 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerrence Chen
Self-learning Canonical Space for Multi-view 3D Human Pose Estimation
Mar 29, 2024
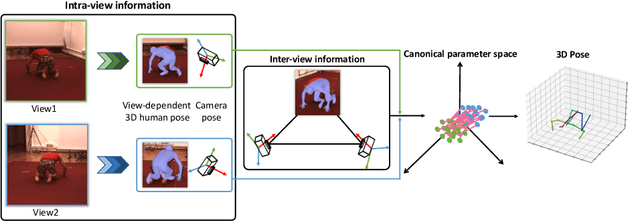
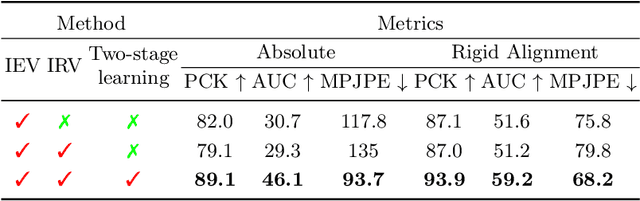
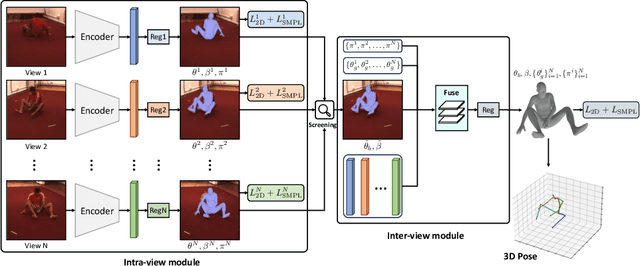
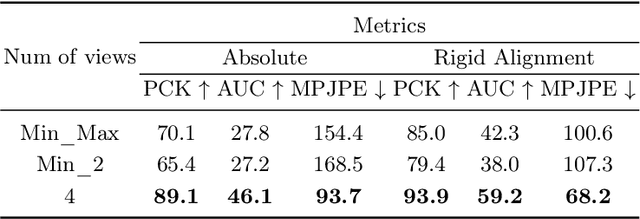
Multi-view 3D human pose estimation is naturally superior to single view one, benefiting from more comprehensive information provided by images of multiple views. The information includes camera poses, 2D/3D human poses, and 3D geometry. However, the accurate annotation of these information is hard to obtain, making it challenging to predict accurate 3D human pose from multi-view images. To deal with this issue, we propose a fully self-supervised framework, named cascaded multi-view aggregating network (CMANet), to construct a canonical parameter space to holistically integrate and exploit multi-view information. In our framework, the multi-view information is grouped into two categories: 1) intra-view information , 2) inter-view information. Accordingly, CMANet consists of two components: intra-view module (IRV) and inter-view module (IEV). IRV is used for extracting initial camera pose and 3D human pose of each view; IEV is to fuse complementary pose information and cross-view 3D geometry for a final 3D human pose. To facilitate the aggregation of the intra- and inter-view, we define a canonical parameter space, depicted by per-view camera pose and human pose and shape parameters ($\theta$ and $\beta$) of SMPL model, and propose a two-stage learning procedure. At first stage, IRV learns to estimate camera pose and view-dependent 3D human pose supervised by confident output of an off-the-shelf 2D keypoint detector. At second stage, IRV is frozen and IEV further refines the camera pose and optimizes the 3D human pose by implicitly encoding the cross-view complement and 3D geometry constraint, achieved by jointly fitting predicted multi-view 2D keypoints. The proposed framework, modules, and learning strategy are demonstrated to be effective by comprehensive experiments and CMANet is superior to state-of-the-art methods in extensive quantitative and qualitative analysis.
Human Mesh Recovery from Arbitrary Multi-view Images
Mar 20, 2024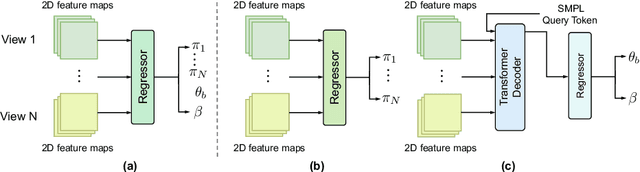
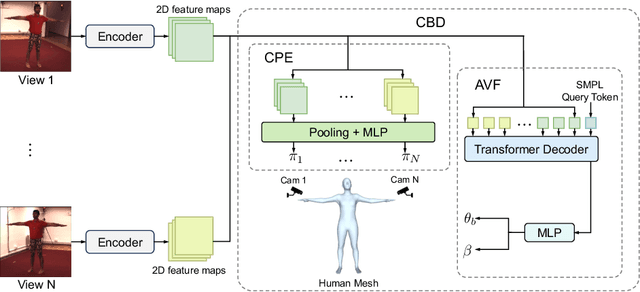
Human mesh recovery from arbitrary multi-view images involves two characteristics: the arbitrary camera poses and arbitrary number of camera views. Because of the variability, designing a unified framework to tackle this task is challenging. The challenges can be summarized as the dilemma of being able to simultaneously estimate arbitrary camera poses and recover human mesh from arbitrary multi-view images while maintaining flexibility. To solve this dilemma, we propose a divide and conquer framework for Unified Human Mesh Recovery (U-HMR) from arbitrary multi-view images. In particular, U-HMR consists of a decoupled structure and two main components: camera and body decoupling (CBD), camera pose estimation (CPE), and arbitrary view fusion (AVF). As camera poses and human body mesh are independent of each other, CBD splits the estimation of them into two sub-tasks for two individual sub-networks (\ie, CPE and AVF) to handle respectively, thus the two sub-tasks are disentangled. In CPE, since each camera pose is unrelated to the others, we adopt a shared MLP to process all views in a parallel way. In AVF, in order to fuse multi-view information and make the fusion operation independent of the number of views, we introduce a transformer decoder with a SMPL parameters query token to extract cross-view features for mesh recovery. To demonstrate the efficacy and flexibility of the proposed framework and effect of each component, we conduct extensive experiments on three public datasets: Human3.6M, MPI-INF-3DHP, and TotalCapture.
Spatiotemporal Diffusion Model with Paired Sampling for Accelerated Cardiac Cine MRI
Mar 13, 2024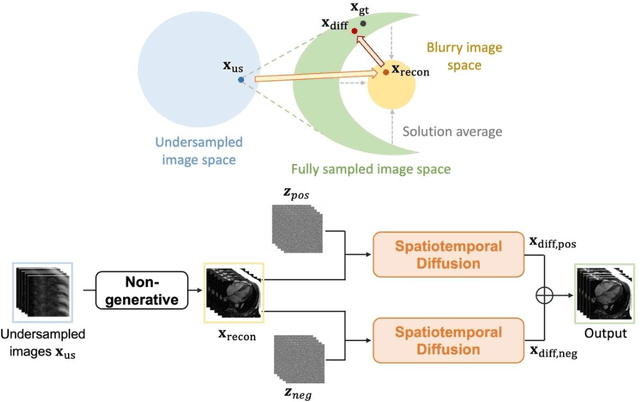
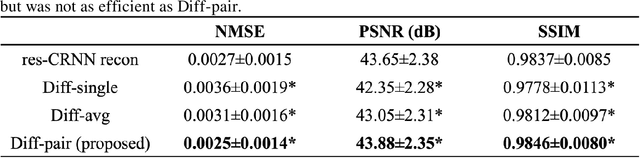
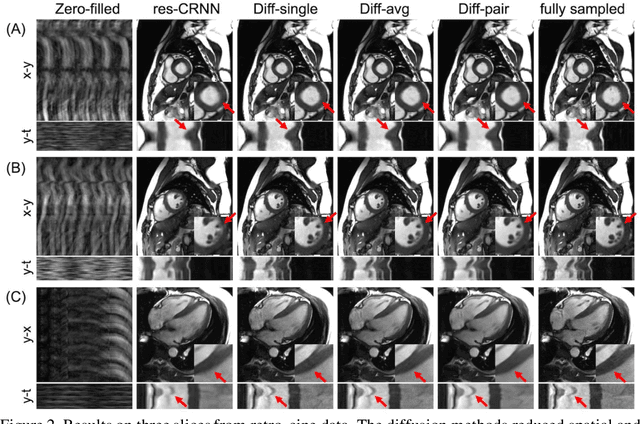
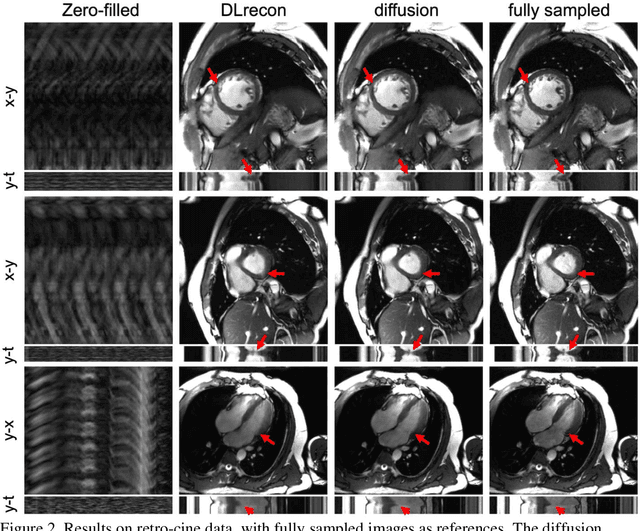
Current deep learning reconstruction for accelerated cardiac cine MRI suffers from spatial and temporal blurring. We aim to improve image sharpness and motion delineation for cine MRI under high undersampling rates. A spatiotemporal diffusion enhancement model conditional on an existing deep learning reconstruction along with a novel paired sampling strategy was developed. The diffusion model provided sharper tissue boundaries and clearer motion than the original reconstruction in experts evaluation on clinical data. The innovative paired sampling strategy substantially reduced artificial noises in the generative results.
Clinically Feasible Diffusion Reconstruction for Highly-Accelerated Cardiac Cine MRI
Mar 13, 2024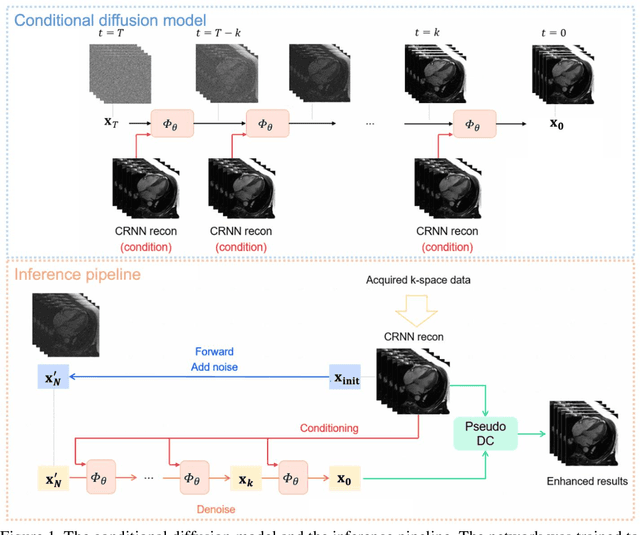
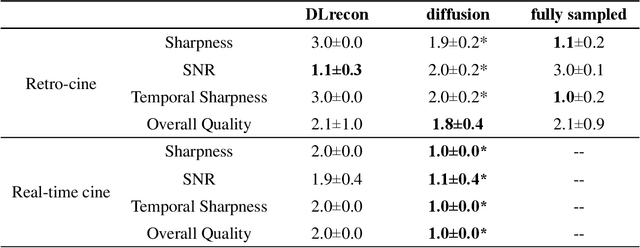
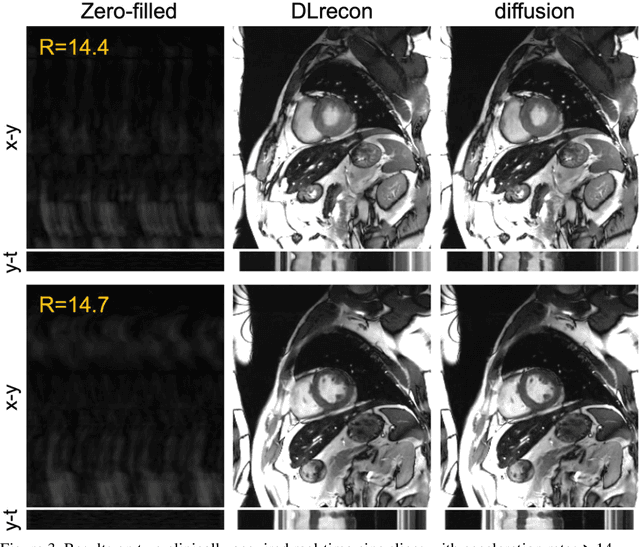
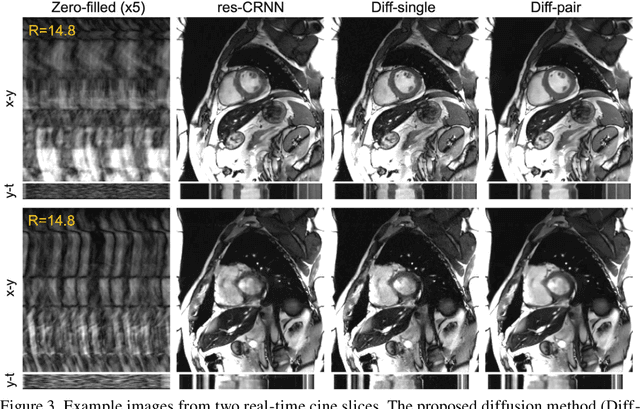
The currently limited quality of accelerated cardiac cine reconstruction may potentially be improved by the emerging diffusion models, but the clinically unacceptable long processing time poses a challenge. We aim to develop a clinically feasible diffusion-model-based reconstruction pipeline to improve the image quality of cine MRI. A multi-in multi-out diffusion enhancement model together with fast inference strategies were developed to be used in conjunction with a reconstruction model. The diffusion reconstruction reduced spatial and temporal blurring in prospectively undersampled clinical data, as validated by experts inspection. The 1.5s per video processing time enabled the approach to be applied in clinical scenarios.
Federated Data Model
Mar 13, 2024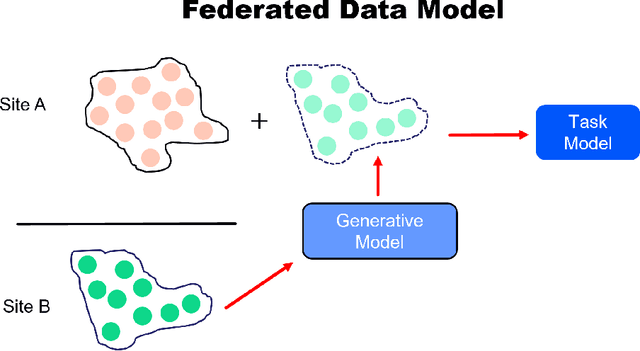
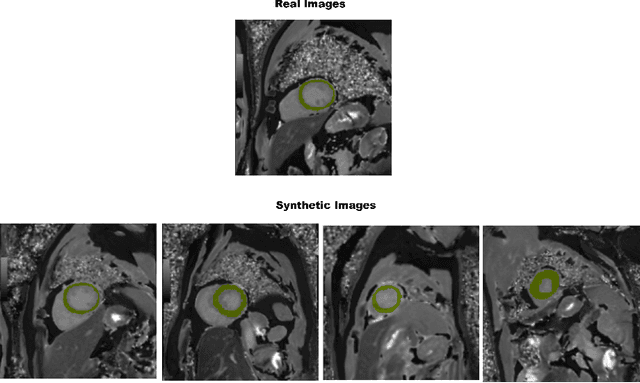
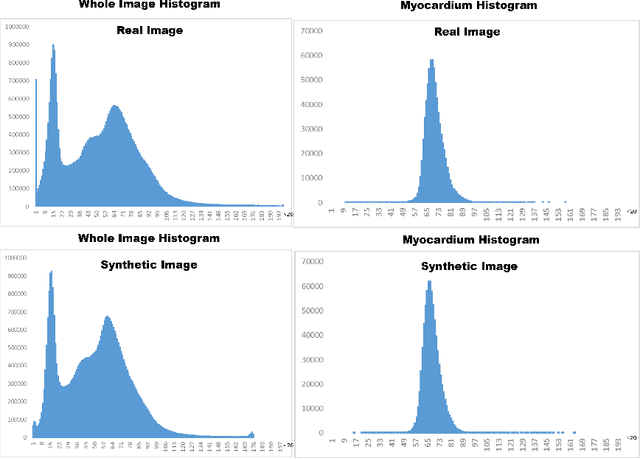
In artificial intelligence (AI), especially deep learning, data diversity and volume play a pivotal role in model development. However, training a robust deep learning model often faces challenges due to data privacy, regulations, and the difficulty of sharing data between different locations, especially for medical applications. To address this, we developed a method called the Federated Data Model (FDM). This method uses diffusion models to learn the characteristics of data at one site and then creates synthetic data that can be used at another site without sharing the actual data. We tested this approach with a medical image segmentation task, focusing on cardiac magnetic resonance images from different hospitals. Our results show that models trained with this method perform well both on the data they were originally trained on and on data from other sites. This approach offers a promising way to train accurate and privacy-respecting AI models across different locations.
Automating Catheterization Labs with Real-Time Perception
Mar 09, 2024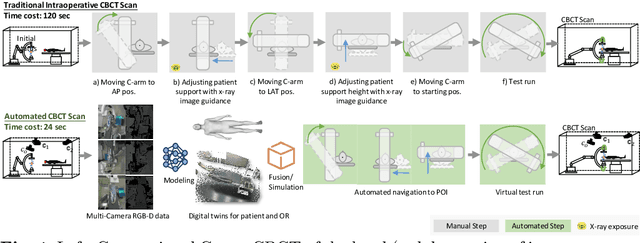
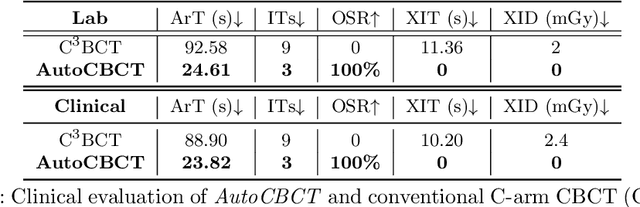
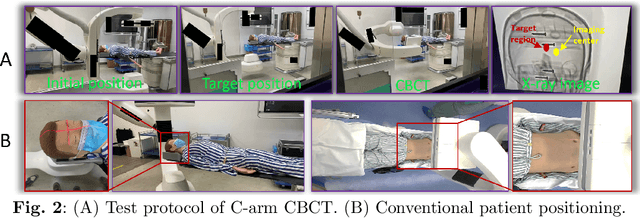
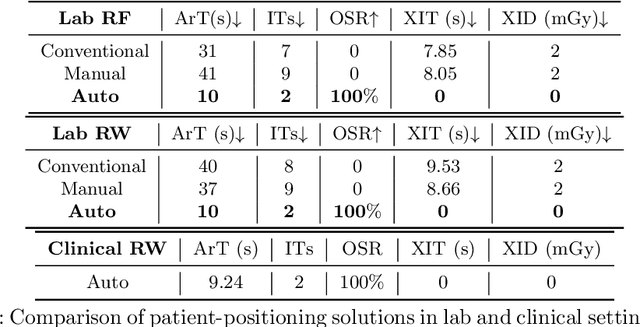
For decades, three-dimensional C-arm Cone-Beam Computed Tomography (CBCT) imaging system has been a critical component for complex vascular and nonvascular interventional procedures. While it can significantly improve multiplanar soft tissue imaging and provide pre-treatment target lesion roadmapping and guidance, the traditional workflow can be cumbersome and time-consuming, especially for less experienced users. To streamline this process and enhance procedural efficiency overall, we proposed a visual perception system, namely AutoCBCT, seamlessly integrated with an angiography suite. This system dynamically models both the patient's body and the surgical environment in real-time. AutoCBCT enables a novel workflow with automated positioning, navigation and simulated test-runs, eliminating the need for manual operations and interactions. The proposed system has been successfully deployed and studied in both lab and clinical settings, demonstrating significantly improved workflow efficiency.
Self-supervised 3D Patient Modeling with Multi-modal Attentive Fusion
Mar 05, 20243D patient body modeling is critical to the success of automated patient positioning for smart medical scanning and operating rooms. Existing CNN-based end-to-end patient modeling solutions typically require a) customized network designs demanding large amount of relevant training data, covering extensive realistic clinical scenarios (e.g., patient covered by sheets), which leads to suboptimal generalizability in practical deployment, b) expensive 3D human model annotations, i.e., requiring huge amount of manual effort, resulting in systems that scale poorly. To address these issues, we propose a generic modularized 3D patient modeling method consists of (a) a multi-modal keypoint detection module with attentive fusion for 2D patient joint localization, to learn complementary cross-modality patient body information, leading to improved keypoint localization robustness and generalizability in a wide variety of imaging (e.g., CT, MRI etc.) and clinical scenarios (e.g., heavy occlusions); and (b) a self-supervised 3D mesh regression module which does not require expensive 3D mesh parameter annotations to train, bringing immediate cost benefits for clinical deployment. We demonstrate the efficacy of the proposed method by extensive patient positioning experiments on both public and clinical data. Our evaluation results achieve superior patient positioning performance across various imaging modalities in real clinical scenarios.
DaReNeRF: Direction-aware Representation for Dynamic Scenes
Mar 04, 2024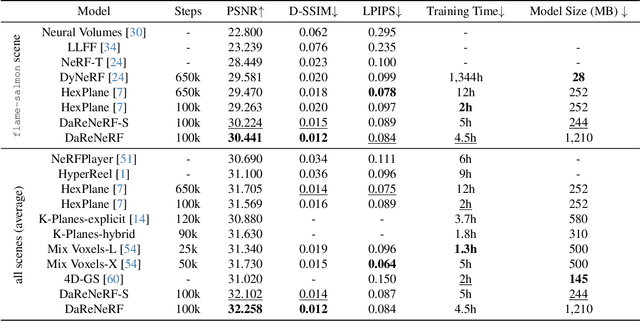
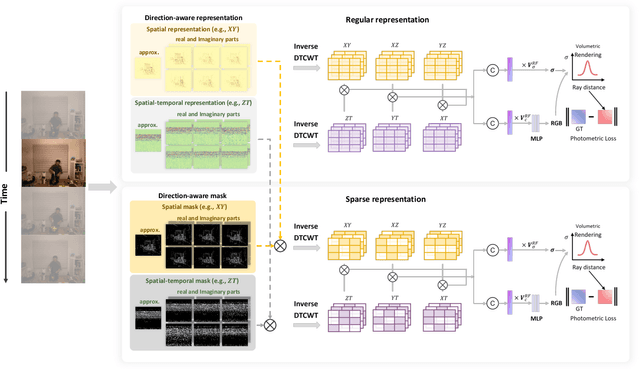
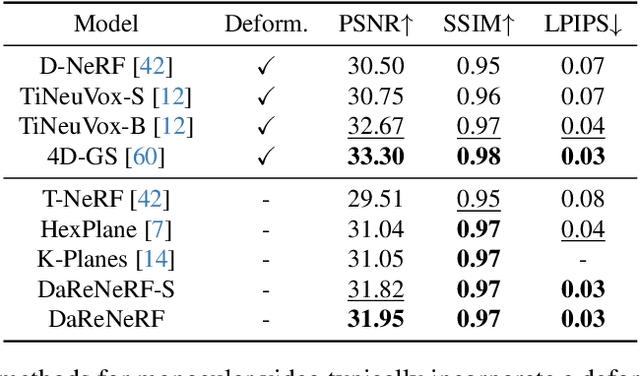
Addressing the intricate challenge of modeling and re-rendering dynamic scenes, most recent approaches have sought to simplify these complexities using plane-based explicit representations, overcoming the slow training time issues associated with methods like Neural Radiance Fields (NeRF) and implicit representations. However, the straightforward decomposition of 4D dynamic scenes into multiple 2D plane-based representations proves insufficient for re-rendering high-fidelity scenes with complex motions. In response, we present a novel direction-aware representation (DaRe) approach that captures scene dynamics from six different directions. This learned representation undergoes an inverse dual-tree complex wavelet transformation (DTCWT) to recover plane-based information. DaReNeRF computes features for each space-time point by fusing vectors from these recovered planes. Combining DaReNeRF with a tiny MLP for color regression and leveraging volume rendering in training yield state-of-the-art performance in novel view synthesis for complex dynamic scenes. Notably, to address redundancy introduced by the six real and six imaginary direction-aware wavelet coefficients, we introduce a trainable masking approach, mitigating storage issues without significant performance decline. Moreover, DaReNeRF maintains a 2x reduction in training time compared to prior art while delivering superior performance.
PBADet: A One-Stage Anchor-Free Approach for Part-Body Association
Feb 12, 2024The detection of human parts (e.g., hands, face) and their correct association with individuals is an essential task, e.g., for ubiquitous human-machine interfaces and action recognition. Traditional methods often employ multi-stage processes, rely on cumbersome anchor-based systems, or do not scale well to larger part sets. This paper presents PBADet, a novel one-stage, anchor-free approach for part-body association detection. Building upon the anchor-free object representation across multi-scale feature maps, we introduce a singular part-to-body center offset that effectively encapsulates the relationship between parts and their parent bodies. Our design is inherently versatile and capable of managing multiple parts-to-body associations without compromising on detection accuracy or robustness. Comprehensive experiments on various datasets underscore the efficacy of our approach, which not only outperforms existing state-of-the-art techniques but also offers a more streamlined and efficient solution to the part-body association challenge.
Implicit Modeling of Non-rigid Objects with Cross-Category Signals
Dec 15, 2023Deep implicit functions (DIFs) have emerged as a potent and articulate means of representing 3D shapes. However, methods modeling object categories or non-rigid entities have mainly focused on single-object scenarios. In this work, we propose MODIF, a multi-object deep implicit function that jointly learns the deformation fields and instance-specific latent codes for multiple objects at once. Our emphasis is on non-rigid, non-interpenetrating entities such as organs. To effectively capture the interrelation between these entities and ensure precise, collision-free representations, our approach facilitates signaling between category-specific fields to adequately rectify shapes. We also introduce novel inter-object supervision: an attraction-repulsion loss is formulated to refine contact regions between objects. Our approach is demonstrated on various medical benchmarks, involving modeling different groups of intricate anatomical entities. Experimental results illustrate that our model can proficiently learn the shape representation of each organ and their relations to others, to the point that shapes missing from unseen instances can be consistently recovered by our method. Finally, MODIF can also propagate semantic information throughout the population via accurate point correspondences
* Accepted at AAAI 2024. Paper + supplementary material