 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTa-Chung Chi
Attention Alignment and Flexible Positional Embeddings Improve Transformer Length Extrapolation
Nov 15, 2023
An ideal length-extrapolatable Transformer language model can handle sequences longer than the training length without any fine-tuning. Such long-context utilization capability relies heavily on a flexible positional embedding design. Upon investigating the flexibility of existing large pre-trained Transformer language models, we find that the T5 family deserves a closer look, as its positional embeddings capture rich and flexible attention patterns. However, T5 suffers from the dispersed attention issue: the longer the input sequence, the flatter the attention distribution. To alleviate the issue, we propose two attention alignment strategies via temperature scaling. Our findings show improvement on the long-context utilization capability of T5 on language modeling, retrieval, multi-document question answering, and code completion tasks without any fine-tuning. This suggests that a flexible positional embedding design and attention alignment can go a long way toward Transformer length extrapolation.
Advancing Regular Language Reasoning in Linear Recurrent Neural Networks
Sep 14, 2023In recent studies, linear recurrent neural networks (LRNNs) have achieved Transformer-level performance in natural language modeling and long-range modeling while offering rapid parallel training and constant inference costs. With the resurged interest in LRNNs, we study whether they can learn the hidden rules in training sequences, such as the grammatical structures of regular language. We theoretically analyze some existing LRNNs and discover their limitations on regular language. Motivated by the analysis, we propose a new LRNN equipped with a block-diagonal and input-dependent transition matrix. Experiments suggest that the proposed model is the only LRNN that can perform length extrapolation on regular language tasks such as Sum, Even Pair, and Modular Arithmetic.
Structured Dialogue Discourse Parsing
Jun 26, 2023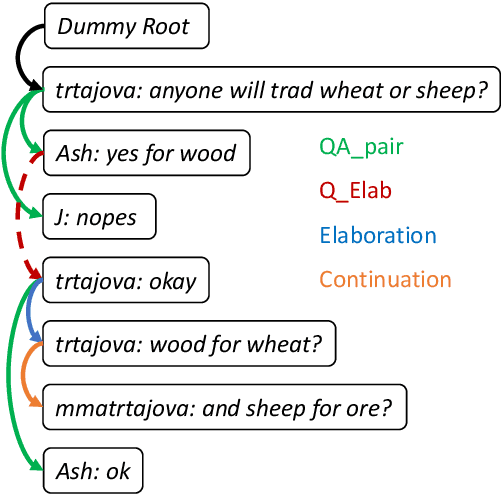


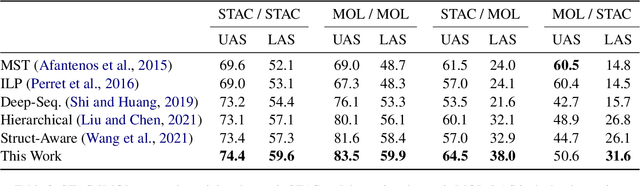
Dialogue discourse parsing aims to uncover the internal structure of a multi-participant conversation by finding all the discourse~\emph{links} and corresponding~\emph{relations}. Previous work either treats this task as a series of independent multiple-choice problems, in which the link existence and relations are decoded separately, or the encoding is restricted to only local interaction, ignoring the holistic structural information. In contrast, we propose a principled method that improves upon previous work from two perspectives: encoding and decoding. From the encoding side, we perform structured encoding on the adjacency matrix followed by the matrix-tree learning algorithm, where all discourse links and relations in the dialogue are jointly optimized based on latent tree-level distribution. From the decoding side, we perform structured inference using the modified Chiu-Liu-Edmonds algorithm, which explicitly generates the labeled multi-root non-projective spanning tree that best captures the discourse structure. In addition, unlike in previous work, we do not rely on hand-crafted features; this improves the model's robustness. Experiments show that our method achieves new state-of-the-art, surpassing the previous model by 2.3 on STAC and 1.5 on Molweni (F1 scores). \footnote{Code released at~\url{https://github.com/chijames/structured_dialogue_discourse_parsing}.}
PESCO: Prompt-enhanced Self Contrastive Learning for Zero-shot Text Classification
May 24, 2023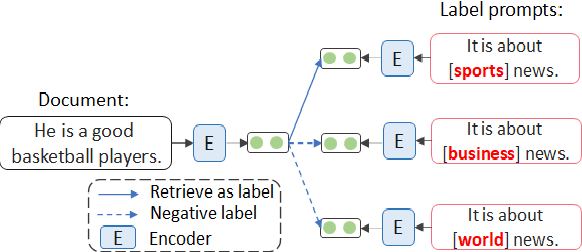



We present PESCO, a novel contrastive learning framework that substantially improves the performance of zero-shot text classification. We formulate text classification as a neural text matching problem where each document is treated as a query, and the system learns the mapping from each query to the relevant class labels by (1) adding prompts to enhance label matching, and (2) using retrieved labels to enrich the training set in a self-training loop of contrastive learning. PESCO achieves state-of-the-art performance on four benchmark text classification datasets. On DBpedia, we achieve 98.5\% accuracy without any labeled data, which is close to the fully-supervised result. Extensive experiments and analyses show all the components of PESCO are necessary for improving the performance of zero-shot text classification.
* accepted by ACL 2023
Latent Positional Information is in the Self-Attention Variance of Transformer Language Models Without Positional Embeddings
May 23, 2023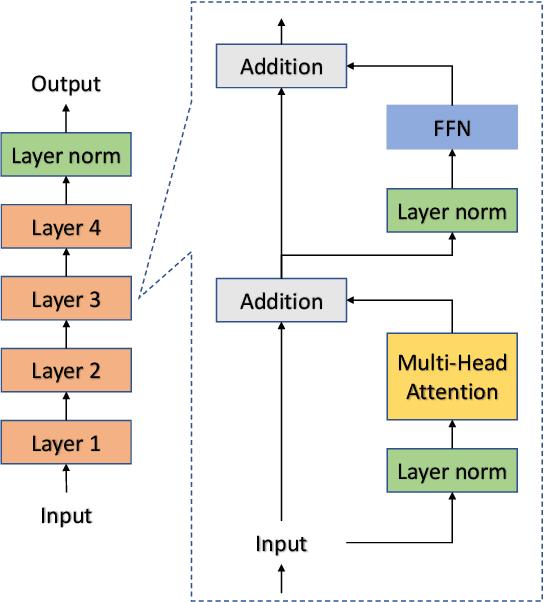


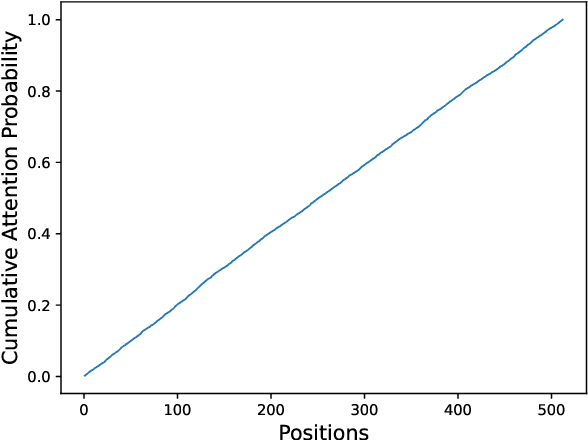
The use of positional embeddings in transformer language models is widely accepted. However, recent research has called into question the necessity of such embeddings. We further extend this inquiry by demonstrating that a randomly initialized and frozen transformer language model, devoid of positional embeddings, inherently encodes strong positional information through the shrinkage of self-attention variance. To quantify this variance, we derive the underlying distribution of each step within a transformer layer. Through empirical validation using a fully pretrained model, we show that the variance shrinkage effect still persists after extensive gradient updates. Our findings serve to justify the decision to discard positional embeddings and thus facilitate more efficient pretraining of transformer language models.
Transformer Working Memory Enables Regular Language Reasoning and Natural Language Length Extrapolation
May 05, 2023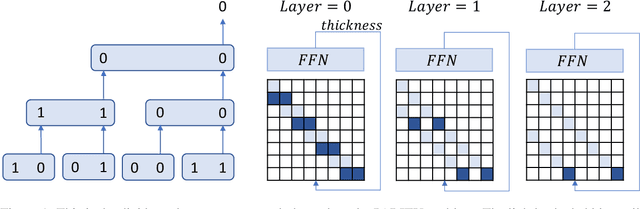
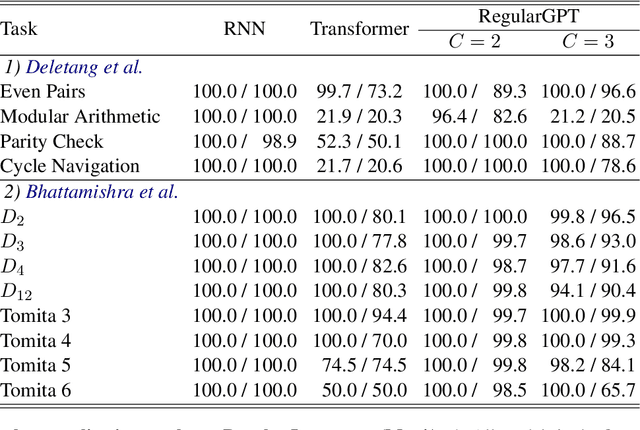

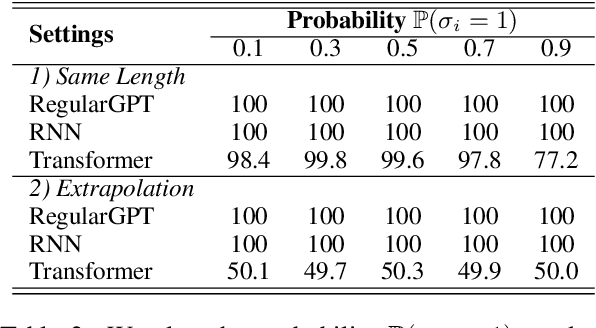
Unlike recurrent models, conventional wisdom has it that Transformers cannot perfectly model regular languages. Inspired by the notion of working memory, we propose a new Transformer variant named RegularGPT. With its novel combination of Weight-Sharing, Adaptive-Depth, and Sliding-Dilated-Attention, RegularGPT constructs working memory along the depth dimension, thereby enabling efficient and successful modeling of regular languages such as PARITY. We further test RegularGPT on the task of natural language length extrapolation and surprisingly find that it rediscovers the local windowed attention effect deemed necessary in prior work for length extrapolation.
Receptive Field Alignment Enables Transformer Length Extrapolation
Dec 20, 2022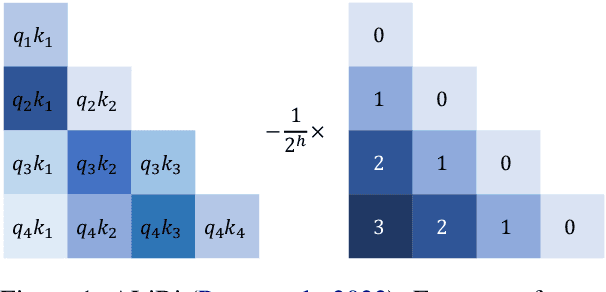
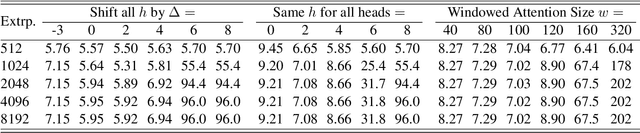
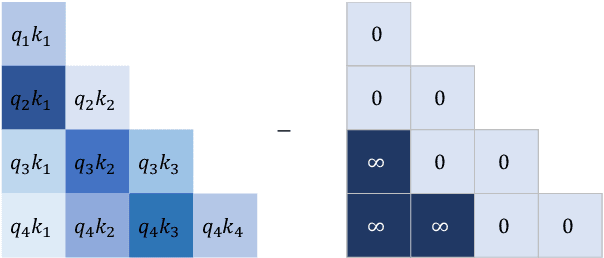
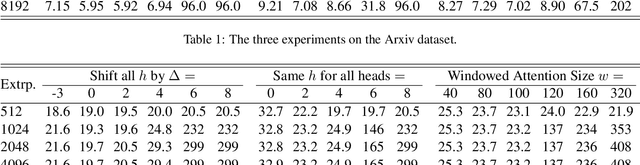
Length extrapolation is a desirable property that permits training a transformer language model on short sequences and retaining similar perplexities when the model is tested on substantially longer sequences. A relative positional embedding mechanism applied on the transformer self-attention matrix, ALiBi, demonstrates the length extrapolation property with the widest usage to date. In this paper, we show that ALiBi surprisingly does not utilize tokens further than the training sequence length, which can be explained by its implicit windowed attention effect that aligns the receptive field during training and testing stages. Inspired by ALiBi and the receptive filed alignment hypothesis, we propose another transformer positional embedding design named~\textbf{Sandwich} that uses longer than training sequence length information, and it is a greatly simplified formulation of the earliest proposed Sinusoidal positional embedding. Finally, we show that both ALiBi and Sandwich enable efficient inference thanks to their implicit windowed attention effect.
On Task-Adaptive Pretraining for Dialogue Response Selection
Oct 08, 2022
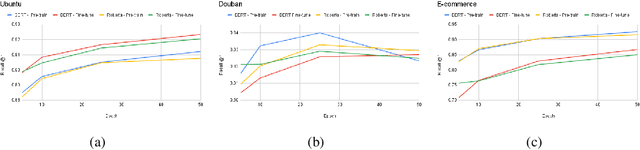
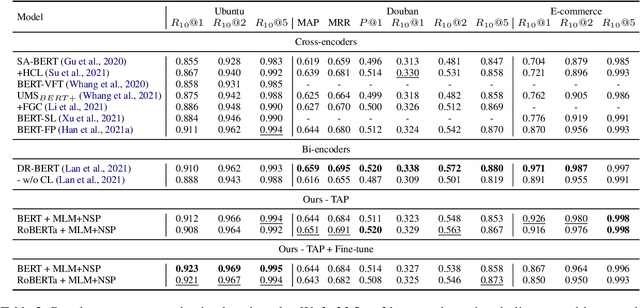
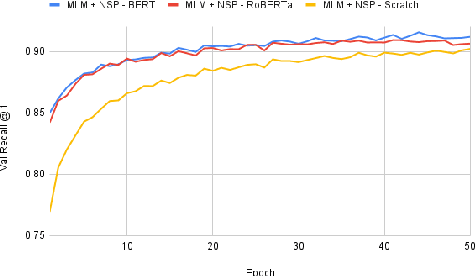
Recent advancements in dialogue response selection (DRS) are based on the \textit{task-adaptive pre-training (TAP)} approach, by first initializing their model with BERT~\cite{devlin-etal-2019-bert}, and adapt to dialogue data with dialogue-specific or fine-grained pre-training tasks. However, it is uncertain whether BERT is the best initialization choice, or whether the proposed dialogue-specific fine-grained learning tasks are actually better than MLM+NSP. This paper aims to verify assumptions made in previous works and understand the source of improvements for DRS. We show that initializing with RoBERTa achieve similar performance as BERT, and MLM+NSP can outperform all previously proposed TAP tasks, during which we also contribute a new state-of-the-art on the Ubuntu corpus. Additional analyses shows that the main source of improvements comes from the TAP step, and that the NSP task is crucial to DRS, different from common NLU tasks.
Training Discrete Deep Generative Models via Gapped Straight-Through Estimator
Jun 15, 2022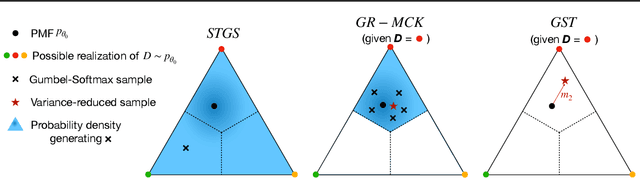
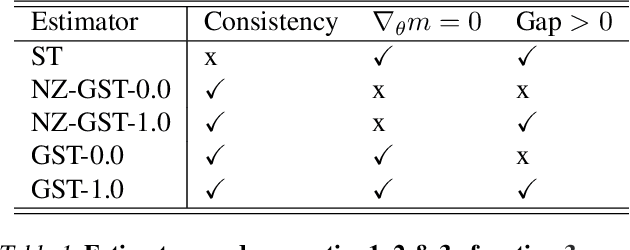
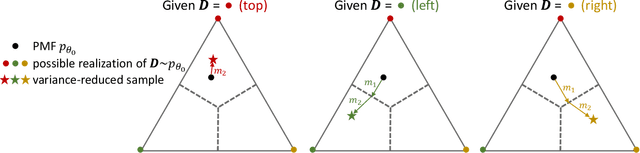
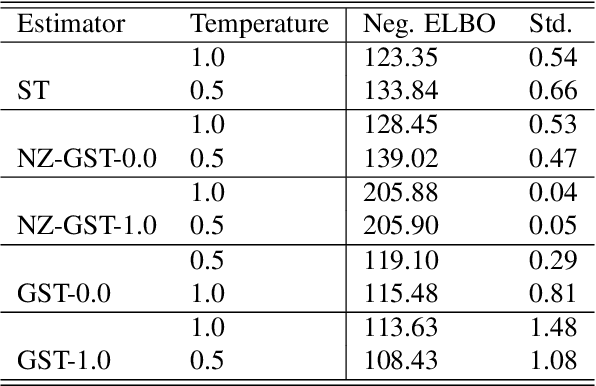
While deep generative models have succeeded in image processing, natural language processing, and reinforcement learning, training that involves discrete random variables remains challenging due to the high variance of its gradient estimation process. Monte Carlo is a common solution used in most variance reduction approaches. However, this involves time-consuming resampling and multiple function evaluations. We propose a Gapped Straight-Through (GST) estimator to reduce the variance without incurring resampling overhead. This estimator is inspired by the essential properties of Straight-Through Gumbel-Softmax. We determine these properties and show via an ablation study that they are essential. Experiments demonstrate that the proposed GST estimator enjoys better performance compared to strong baselines on two discrete deep generative modeling tasks, MNIST-VAE and ListOps.
KERPLE: Kernelized Relative Positional Embedding for Length Extrapolation
May 20, 2022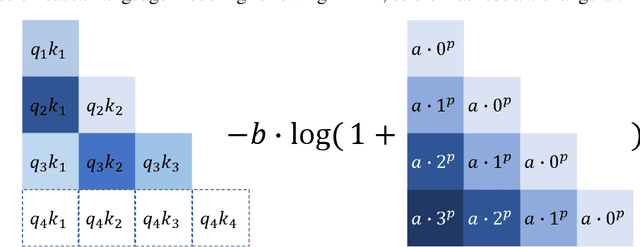
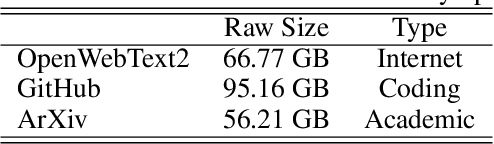

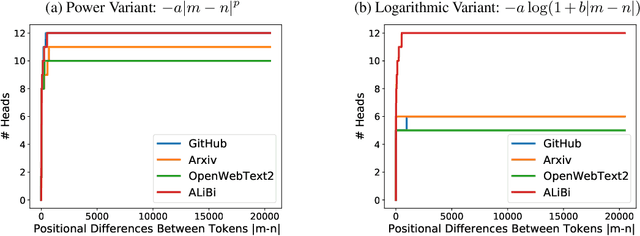
Relative positional embeddings (RPE) have received considerable attention since RPEs effectively model the relative distance among tokens and enable length extrapolation. We propose KERPLE, a framework that generalizes relative position embedding for extrapolation by kernelizing positional differences. We achieve this goal using conditionally positive definite (CPD) kernels, a class of functions known for generalizing distance metrics. To maintain the inner product interpretation of self-attention, we show that a CPD kernel can be transformed into a PD kernel by adding a constant offset. This offset is implicitly absorbed in the Softmax normalization during self-attention. The diversity of CPD kernels allows us to derive various RPEs that enable length extrapolation in a principled way. Experiments demonstrate that the logarithmic variant achieves excellent extrapolation performance on three large language modeling datasets.