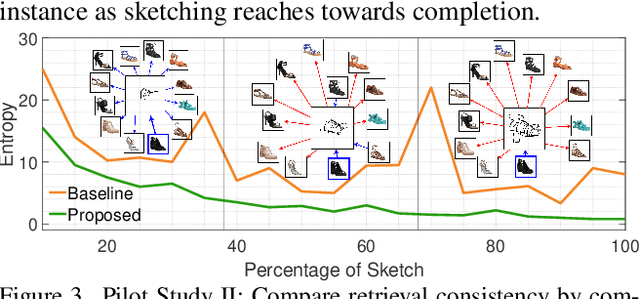
In this paper, we propose a novel abstraction-aware sketch-based image retrieval framework capable of handling sketch abstraction at varied levels. Prior works had mainly focused on tackling sub-factors such as drawing style and order, we instead attempt to model abstraction as a whole, and propose feature-level and retrieval granularity-level designs so that the system builds into its DNA the necessary means to interpret abstraction. On learning abstraction-aware features, we for the first-time harness the rich semantic embedding of pre-trained StyleGAN model, together with a novel abstraction-level mapper that deciphers the level of abstraction and dynamically selects appropriate dimensions in the feature matrix correspondingly, to construct a feature matrix embedding that can be freely traversed to accommodate different levels of abstraction. For granularity-level abstraction understanding, we dictate that the retrieval model should not treat all abstraction-levels equally and introduce a differentiable surrogate Acc.@q loss to inject that understanding into the system. Different to the gold-standard triplet loss, our Acc.@q loss uniquely allows a sketch to narrow/broaden its focus in terms of how stringent the evaluation should be - the more abstract a sketch, the less stringent (higher q). Extensive experiments depict our method to outperform existing state-of-the-arts in standard SBIR tasks along with challenging scenarios like early retrieval, forensic sketch-photo matching, and style-invariant retrieval.
Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
Mar 20, 2024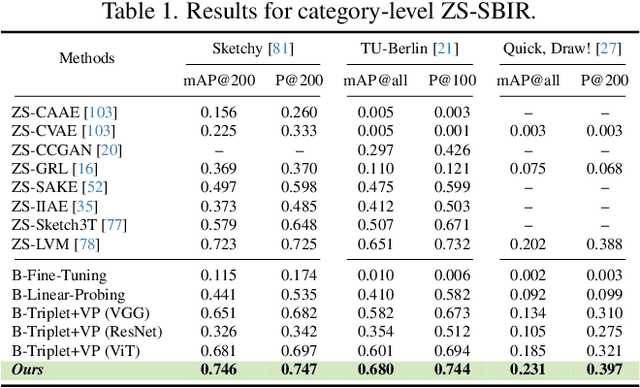
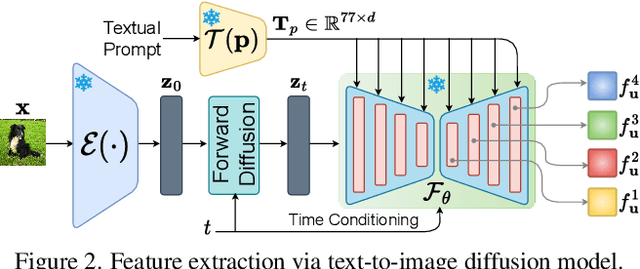


This paper, for the first time, explores text-to-image diffusion models for Zero-Shot Sketch-based Image Retrieval (ZS-SBIR). We highlight a pivotal discovery: the capacity of text-to-image diffusion models to seamlessly bridge the gap between sketches and photos. This proficiency is underpinned by their robust cross-modal capabilities and shape bias, findings that are substantiated through our pilot studies. In order to harness pre-trained diffusion models effectively, we introduce a straightforward yet powerful strategy focused on two key aspects: selecting optimal feature layers and utilising visual and textual prompts. For the former, we identify which layers are most enriched with information and are best suited for the specific retrieval requirements (category-level or fine-grained). Then we employ visual and textual prompts to guide the model's feature extraction process, enabling it to generate more discriminative and contextually relevant cross-modal representations. Extensive experiments on several benchmark datasets validate significant performance improvements.
It's All About Your Sketch: Democratising Sketch Control in Diffusion Models
Mar 20, 2024

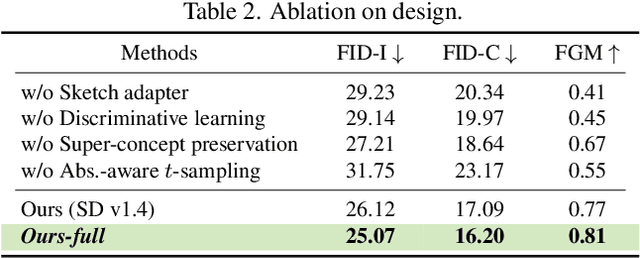

This paper unravels the potential of sketches for diffusion models, addressing the deceptive promise of direct sketch control in generative AI. We importantly democratise the process, enabling amateur sketches to generate precise images, living up to the commitment of "what you sketch is what you get". A pilot study underscores the necessity, revealing that deformities in existing models stem from spatial-conditioning. To rectify this, we propose an abstraction-aware framework, utilising a sketch adapter, adaptive time-step sampling, and discriminative guidance from a pre-trained fine-grained sketch-based image retrieval model, working synergistically to reinforce fine-grained sketch-photo association. Our approach operates seamlessly during inference without the need for textual prompts; a simple, rough sketch akin to what you and I can create suffices! We welcome everyone to examine results presented in the paper and its supplementary. Contributions include democratising sketch control, introducing an abstraction-aware framework, and leveraging discriminative guidance, validated through extensive experiments.
DemoCaricature: Democratising Caricature Generation with a Rough Sketch
Dec 07, 2023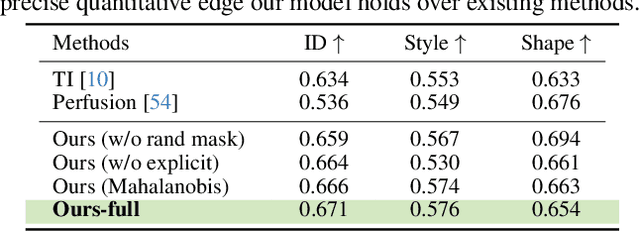

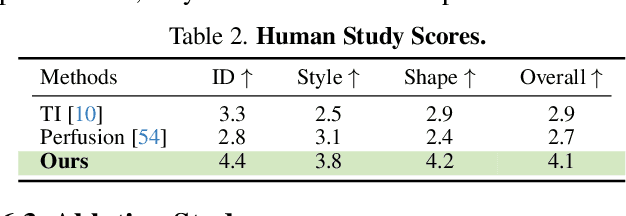

In this paper, we democratise caricature generation, empowering individuals to effortlessly craft personalised caricatures with just a photo and a conceptual sketch. Our objective is to strike a delicate balance between abstraction and identity, while preserving the creativity and subjectivity inherent in a sketch. To achieve this, we present Explicit Rank-1 Model Editing alongside single-image personalisation, selectively applying nuanced edits to cross-attention layers for a seamless merge of identity and style. Additionally, we propose Random Mask Reconstruction to enhance robustness, directing the model to focus on distinctive identity and style features. Crucially, our aim is not to replace artists but to eliminate accessibility barriers, allowing enthusiasts to engage in the artistry.
Doodle Your 3D: From Abstract Freehand Sketches to Precise 3D Shapes
Dec 07, 2023In this paper, we democratise 3D content creation, enabling precise generation of 3D shapes from abstract sketches while overcoming limitations tied to drawing skills. We introduce a novel part-level modelling and alignment framework that facilitates abstraction modelling and cross-modal correspondence. Leveraging the same part-level decoder, our approach seamlessly extends to sketch modelling by establishing correspondence between CLIPasso edgemaps and projected 3D part regions, eliminating the need for a dataset pairing human sketches and 3D shapes. Additionally, our method introduces a seamless in-position editing process as a byproduct of cross-modal part-aligned modelling. Operating in a low-dimensional implicit space, our approach significantly reduces computational demands and processing time.
Picture that Sketch: Photorealistic Image Generation from Abstract Sketches
Mar 30, 2023

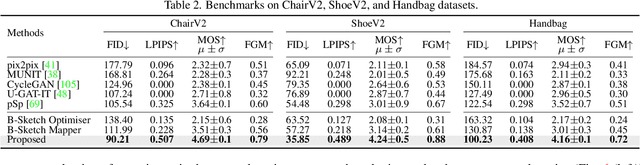

Given an abstract, deformed, ordinary sketch from untrained amateurs like you and me, this paper turns it into a photorealistic image - just like those shown in Fig. 1(a), all non-cherry-picked. We differ significantly from prior art in that we do not dictate an edgemap-like sketch to start with, but aim to work with abstract free-hand human sketches. In doing so, we essentially democratise the sketch-to-photo pipeline, "picturing" a sketch regardless of how good you sketch. Our contribution at the outset is a decoupled encoder-decoder training paradigm, where the decoder is a StyleGAN trained on photos only. This importantly ensures that generated results are always photorealistic. The rest is then all centred around how best to deal with the abstraction gap between sketch and photo. For that, we propose an autoregressive sketch mapper trained on sketch-photo pairs that maps a sketch to the StyleGAN latent space. We further introduce specific designs to tackle the abstract nature of human sketches, including a fine-grained discriminative loss on the back of a trained sketch-photo retrieval model, and a partial-aware sketch augmentation strategy. Finally, we showcase a few downstream tasks our generation model enables, amongst them is showing how fine-grained sketch-based image retrieval, a well-studied problem in the sketch community, can be reduced to an image (generated) to image retrieval task, surpassing state-of-the-arts. We put forward generated results in the supplementary for everyone to scrutinise.
Sketch2Saliency: Learning to Detect Salient Objects from Human Drawings
Mar 30, 2023
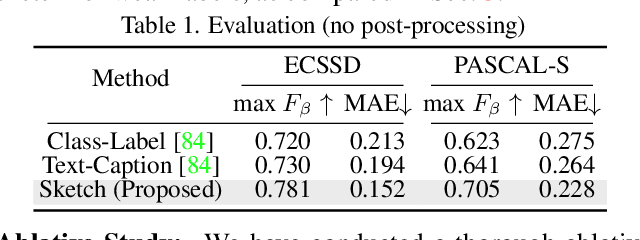


Human sketch has already proved its worth in various visual understanding tasks (e.g., retrieval, segmentation, image-captioning, etc). In this paper, we reveal a new trait of sketches - that they are also salient. This is intuitive as sketching is a natural attentive process at its core. More specifically, we aim to study how sketches can be used as a weak label to detect salient objects present in an image. To this end, we propose a novel method that emphasises on how "salient object" could be explained by hand-drawn sketches. To accomplish this, we introduce a photo-to-sketch generation model that aims to generate sequential sketch coordinates corresponding to a given visual photo through a 2D attention mechanism. Attention maps accumulated across the time steps give rise to salient regions in the process. Extensive quantitative and qualitative experiments prove our hypothesis and delineate how our sketch-based saliency detection model gives a competitive performance compared to the state-of-the-art.
CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not
Mar 28, 2023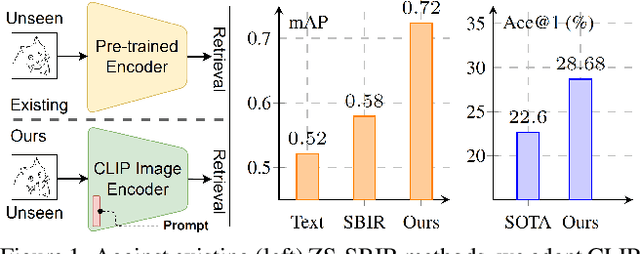
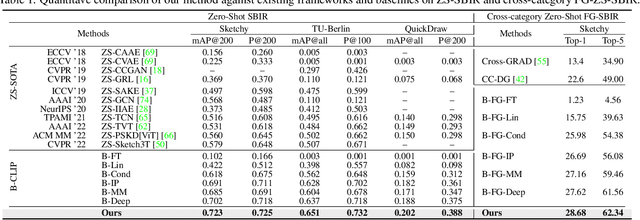
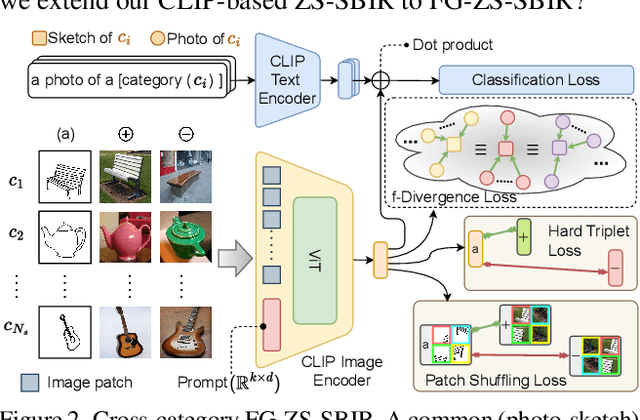
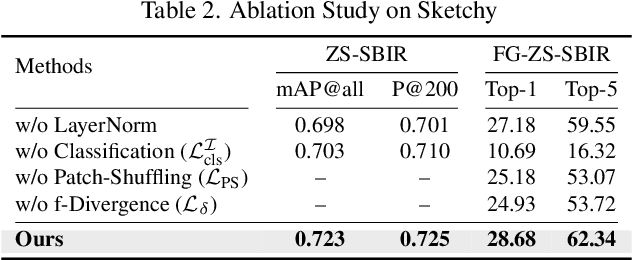
In this paper, we leverage CLIP for zero-shot sketch based image retrieval (ZS-SBIR). We are largely inspired by recent advances on foundation models and the unparalleled generalisation ability they seem to offer, but for the first time tailor it to benefit the sketch community. We put forward novel designs on how best to achieve this synergy, for both the category setting and the fine-grained setting ("all"). At the very core of our solution is a prompt learning setup. First we show just via factoring in sketch-specific prompts, we already have a category-level ZS-SBIR system that overshoots all prior arts, by a large margin (24.8%) - a great testimony on studying the CLIP and ZS-SBIR synergy. Moving onto the fine-grained setup is however trickier, and requires a deeper dive into this synergy. For that, we come up with two specific designs to tackle the fine-grained matching nature of the problem: (i) an additional regularisation loss to ensure the relative separation between sketches and photos is uniform across categories, which is not the case for the gold standard standalone triplet loss, and (ii) a clever patch shuffling technique to help establishing instance-level structural correspondences between sketch-photo pairs. With these designs, we again observe significant performance gains in the region of 26.9% over previous state-of-the-art. The take-home message, if any, is the proposed CLIP and prompt learning paradigm carries great promise in tackling other sketch-related tasks (not limited to ZS-SBIR) where data scarcity remains a great challenge. Project page: https://aneeshan95.github.io/Sketch_LVM/
What Can Human Sketches Do for Object Detection?
Mar 27, 2023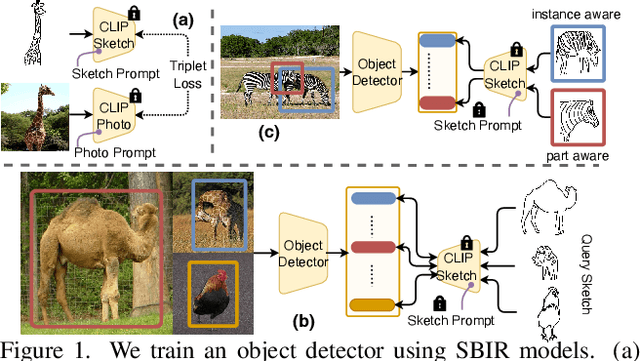
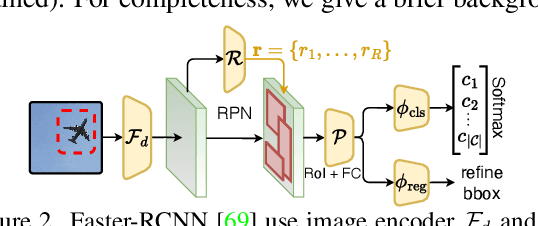
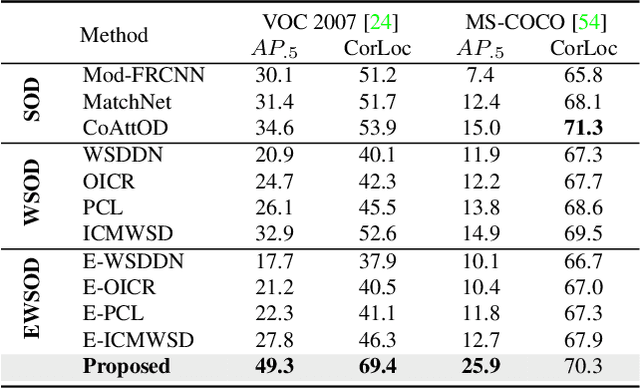
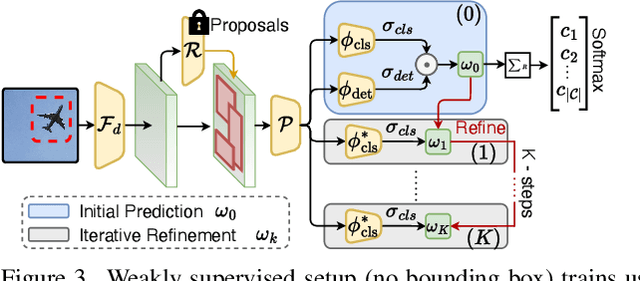
Sketches are highly expressive, inherently capturing subjective and fine-grained visual cues. The exploration of such innate properties of human sketches has, however, been limited to that of image retrieval. In this paper, for the first time, we cultivate the expressiveness of sketches but for the fundamental vision task of object detection. The end result is a sketch-enabled object detection framework that detects based on what \textit{you} sketch -- \textit{that} ``zebra'' (e.g., one that is eating the grass) in a herd of zebras (instance-aware detection), and only the \textit{part} (e.g., ``head" of a ``zebra") that you desire (part-aware detection). We further dictate that our model works without (i) knowing which category to expect at testing (zero-shot) and (ii) not requiring additional bounding boxes (as per fully supervised) and class labels (as per weakly supervised). Instead of devising a model from the ground up, we show an intuitive synergy between foundation models (e.g., CLIP) and existing sketch models build for sketch-based image retrieval (SBIR), which can already elegantly solve the task -- CLIP to provide model generalisation, and SBIR to bridge the (sketch$\rightarrow$photo) gap. In particular, we first perform independent prompting on both sketch and photo branches of an SBIR model to build highly generalisable sketch and photo encoders on the back of the generalisation ability of CLIP. We then devise a training paradigm to adapt the learned encoders for object detection, such that the region embeddings of detected boxes are aligned with the sketch and photo embeddings from SBIR. Evaluating our framework on standard object detection datasets like PASCAL-VOC and MS-COCO outperforms both supervised (SOD) and weakly-supervised object detectors (WSOD) on zero-shot setups. Project Page: \url{https://pinakinathc.github.io/sketch-detect}