 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaoxing Pan
Efficient Exploration in Resource-Restricted Reinforcement Learning
Dec 14, 2022
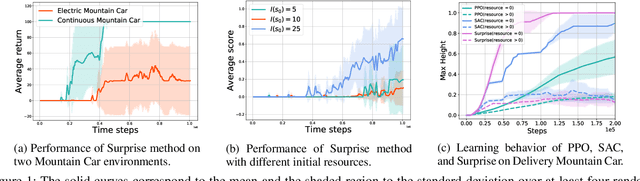
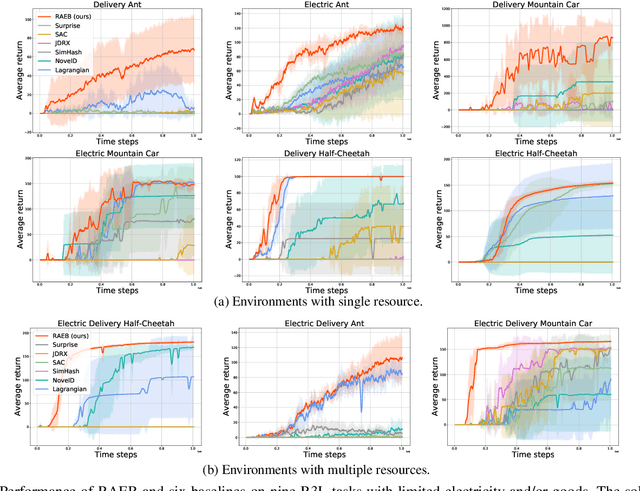
In many real-world applications of reinforcement learning (RL), performing actions requires consuming certain types of resources that are non-replenishable in each episode. Typical applications include robotic control with limited energy and video games with consumable items. In tasks with non-replenishable resources, we observe that popular RL methods such as soft actor critic suffer from poor sample efficiency. The major reason is that, they tend to exhaust resources fast and thus the subsequent exploration is severely restricted due to the absence of resources. To address this challenge, we first formalize the aforementioned problem as a resource-restricted reinforcement learning, and then propose a novel resource-aware exploration bonus (RAEB) to make reasonable usage of resources. An appealing feature of RAEB is that, it can significantly reduce unnecessary resource-consuming trials while effectively encouraging the agent to explore unvisited states. Experiments demonstrate that the proposed RAEB significantly outperforms state-of-the-art exploration strategies in resource-restricted reinforcement learning environments, improving the sample efficiency by up to an order of magnitude.
Technical Report of Team GraphMIRAcles in the WikiKG90M-LSC Track of OGB-LSC @ KDD Cup 2021
Jul 12, 2021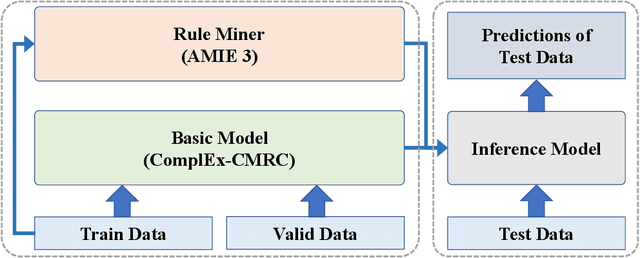

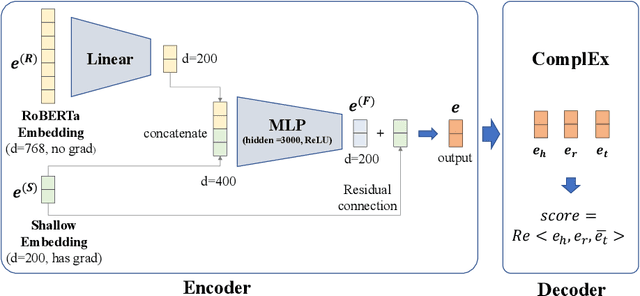

Link prediction in large-scale knowledge graphs has gained increasing attention recently. The OGB-LSC team presented OGB Large-Scale Challenge (OGB-LSC), a collection of three real-world datasets for advancing the state-of-the-art in large-scale graph machine learning. In this paper, we introduce the solution of our team GraphMIRAcles in the WikiKG90M-LSC track of OGB-LSC @ KDD Cup 2021. In the WikiKG90M-LSC track, the goal is to automatically predict missing links in WikiKG90M, a large scale knowledge graph extracted from Wikidata. To address this challenge, we propose a framework that integrates three components -- a basic model ComplEx-CMRC, a rule miner AMIE 3, and an inference model to predict missing links. Experiments demonstrate that our solution achieves an MRR of 0.9707 on the test dataset. Moreover, as the knowledge distillation in the inference model uses test tail candidates -- which are unavailable in practice -- we conduct ablation studies on knowledge distillation. Experiments demonstrate that our model without knowledge distillation achieves an MRR of 0.9533 on the full validation dataset.
D-SPIDER-SFO: A Decentralized Optimization Algorithm with Faster Convergence Rate for Nonconvex Problems
Nov 28, 2019
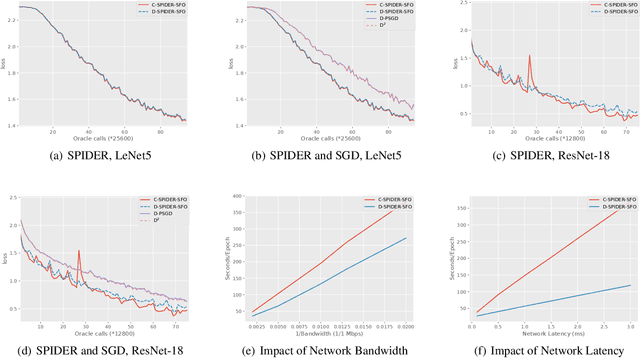
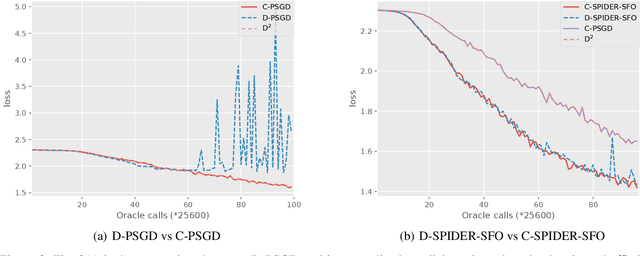
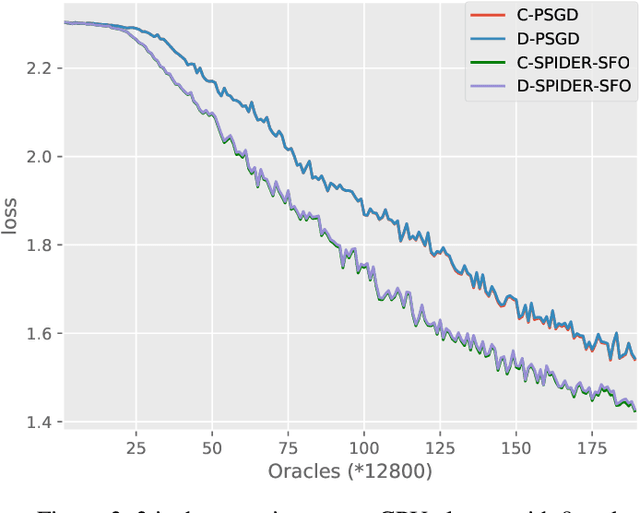
Decentralized optimization algorithms have attracted intensive interests recently, as it has a balanced communication pattern, especially when solving large-scale machine learning problems. Stochastic Path Integrated Differential Estimator Stochastic First-Order method (SPIDER-SFO) nearly achieves the algorithmic lower bound in certain regimes for nonconvex problems. However, whether we can find a decentralized algorithm which achieves a similar convergence rate to SPIDER-SFO is still unclear. To tackle this problem, we propose a decentralized variant of SPIDER-SFO, called decentralized SPIDER-SFO (D-SPIDER-SFO). We show that D-SPIDER-SFO achieves a similar gradient computation cost---that is, $\mathcal{O}(\epsilon^{-3})$ for finding an $\epsilon$-approximate first-order stationary point---to its centralized counterpart. To the best of our knowledge, D-SPIDER-SFO achieves the state-of-the-art performance for solving nonconvex optimization problems on decentralized networks in terms of the computational cost. Experiments on different network configurations demonstrate the efficiency of the proposed method.