 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwayambhoo Jain
Data-Driven Low-Rank Neural Network Compression
Jul 13, 2021
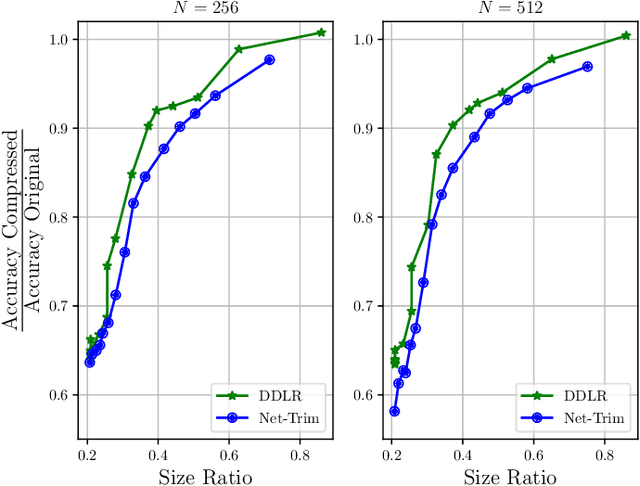
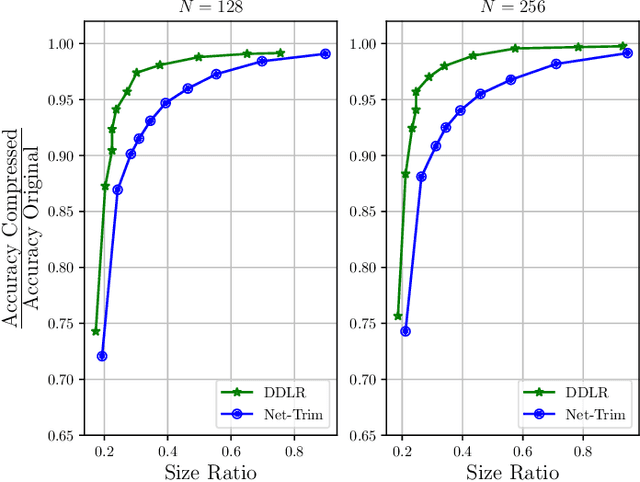
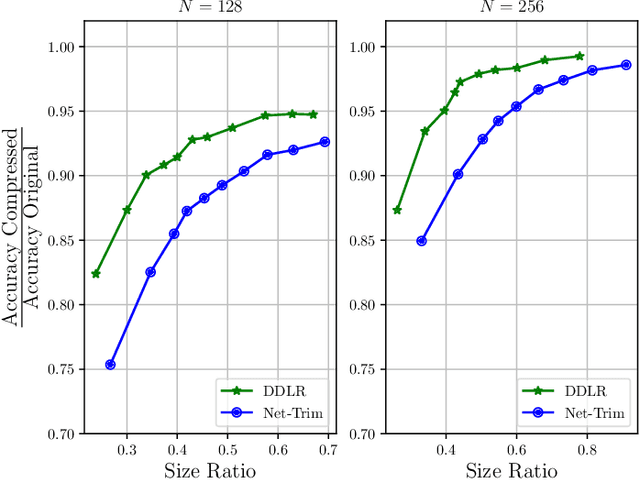
Despite many modern applications of Deep Neural Networks (DNNs), the large number of parameters in the hidden layers makes them unattractive for deployment on devices with storage capacity constraints. In this paper we propose a Data-Driven Low-rank (DDLR) method to reduce the number of parameters of pretrained DNNs and expedite inference by imposing low-rank structure on the fully connected layers, while controlling for the overall accuracy and without requiring any retraining. We pose the problem as finding the lowest rank approximation of each fully connected layer with given performance guarantees and relax it to a tractable convex optimization problem. We show that it is possible to significantly reduce the number of parameters in common DNN architectures with only a small reduction in classification accuracy. We compare DDLR with Net-Trim, which is another data-driven DNN compression technique based on sparsity and show that DDLR consistently produces more compressed neural networks while maintaining higher accuracy.
Efficacy of Bayesian Neural Networks in Active Learning
Apr 19, 2021

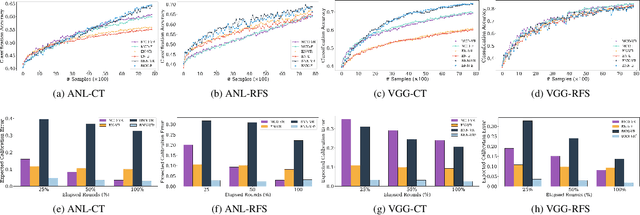
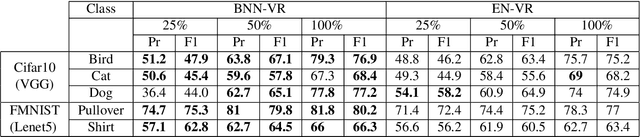
Obtaining labeled data for machine learning tasks can be prohibitively expensive. Active learning mitigates this issue by exploring the unlabeled data space and prioritizing the selection of data that can best improve the model performance. A common approach to active learning is to pick a small sample of data for which the model is most uncertain. In this paper, we explore the efficacy of Bayesian neural networks for active learning, which naturally models uncertainty by learning distribution over the weights of neural networks. By performing a comprehensive set of experiments, we show that Bayesian neural networks are more efficient than ensemble based techniques in capturing uncertainty. Our findings also reveal some key drawbacks of the ensemble techniques, which was recently shown to be more effective than Monte Carlo dropouts.
Matrix Completion in the Unit Hypercube via Structured Matrix Factorization
May 30, 2019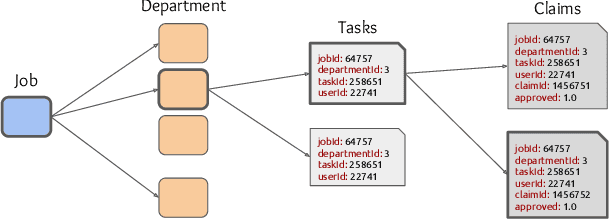


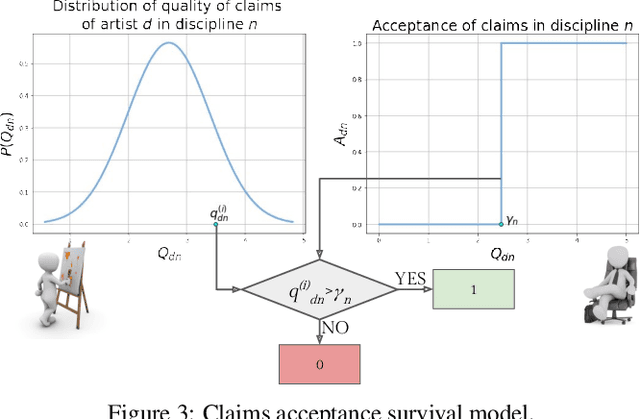
Several complex tasks that arise in organizations can be simplified by mapping them into a matrix completion problem. In this paper, we address a key challenge faced by our company: predicting the efficiency of artists in rendering visual effects (VFX) in film shots. We tackle this challenge by using a two-fold approach: first, we transform this task into a constrained matrix completion problem with entries bounded in the unit interval [0, 1]; second, we propose two novel matrix factorization models that leverage our knowledge of the VFX environment. Our first approach, expertise matrix factorization (EMF), is an interpretable method that structures the latent factors as weighted user-item interplay. The second one, survival matrix factorization (SMF), is instead a probabilistic model for the underlying process defining employees' efficiencies. We show the effectiveness of our proposed models by extensive numerical tests on our VFX dataset and two additional datasets with values that are also bounded in the [0, 1] interval.
Minimum Uncertainty Based Detection of Adversaries in Deep Neural Networks
Apr 05, 2019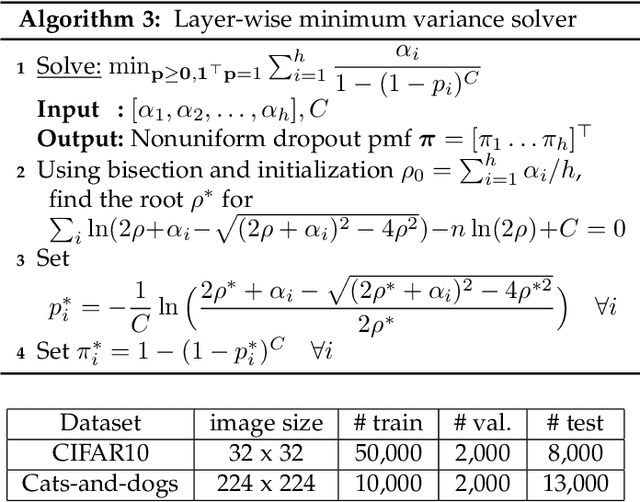
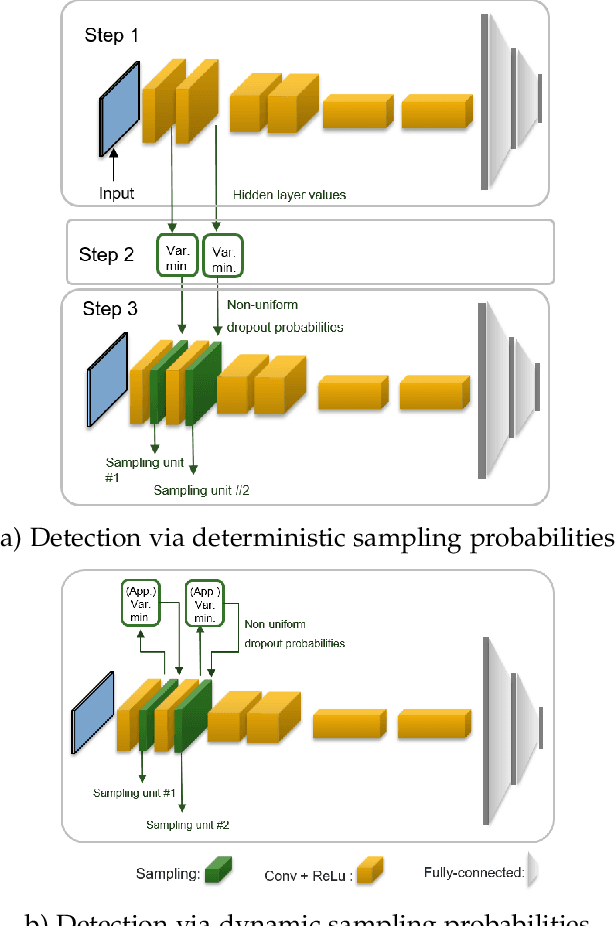
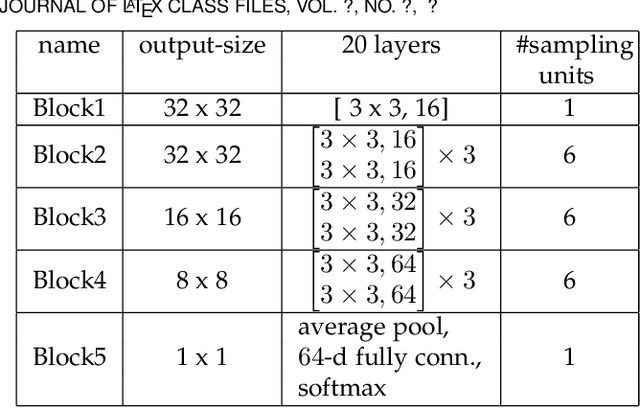
Despite their unprecedented performance in various domains, utilization of Deep Neural Networks (DNNs) in safety-critical environments is severely limited in the presence of even small adversarial perturbations. The present work develops a randomized approach to detecting such perturbations based on minimum uncertainty metrics that rely on sampling at the hidden layers during the DNN inference stage. The sampling probabilities are designed for effective detection of the adversarially corrupted inputs. Being modular, the novel detector of adversaries can be conveniently employed by any pre-trained DNN at no extra training overhead. Selecting which units to sample per hidden layer entails quantifying the amount of DNN output uncertainty from the viewpoint of Bayesian neural networks, where the overall uncertainty is expressed in terms of its layer-wise components - what also promotes scalability. Sampling probabilities are then sought by minimizing uncertainty measures layer-by-layer, leading to a novel convex optimization problem that admits an exact solver with superlinear convergence rate. By simplifying the objective function, low-complexity approximate solvers are also developed. In addition to valuable insights, these approximations link the novel approach with state-of-the-art randomized adversarial detectors. The effectiveness of the novel detectors in the context of competing alternatives is highlighted through extensive tests for various types of adversarial attacks with variable levels of strength.
Learning Generative Models of Structured Signals from Their Superposition Using GANs with Application to Denoising and Demixing
Feb 12, 2019



Recently, Generative Adversarial Networks (GANs) have emerged as a popular alternative for modeling complex high dimensional distributions. Most of the existing works implicitly assume that the clean samples from the target distribution are easily available. However, in many applications, this assumption is violated. In this paper, we consider the observation setting when the samples from target distribution are given by the superposition of two structured components and leverage GANs for learning the structure of the components. We propose two novel frameworks: denoising-GAN and demixing-GAN. The denoising-GAN assumes access to clean samples from the second component and try to learn the other distribution, whereas demixing-GAN learns the distribution of the components at the same time. Through extensive numerical experiments, we demonstrate that proposed frameworks can generate clean samples from unknown distributions, and provide competitive performance in tasks such as denoising, demixing, and compressive sensing.
Block CUR: Decomposing Matrices using Groups of Columns
Jul 09, 2018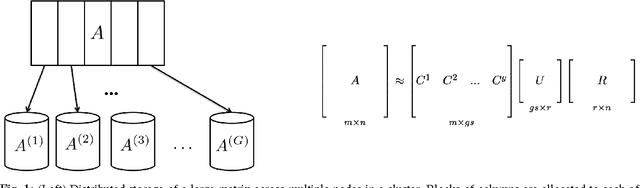
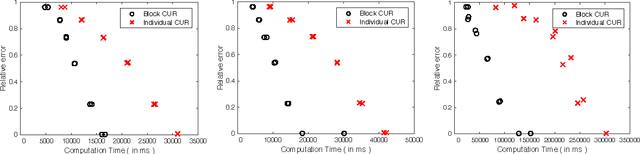
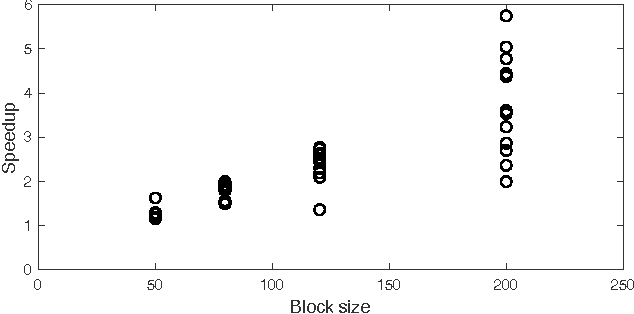
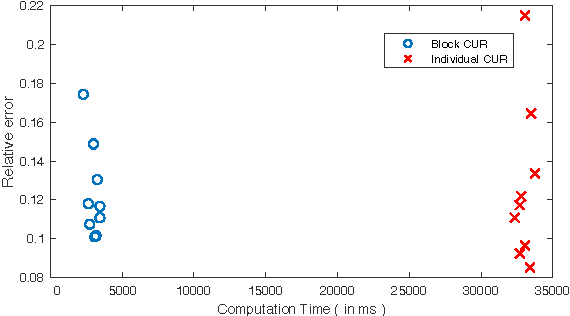
A common problem in large-scale data analysis is to approximate a matrix using a combination of specifically sampled rows and columns, known as CUR decomposition. Unfortunately, in many real-world environments, the ability to sample specific individual rows or columns of the matrix is limited by either system constraints or cost. In this paper, we consider matrix approximation by sampling predefined \emph{blocks} of columns (or rows) from the matrix. We present an algorithm for sampling useful column blocks and provide novel guarantees for the quality of the approximation. This algorithm has application in problems as diverse as biometric data analysis to distributed computing. We demonstrate the effectiveness of the proposed algorithms for computing the Block CUR decomposition of large matrices in a distributed setting with multiple nodes in a compute cluster, where such blocks correspond to columns (or rows) of the matrix stored on the same node, which can be retrieved with much less overhead than retrieving individual columns stored across different nodes. In the biometric setting, the rows correspond to different users and columns correspond to users' biometric reaction to external stimuli, {\em e.g.,}~watching video content, at a particular time instant. There is significant cost in acquiring each user's reaction to lengthy content so we sample a few important scenes to approximate the biometric response. An individual time sample in this use case cannot be queried in isolation due to the lack of context that caused that biometric reaction. Instead, collections of time segments ({\em i.e.,} blocks) must be presented to the user. The practical application of these algorithms is shown via experimental results using real-world user biometric data from a content testing environment.
Improved Support Recovery Guarantees for the Group Lasso With Applications to Structural Health Monitoring
May 19, 2018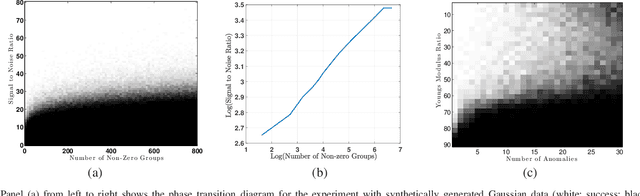
This paper considers the problem of estimating an unknown high dimensional signal from noisy linear measurements, {when} the signal is assumed to possess a \emph{group-sparse} structure in a {known,} fixed dictionary. We consider signals generated according to a natural probabilistic model, and establish new conditions under which the set of indices of the non-zero groups of the signal (called the group-level support) may be accurately estimated via the group Lasso. Our results strengthen existing coherence-based analyses that exhibit the well-known "square root" bottleneck, allowing for the number of recoverable nonzero groups to be nearly as large as the total number of groups. We also establish a sufficient recovery condition relating the number of nonzero groups and the signal to noise ratio (quantified in terms of the ratio of the squared Euclidean norms of nonzero groups and the variance of the random additive {measurement} noise), and validate this trend empirically. Finally, we examine the implications of our results in the context of a structural health monitoring application, where the group Lasso approach facilitates demixing of a propagating acoustic wavefield, acquired on the material surface by a scanning laser Doppler vibrometer, into antithetical components, one of which indicates the locations of internal material defects.
Noisy Tensor Completion for Tensors with a Sparse Canonical Polyadic Factor
Apr 08, 2017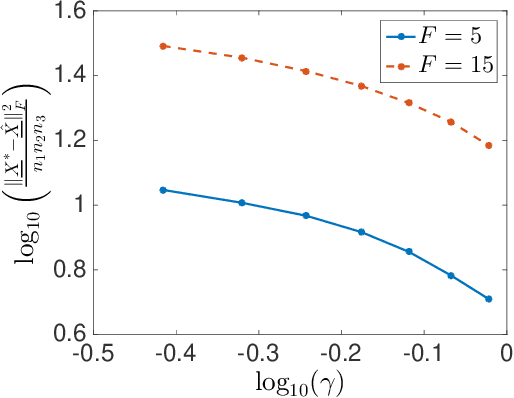
In this paper we study the problem of noisy tensor completion for tensors that admit a canonical polyadic or CANDECOMP/PARAFAC (CP) decomposition with one of the factors being sparse. We present general theoretical error bounds for an estimate obtained by using a complexity-regularized maximum likelihood principle and then instantiate these bounds for the case of additive white Gaussian noise. We also provide an ADMM-type algorithm for solving the complexity-regularized maximum likelihood problem and validate the theoretical finding via experiments on synthetic data set.
Rank-to-engage: New Listwise Approaches to Maximize Engagement
Feb 24, 2017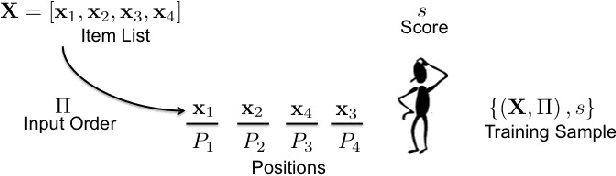



For many internet businesses, presenting a given list of items in an order that maximizes a certain metric of interest (e.g., click-through-rate, average engagement time etc.) is crucial. We approach the aforementioned task from a learning-to-rank perspective which reveals a new problem setup. In traditional learning-to-rank literature, it is implicitly assumed that during the training data generation one has access to the \emph{best or desired} order for the given list of items. In this work, we consider a problem setup where we do not observe the desired ranking. We present two novel solutions: the first solution is an extension of already existing listwise learning-to-rank technique--Listwise maximum likelihood estimation (ListMLE)--while the second one is a generic machine learning based framework that tackles the problem in its entire generality. We discuss several challenges associated with this generic framework, and propose a simple \emph{item-payoff} and \emph{positional-gain} model that addresses these challenges. We provide training algorithms, inference procedures, and demonstrate the effectiveness of the two approaches over traditional ListMLE on synthetic as well as on real-life setting of ranking news articles for increased dwell time.