 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuraj Srinivas
Interpreting CLIP with Sparse Linear Concept Embeddings (SpLiCE)
Feb 16, 2024
CLIP embeddings have demonstrated remarkable performance across a wide range of computer vision tasks. However, these high-dimensional, dense vector representations are not easily interpretable, restricting their usefulness in downstream applications that require transparency. In this work, we empirically show that CLIP's latent space is highly structured, and consequently that CLIP representations can be decomposed into their underlying semantic components. We leverage this understanding to propose a novel method, Sparse Linear Concept Embeddings (SpLiCE), for transforming CLIP representations into sparse linear combinations of human-interpretable concepts. Distinct from previous work, SpLiCE does not require concept labels and can be applied post hoc. Through extensive experimentation with multiple real-world datasets, we validate that the representations output by SpLiCE can explain and even replace traditional dense CLIP representations, maintaining equivalent downstream performance while significantly improving their interpretability. We also demonstrate several use cases of SpLiCE representations including detecting spurious correlations, model editing, and quantifying semantic shifts in datasets.
Certifying LLM Safety against Adversarial Prompting
Sep 06, 2023Large language models (LLMs) released for public use incorporate guardrails to ensure their output is safe, often referred to as "model alignment." An aligned language model should decline a user's request to produce harmful content. However, such safety measures are vulnerable to adversarial prompts, which contain maliciously designed token sequences to circumvent the model's safety guards and cause it to produce harmful content. In this work, we introduce erase-and-check, the first framework to defend against adversarial prompts with verifiable safety guarantees. We erase tokens individually and inspect the resulting subsequences using a safety filter. Our procedure labels the input prompt as harmful if any subsequences or the input prompt are detected as harmful by the filter. This guarantees that any adversarial modification of a harmful prompt up to a certain size is also labeled harmful. We defend against three attack modes: i) adversarial suffix, which appends an adversarial sequence at the end of the prompt; ii) adversarial insertion, where the adversarial sequence is inserted anywhere in the middle of the prompt; and iii) adversarial infusion, where adversarial tokens are inserted at arbitrary positions in the prompt, not necessarily as a contiguous block. Empirical results demonstrate that our technique obtains strong certified safety guarantees on harmful prompts while maintaining good performance on safe prompts. For example, against adversarial suffixes of length 20, it certifiably detects 93% of the harmful prompts and labels 94% of the safe prompts as safe using the open source language model Llama 2 as the safety filter.
Verifiable Feature Attributions: A Bridge between Post Hoc Explainability and Inherent Interpretability
Jul 27, 2023



With the increased deployment of machine learning models in various real-world applications, researchers and practitioners alike have emphasized the need for explanations of model behaviour. To this end, two broad strategies have been outlined in prior literature to explain models. Post hoc explanation methods explain the behaviour of complex black-box models by highlighting features that are critical to model predictions; however, prior work has shown that these explanations may not be faithful, and even more concerning is our inability to verify them. Specifically, it is nontrivial to evaluate if a given attribution is correct with respect to the underlying model. Inherently interpretable models, on the other hand, circumvent these issues by explicitly encoding explanations into model architecture, meaning their explanations are naturally faithful and verifiable, but they often exhibit poor predictive performance due to their limited expressive power. In this work, we aim to bridge the gap between the aforementioned strategies by proposing Verifiability Tuning (VerT), a method that transforms black-box models into models that naturally yield faithful and verifiable feature attributions. We begin by introducing a formal theoretical framework to understand verifiability and show that attributions produced by standard models cannot be verified. We then leverage this framework to propose a method to build verifiable models and feature attributions out of fully trained black-box models. Finally, we perform extensive experiments on semi-synthetic and real-world datasets, and show that VerT produces models that (1) yield explanations that are correct and verifiable and (2) are faithful to the original black-box models they are meant to explain.
Efficient Estimation of the Local Robustness of Machine Learning Models
Jul 26, 2023



Machine learning models often need to be robust to noisy input data. The effect of real-world noise (which is often random) on model predictions is captured by a model's local robustness, i.e., the consistency of model predictions in a local region around an input. However, the na\"ive approach to computing local robustness based on Monte-Carlo sampling is statistically inefficient, leading to prohibitive computational costs for large-scale applications. In this work, we develop the first analytical estimators to efficiently compute local robustness of multi-class discriminative models using local linear function approximation and the multivariate Normal CDF. Through the derivation of these estimators, we show how local robustness is connected to concepts such as randomized smoothing and softmax probability. We also confirm empirically that these estimators accurately and efficiently compute the local robustness of standard deep learning models. In addition, we demonstrate these estimators' usefulness for various tasks involving local robustness, such as measuring robustness bias and identifying examples that are vulnerable to noise perturbation in a dataset. By developing these analytical estimators, this work not only advances conceptual understanding of local robustness, but also makes its computation practical, enabling the use of local robustness in critical downstream applications.
Consistent Explanations in the Face of Model Indeterminacy via Ensembling
Jun 13, 2023
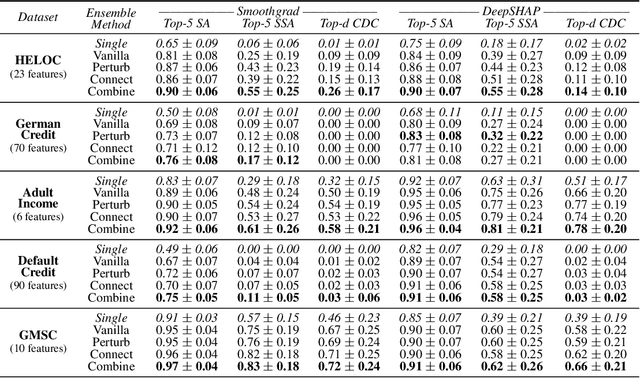
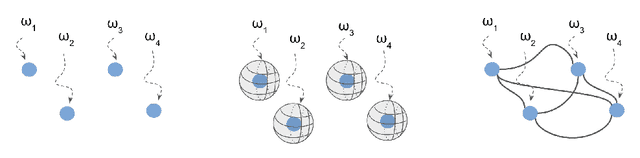

This work addresses the challenge of providing consistent explanations for predictive models in the presence of model indeterminacy, which arises due to the existence of multiple (nearly) equally well-performing models for a given dataset and task. Despite their similar performance, such models often exhibit inconsistent or even contradictory explanations for their predictions, posing challenges to end users who rely on these models to make critical decisions. Recognizing this issue, we introduce ensemble methods as an approach to enhance the consistency of the explanations provided in these scenarios. Leveraging insights from recent work on neural network loss landscapes and mode connectivity, we devise ensemble strategies to efficiently explore the underspecification set -- the set of models with performance variations resulting solely from changes in the random seed during training. Experiments on five benchmark financial datasets reveal that ensembling can yield significant improvements when it comes to explanation similarity, and demonstrate the potential of existing ensemble methods to explore the underspecification set efficiently. Our findings highlight the importance of considering model indeterminacy when interpreting explanations and showcase the effectiveness of ensembles in enhancing the reliability of explanations in machine learning.
On Minimizing the Impact of Dataset Shifts on Actionable Explanations
Jun 11, 2023



The Right to Explanation is an important regulatory principle that allows individuals to request actionable explanations for algorithmic decisions. However, several technical challenges arise when providing such actionable explanations in practice. For instance, models are periodically retrained to handle dataset shifts. This process may invalidate some of the previously prescribed explanations, thus rendering them unactionable. But, it is unclear if and when such invalidations occur, and what factors determine explanation stability i.e., if an explanation remains unchanged amidst model retraining due to dataset shifts. In this paper, we address the aforementioned gaps and provide one of the first theoretical and empirical characterizations of the factors influencing explanation stability. To this end, we conduct rigorous theoretical analysis to demonstrate that model curvature, weight decay parameters while training, and the magnitude of the dataset shift are key factors that determine the extent of explanation (in)stability. Extensive experimentation with real-world datasets not only validates our theoretical results, but also demonstrates that the aforementioned factors dramatically impact the stability of explanations produced by various state-of-the-art methods.
Word-Level Explanations for Analyzing Bias in Text-to-Image Models
Jun 03, 2023
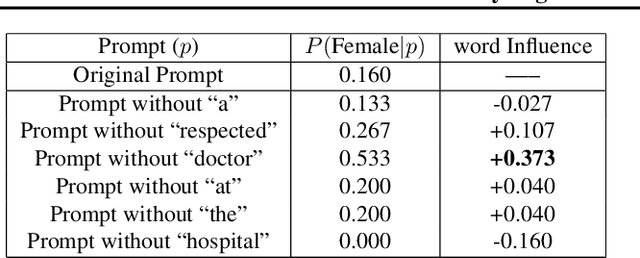
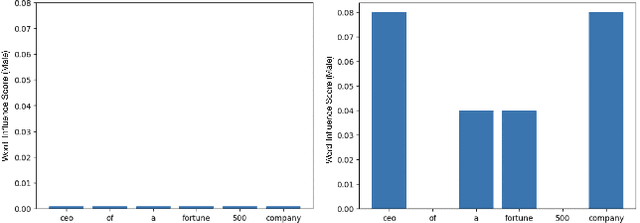

Text-to-image models take a sentence (i.e., prompt) and generate images associated with this input prompt. These models have created award wining-art, videos, and even synthetic datasets. However, text-to-image (T2I) models can generate images that underrepresent minorities based on race and sex. This paper investigates which word in the input prompt is responsible for bias in generated images. We introduce a method for computing scores for each word in the prompt; these scores represent its influence on biases in the model's output. Our method follows the principle of \emph{explaining by removing}, leveraging masked language models to calculate the influence scores. We perform experiments on Stable Diffusion to demonstrate that our method identifies the replication of societal stereotypes in generated images.
Which Models have Perceptually-Aligned Gradients? An Explanation via Off-Manifold Robustness
May 30, 2023



One of the remarkable properties of robust computer vision models is that their input-gradients are often aligned with human perception, referred to in the literature as perceptually-aligned gradients (PAGs). Despite only being trained for classification, PAGs cause robust models to have rudimentary generative capabilities, including image generation, denoising, and in-painting. However, the underlying mechanisms behind these phenomena remain unknown. In this work, we provide a first explanation of PAGs via \emph{off-manifold robustness}, which states that models must be more robust off- the data manifold than they are on-manifold. We first demonstrate theoretically that off-manifold robustness leads input gradients to lie approximately on the data manifold, explaining their perceptual alignment. We then show that Bayes optimal models satisfy off-manifold robustness, and confirm the same empirically for robust models trained via gradient norm regularization, noise augmentation, and randomized smoothing. Quantifying the perceptual alignment of model gradients via their similarity with the gradients of generative models, we show that off-manifold robustness correlates well with perceptual alignment. Finally, based on the levels of on- and off-manifold robustness, we identify three different regimes of robustness that affect both perceptual alignment and model accuracy: weak robustness, bayes-aligned robustness, and excessive robustness.
Flatten the Curve: Efficiently Training Low-Curvature Neural Networks
Jun 14, 2022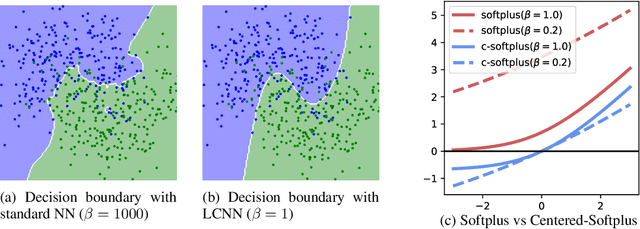

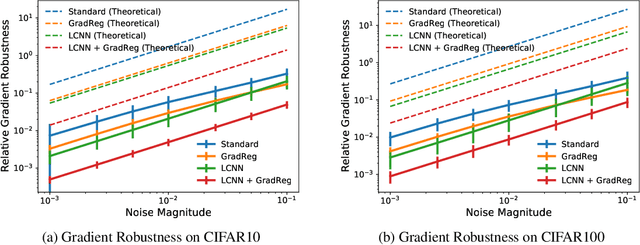

The highly non-linear nature of deep neural networks causes them to be susceptible to adversarial examples and have unstable gradients which hinders interpretability. However, existing methods to solve these issues, such as adversarial training, are expensive and often sacrifice predictive accuracy. In this work, we consider curvature, which is a mathematical quantity which encodes the degree of non-linearity. Using this, we demonstrate low-curvature neural networks (LCNNs) that obtain drastically lower curvature than standard models while exhibiting similar predictive performance, which leads to improved robustness and stable gradients, with only a marginally increased training time. To achieve this, we minimize a data-independent upper bound on the curvature of a neural network, which decomposes overall curvature in terms of curvatures and slopes of its constituent layers. To efficiently minimize this bound, we introduce two novel architectural components: first, a non-linearity called centered-softplus that is a stable variant of the softplus non-linearity, and second, a Lipschitz-constrained batch normalization layer. Our experiments show that LCNNs have lower curvature, more stable gradients and increased off-the-shelf adversarial robustness when compared to their standard high-curvature counterparts, all without affecting predictive performance. Our approach is easy to use and can be readily incorporated into existing neural network models.
Which Explanation Should I Choose? A Function Approximation Perspective to Characterizing Post hoc Explanations
Jun 02, 2022



Despite the plethora of post hoc model explanation methods, the basic properties and behavior of these methods and the conditions under which each one is effective are not well understood. In this work, we bridge these gaps and address a fundamental question: Which explanation method should one use in a given situation? To this end, we adopt a function approximation perspective and formalize the local function approximation (LFA) framework. We show that popular explanation methods are instances of this framework, performing function approximations of the underlying model in different neighborhoods using different loss functions. We introduce a no free lunch theorem for explanation methods which demonstrates that no single method can perform optimally across all neighbourhoods and calls for choosing among methods. To choose among methods, we set forth a guiding principle based on the function approximation perspective, considering a method to be effective if it recovers the underlying model when the model is a member of the explanation function class. Then, we analyze the conditions under which popular explanation methods are effective and provide recommendations for choosing among explanation methods and creating new ones. Lastly, we empirically validate our theoretical results using various real world datasets, model classes, and prediction tasks. By providing a principled mathematical framework which unifies diverse explanation methods, our work characterizes the behaviour of these methods and their relation to one another, guides the choice of explanation methods, and paves the way for the creation of new ones.