 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSumit Kumar Jha
Towards a Game-theoretic Understanding of Explanation-based Membership Inference Attacks
Apr 10, 2024
Model explanations improve the transparency of black-box machine learning (ML) models and their decisions; however, they can also be exploited to carry out privacy threats such as membership inference attacks (MIA). Existing works have only analyzed MIA in a single "what if" interaction scenario between an adversary and the target ML model; thus, it does not discern the factors impacting the capabilities of an adversary in launching MIA in repeated interaction settings. Additionally, these works rely on assumptions about the adversary's knowledge of the target model's structure and, thus, do not guarantee the optimality of the predefined threshold required to distinguish the members from non-members. In this paper, we delve into the domain of explanation-based threshold attacks, where the adversary endeavors to carry out MIA attacks by leveraging the variance of explanations through iterative interactions with the system comprising of the target ML model and its corresponding explanation method. We model such interactions by employing a continuous-time stochastic signaling game framework. In our framework, an adversary plays a stopping game, interacting with the system (having imperfect information about the type of an adversary, i.e., honest or malicious) to obtain explanation variance information and computing an optimal threshold to determine the membership of a datapoint accurately. First, we propose a sound mathematical formulation to prove that such an optimal threshold exists, which can be used to launch MIA. Then, we characterize the conditions under which a unique Markov perfect equilibrium (or steady state) exists in this dynamic system. By means of a comprehensive set of simulations of the proposed game model, we assess different factors that can impact the capability of an adversary to launch MIA in such repeated interaction settings.
Neuro Symbolic Reasoning for Planning: Counterexample Guided Inductive Synthesis using Large Language Models and Satisfiability Solving
Sep 28, 2023
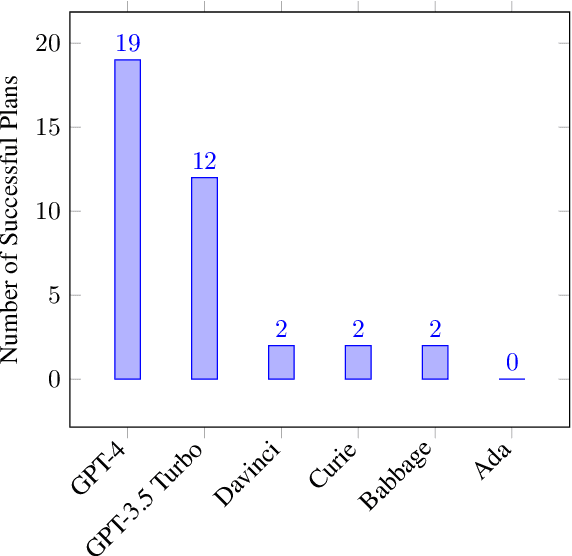

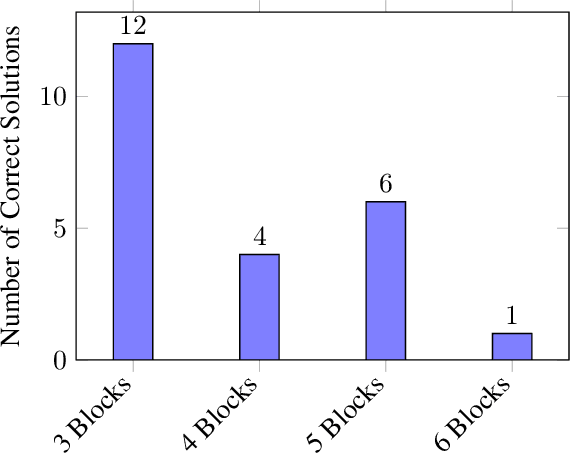
Generative large language models (LLMs) with instruct training such as GPT-4 can follow human-provided instruction prompts and generate human-like responses to these prompts. Apart from natural language responses, they have also been found to be effective at generating formal artifacts such as code, plans, and logical specifications from natural language prompts. Despite their remarkably improved accuracy, these models are still known to produce factually incorrect or contextually inappropriate results despite their syntactic coherence - a phenomenon often referred to as hallucination. This limitation makes it difficult to use these models to synthesize formal artifacts that are used in safety-critical applications. Unlike tasks such as text summarization and question-answering, bugs in code, plan, and other formal artifacts produced by LLMs can be catastrophic. We posit that we can use the satisfiability modulo theory (SMT) solvers as deductive reasoning engines to analyze the generated solutions from the LLMs, produce counterexamples when the solutions are incorrect, and provide that feedback to the LLMs exploiting the dialog capability of instruct-trained LLMs. This interaction between inductive LLMs and deductive SMT solvers can iteratively steer the LLM to generate the correct response. In our experiments, we use planning over the domain of blocks as our synthesis task for evaluating our approach. We use GPT-4, GPT3.5 Turbo, Davinci, Curie, Babbage, and Ada as the LLMs and Z3 as the SMT solver. Our method allows the user to communicate the planning problem in natural language; even the formulation of queries to SMT solvers is automatically generated from natural language. Thus, the proposed technique can enable non-expert users to describe their problems in natural language, and the combination of LLMs and SMT solvers can produce provably correct solutions.
Neural Stochastic Differential Equations for Robust and Explainable Analysis of Electromagnetic Unintended Radiated Emissions
Sep 27, 2023
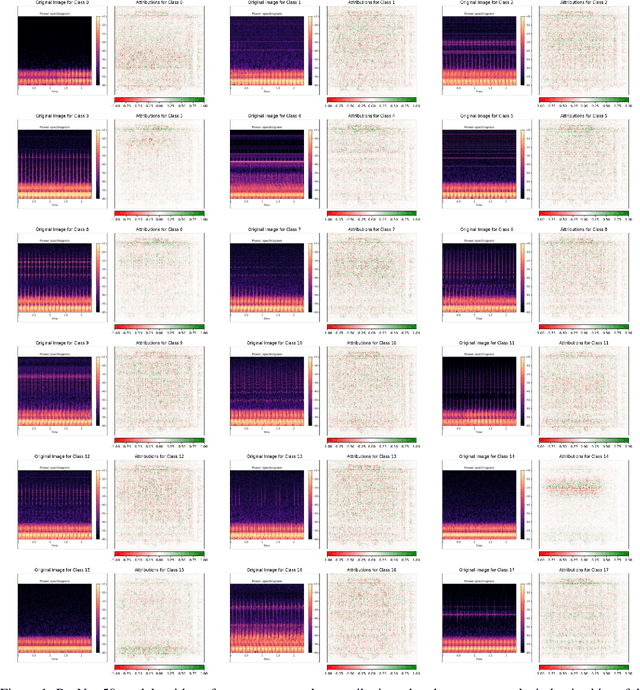

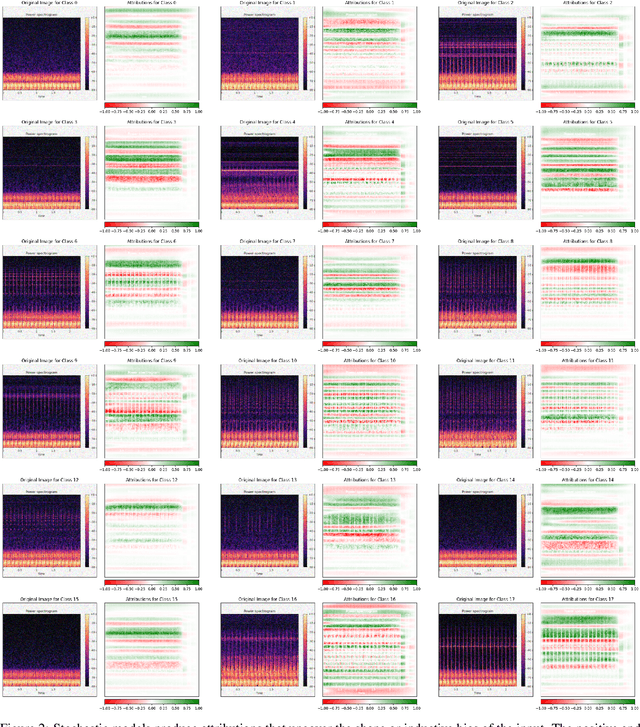
We present a comprehensive evaluation of the robustness and explainability of ResNet-like models in the context of Unintended Radiated Emission (URE) classification and suggest a new approach leveraging Neural Stochastic Differential Equations (SDEs) to address identified limitations. We provide an empirical demonstration of the fragility of ResNet-like models to Gaussian noise perturbations, where the model performance deteriorates sharply and its F1-score drops to near insignificance at 0.008 with a Gaussian noise of only 0.5 standard deviation. We also highlight a concerning discrepancy where the explanations provided by ResNet-like models do not reflect the inherent periodicity in the input data, a crucial attribute in URE detection from stable devices. In response to these findings, we propose a novel application of Neural SDEs to build models for URE classification that are not only robust to noise but also provide more meaningful and intuitive explanations. Neural SDE models maintain a high F1-score of 0.93 even when exposed to Gaussian noise with a standard deviation of 0.5, demonstrating superior resilience to ResNet models. Neural SDE models successfully recover the time-invariant or periodic horizontal bands from the input data, a feature that was conspicuously missing in the explanations generated by ResNet-like models. This advancement presents a small but significant step in the development of robust and interpretable models for real-world URE applications where data is inherently noisy and assurance arguments demand interpretable machine learning predictions.
A Game-theoretic Understanding of Repeated Explanations in ML Models
Feb 05, 2022
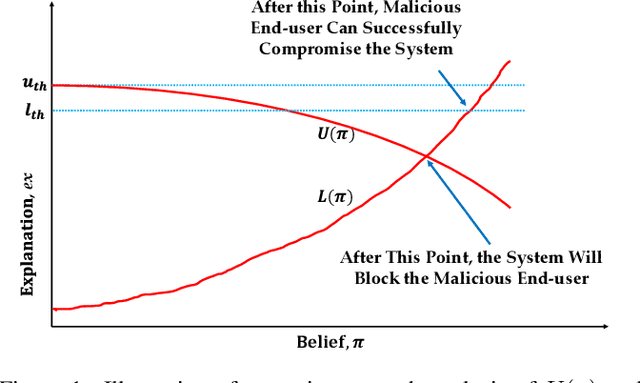
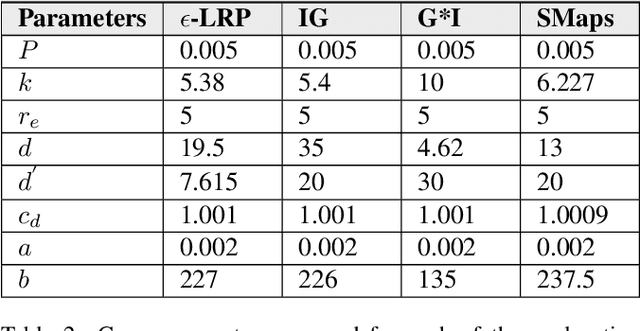
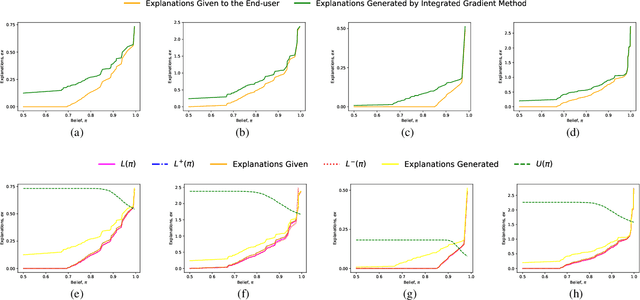
This paper formally models the strategic repeated interactions between a system, comprising of a machine learning (ML) model and associated explanation method, and an end-user who is seeking a prediction/label and its explanation for a query/input, by means of game theory. In this game, a malicious end-user must strategically decide when to stop querying and attempt to compromise the system, while the system must strategically decide how much information (in the form of noisy explanations) it should share with the end-user and when to stop sharing, all without knowing the type (honest/malicious) of the end-user. This paper formally models this trade-off using a continuous-time stochastic Signaling game framework and characterizes the Markov perfect equilibrium state within such a framework.
Protein Folding Neural Networks Are Not Robust
Sep 19, 2021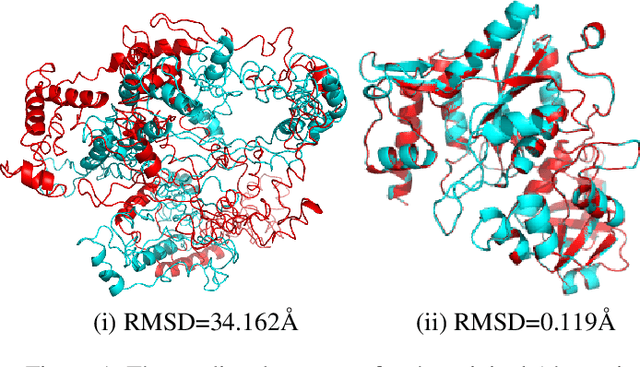
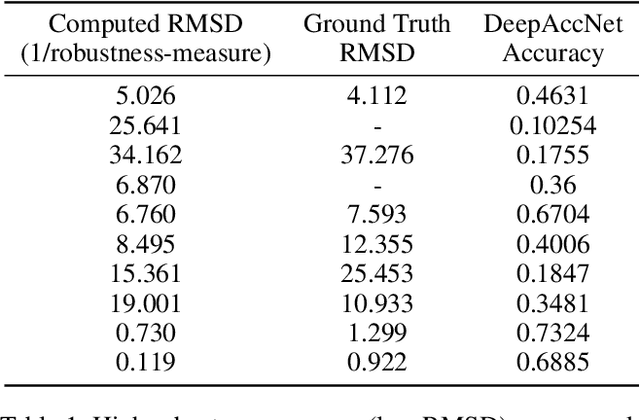
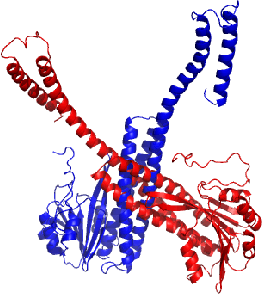
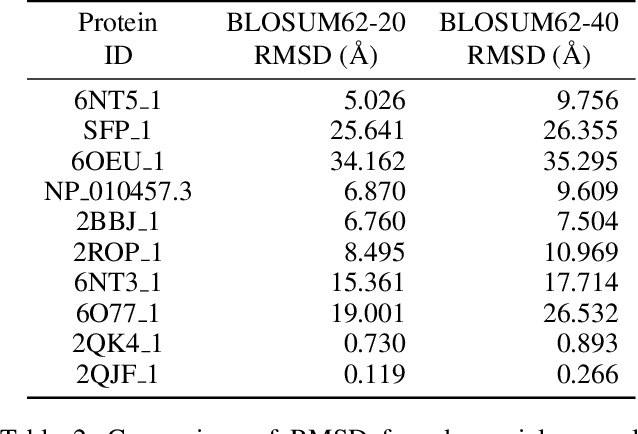
Deep neural networks such as AlphaFold and RoseTTAFold predict remarkably accurate structures of proteins compared to other algorithmic approaches. It is known that biologically small perturbations in the protein sequence do not lead to drastic changes in the protein structure. In this paper, we demonstrate that RoseTTAFold does not exhibit such a robustness despite its high accuracy, and biologically small perturbations for some input sequences result in radically different predicted protein structures. This raises the challenge of detecting when these predicted protein structures cannot be trusted. We define the robustness measure for the predicted structure of a protein sequence to be the inverse of the root-mean-square distance (RMSD) in the predicted structure and the structure of its adversarially perturbed sequence. We use adversarial attack methods to create adversarial protein sequences, and show that the RMSD in the predicted protein structure ranges from 0.119\r{A} to 34.162\r{A} when the adversarial perturbations are bounded by 20 units in the BLOSUM62 distance. This demonstrates very high variance in the robustness measure of the predicted structures. We show that the magnitude of the correlation (0.917) between our robustness measure and the RMSD between the predicted structure and the ground truth is high, that is, the predictions with low robustness measure cannot be trusted. This is the first paper demonstrating the susceptibility of RoseTTAFold to adversarial attacks.
CrossedWires: A Dataset of Syntactically Equivalent but Semantically Disparate Deep Learning Models
Aug 29, 2021

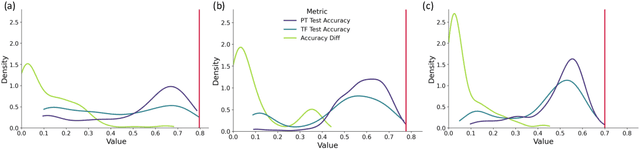

The training of neural networks using different deep learning frameworks may lead to drastically differing accuracy levels despite the use of the same neural network architecture and identical training hyperparameters such as learning rate and choice of optimization algorithms. Currently, our ability to build standardized deep learning models is limited by the availability of a suite of neural network and corresponding training hyperparameter benchmarks that expose differences between existing deep learning frameworks. In this paper, we present a living dataset of models and hyperparameters, called CrossedWires, that exposes semantic differences between two popular deep learning frameworks: PyTorch and Tensorflow. The CrossedWires dataset currently consists of models trained on CIFAR10 images using three different computer vision architectures: VGG16, ResNet50 and DenseNet121 across a large hyperparameter space. Using hyperparameter optimization, each of the three models was trained on 400 sets of hyperparameters suggested by the HyperSpace search algorithm. The CrossedWires dataset includes PyTorch and Tensforflow models with test accuracies as different as 0.681 on syntactically equivalent models and identical hyperparameter choices. The 340 GB dataset and benchmarks presented here include the performance statistics, training curves, and model weights for all 1200 hyperparameter choices, resulting in 2400 total models. The CrossedWires dataset provides an opportunity to study semantic differences between syntactically equivalent models across popular deep learning frameworks. Further, the insights obtained from this study can enable the development of algorithms and tools that improve reliability and reproducibility of deep learning frameworks. The dataset is freely available at https://github.com/maxzvyagin/crossedwires through a Python API and direct download link.
An Extension of Fano's Inequality for Characterizing Model Susceptibility to Membership Inference Attacks
Sep 17, 2020
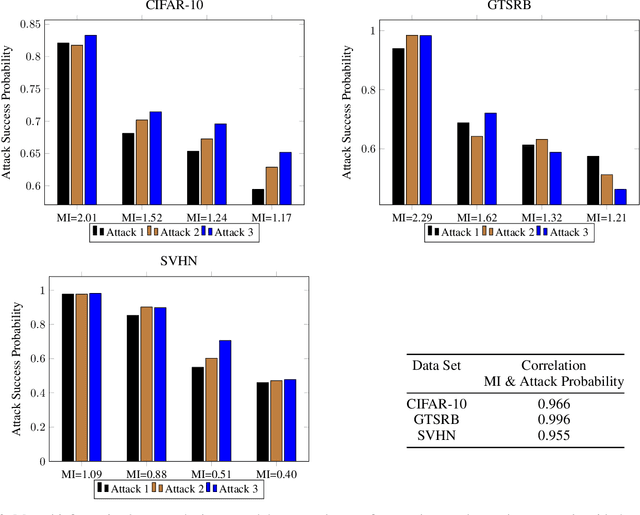
Deep neural networks have been shown to be vulnerable to membership inference attacks wherein the attacker aims to detect whether specific input data were used to train the model. These attacks can potentially leak private or proprietary data. We present a new extension of Fano's inequality and employ it to theoretically establish that the probability of success for a membership inference attack on a deep neural network can be bounded using the mutual information between its inputs and its activations. This enables the use of mutual information to measure the susceptibility of a DNN model to membership inference attacks. In our empirical evaluation, we show that the correlation between the mutual information and the susceptibility of the DNN model to membership inference attacks is 0.966, 0.996, and 0.955 for CIFAR-10, SVHN and GTSRB models, respectively.
Quantifying Membership Inference Vulnerability via Generalization Gap and Other Model Metrics
Sep 11, 2020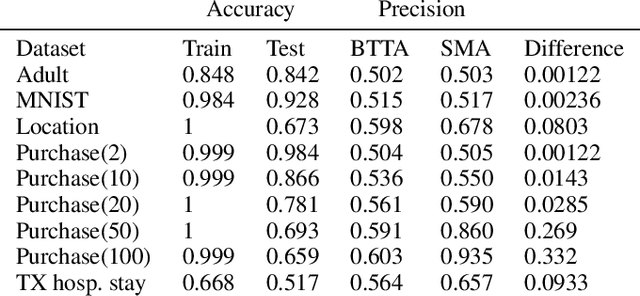
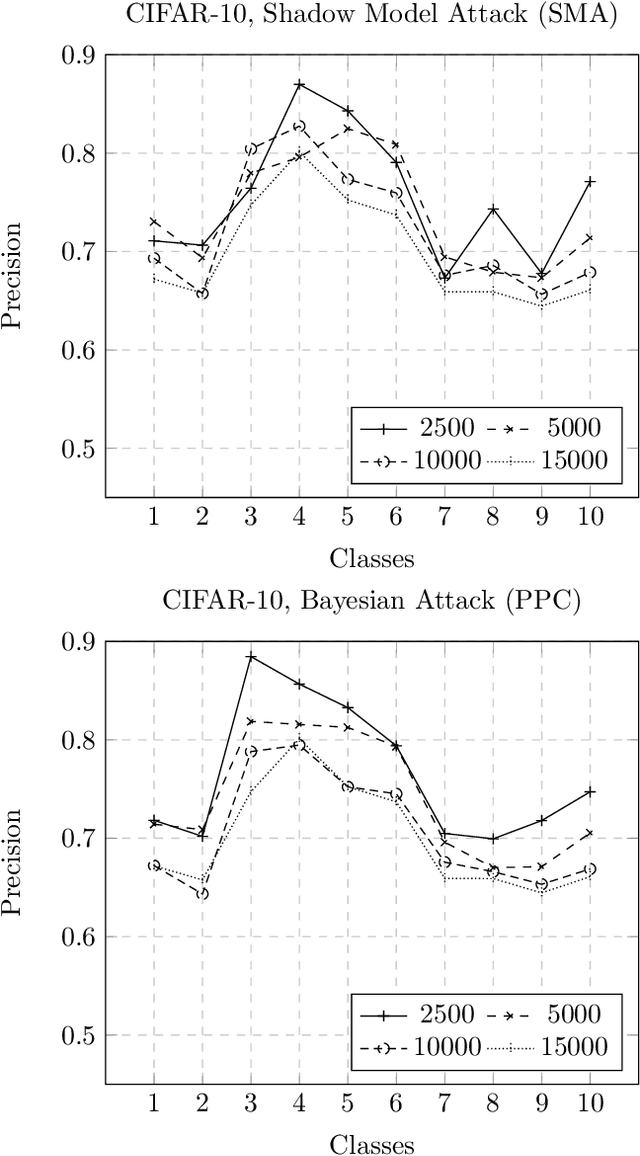
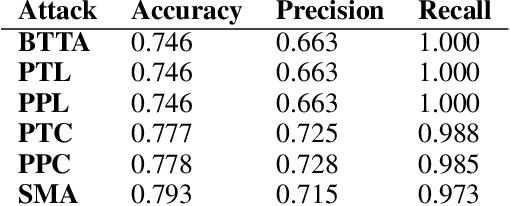
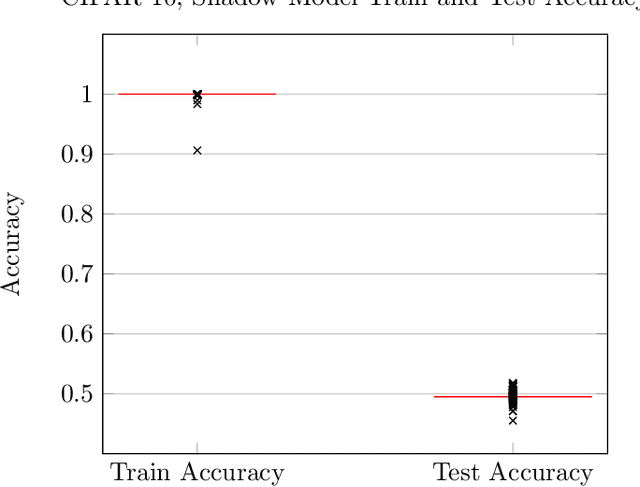
We demonstrate how a target model's generalization gap leads directly to an effective deterministic black box membership inference attack (MIA). This provides an upper bound on how secure a model can be to MIA based on a simple metric. Moreover, this attack is shown to be optimal in the expected sense given access to only certain likely obtainable metrics regarding the network's training and performance. Experimentally, this attack is shown to be comparable in accuracy to state-of-art MIAs in many cases.
Attribution-driven Causal Analysis for Detection of Adversarial Examples
Mar 14, 2019
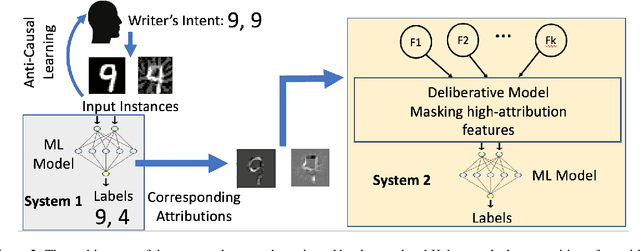
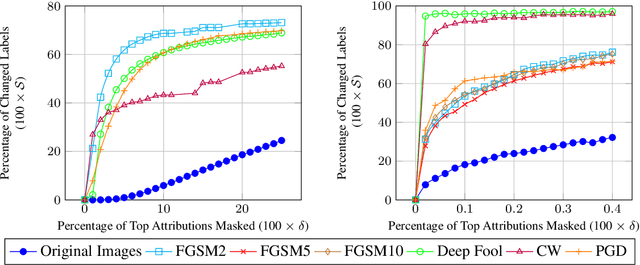
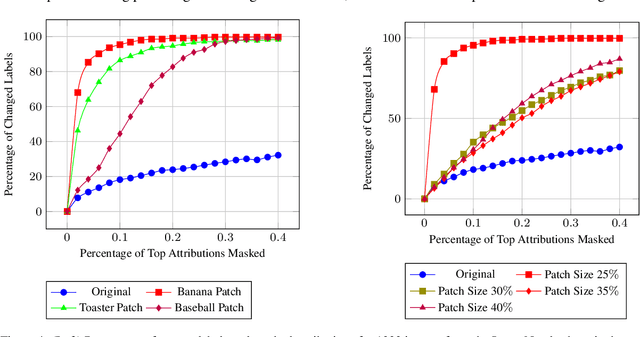
Attribution methods have been developed to explain the decision of a machine learning model on a given input. We use the Integrated Gradient method for finding attributions to define the causal neighborhood of an input by incrementally masking high attribution features. We study the robustness of machine learning models on benign and adversarial inputs in this neighborhood. Our study indicates that benign inputs are robust to the masking of high attribution features but adversarial inputs generated by the state-of-the-art adversarial attack methods such as DeepFool, FGSM, CW and PGD, are not robust to such masking. Further, our study demonstrates that this concentration of high-attribution features responsible for the incorrect decision is more pronounced in physically realizable adversarial examples. This difference in attribution of benign and adversarial inputs can be used to detect adversarial examples. Such a defense approach is independent of training data and attack method, and we demonstrate its effectiveness on digital and physically realizable perturbations.