 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaketo Akama
A Computational Analysis of Lyric Similarity Perception
Apr 02, 2024
In musical compositions that include vocals, lyrics significantly contribute to artistic expression. Consequently, previous studies have introduced the concept of a recommendation system that suggests lyrics similar to a user's favorites or personalized preferences, aiding in the discovery of lyrics among millions of tracks. However, many of these systems do not fully consider human perceptions of lyric similarity, primarily due to limited research in this area. To bridge this gap, we conducted a comparative analysis of computational methods for modeling lyric similarity with human perception. Results indicated that computational models based on similarities between embeddings from pre-trained BERT-based models, the audio from which the lyrics are derived, and phonetic components are indicative of perceptual lyric similarity. This finding underscores the importance of semantic, stylistic, and phonetic similarities in human perception about lyric similarity. We anticipate that our findings will enhance the development of similarity-based lyric recommendation systems by offering pseudo-labels for neural network development and introducing objective evaluation metrics.
HyperGANStrument: Instrument Sound Synthesis and Editing with Pitch-Invariant Hypernetworks
Jan 09, 2024GANStrument, exploiting GANs with a pitch-invariant feature extractor and instance conditioning technique, has shown remarkable capabilities in synthesizing realistic instrument sounds. To further improve the reconstruction ability and pitch accuracy to enhance the editability of user-provided sound, we propose HyperGANStrument, which introduces a pitch-invariant hypernetwork to modulate the weights of a pre-trained GANStrument generator, given a one-shot sound as input. The hypernetwork modulation provides feedback for the generator in the reconstruction of the input sound. In addition, we take advantage of an adversarial fine-tuning scheme for the hypernetwork to improve the reconstruction fidelity and generation diversity of the generator. Experimental results show that the proposed model not only enhances the generation capability of GANStrument but also significantly improves the editability of synthesized sounds. Audio examples are available at the online demo page.
Annotation-free Automatic Music Transcription with Scalable Synthetic Data and Adversarial Domain Confusion
Dec 31, 2023Automatic Music Transcription (AMT) is a vital technology in the field of music information processing. Despite recent enhancements in performance due to machine learning techniques, current methods typically attain high accuracy in domains where abundant annotated data is available. Addressing domains with low or no resources continues to be an unresolved challenge. To tackle this issue, we propose a transcription model that does not require any MIDI-audio paired data through the utilization of scalable synthetic audio for pre-training and adversarial domain confusion using unannotated real audio. In experiments, we evaluate methods under the real-world application scenario where training datasets do not include the MIDI annotation of audio in the target data domain. Our proposed method achieved competitive performance relative to established baseline methods, despite not utilizing any real datasets of paired MIDI-audio. Additionally, ablation studies have provided insights into the scalability of this approach and the forthcoming challenges in the field of AMT research.
Automatic Piano Transcription with Hierarchical Frequency-Time Transformer
Jul 10, 2023

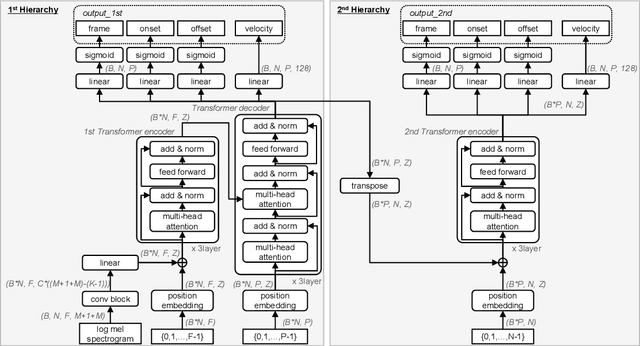
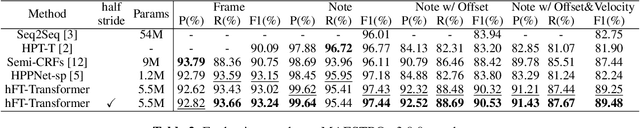
Taking long-term spectral and temporal dependencies into account is essential for automatic piano transcription. This is especially helpful when determining the precise onset and offset for each note in the polyphonic piano content. In this case, we may rely on the capability of self-attention mechanism in Transformers to capture these long-term dependencies in the frequency and time axes. In this work, we propose hFT-Transformer, which is an automatic music transcription method that uses a two-level hierarchical frequency-time Transformer architecture. The first hierarchy includes a convolutional block in the time axis, a Transformer encoder in the frequency axis, and a Transformer decoder that converts the dimension in the frequency axis. The output is then fed into the second hierarchy which consists of another Transformer encoder in the time axis. We evaluated our method with the widely used MAPS and MAESTRO v3.0.0 datasets, and it demonstrated state-of-the-art performance on all the F1-scores of the metrics among Frame, Note, Note with Offset, and Note with Offset and Velocity estimations.
Self-supervised Auxiliary Loss for Metric Learning in Music Similarity-based Retrieval and Auto-tagging
Apr 15, 2023



In the realm of music information retrieval, similarity-based retrieval and auto-tagging serve as essential components. Given the limitations and non-scalability of human supervision signals, it becomes crucial for models to learn from alternative sources to enhance their performance. Self-supervised learning, which exclusively relies on learning signals derived from music audio data, has demonstrated its efficacy in the context of auto-tagging. In this study, we propose a model that builds on the self-supervised learning approach to address the similarity-based retrieval challenge by introducing our method of metric learning with a self-supervised auxiliary loss. Furthermore, diverging from conventional self-supervised learning methodologies, we discovered the advantages of concurrently training the model with both self-supervision and supervision signals, without freezing pre-trained models. We also found that refraining from employing augmentation during the fine-tuning phase yields better results. Our experimental results confirm that the proposed methodology enhances retrieval and tagging performance metrics in two distinct scenarios: one where human-annotated tags are consistently available for all music tracks, and another where such tags are accessible only for a subset of tracks.
GANStrument: Adversarial Instrument Sound Synthesis with Pitch-invariant Instance Conditioning
Nov 10, 2022



We propose GANStrument, a generative adversarial model for instrument sound synthesis. Given a one-shot sound as input, it is able to generate pitched instrument sounds that reflect the timbre of the input within an interactive time. By exploiting instance conditioning, GANStrument achieves better fidelity and diversity of synthesized sounds and generalization ability to various inputs. In addition, we introduce an adversarial training scheme for a pitch-invariant feature extractor that significantly improves the pitch accuracy and timbre consistency. Experimental results show that GANStrument outperforms strong baselines that do not use instance conditioning in terms of generation quality and input editability. Qualitative examples are available online.
A Contextual Latent Space Model: Subsequence Modulation in Melodic Sequence
Nov 23, 2021


Some generative models for sequences such as music and text allow us to edit only subsequences, given surrounding context sequences, which plays an important part in steering generation interactively. However, editing subsequences mainly involves randomly resampling subsequences from a possible generation space. We propose a contextual latent space model (CLSM) in order for users to be able to explore subsequence generation with a sense of direction in the generation space, e.g., interpolation, as well as exploring variations -- semantically similar possible subsequences. A context-informed prior and decoder constitute the generative model of CLSM, and a context position-informed encoder is the inference model. In experiments, we use a monophonic symbolic music dataset, demonstrating that our contextual latent space is smoother in interpolation than baselines, and the quality of generated samples is superior to baseline models. The generation examples are available online.