 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThomas Fang Zheng
Enhancing Quantised End-to-End ASR Models via Personalisation
Sep 17, 2023
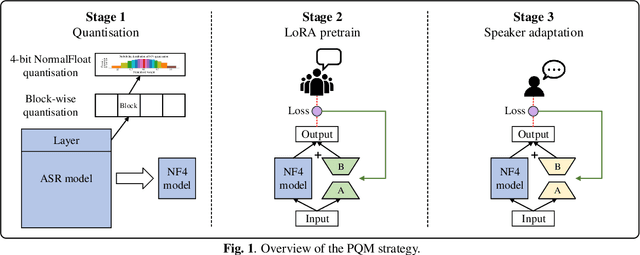
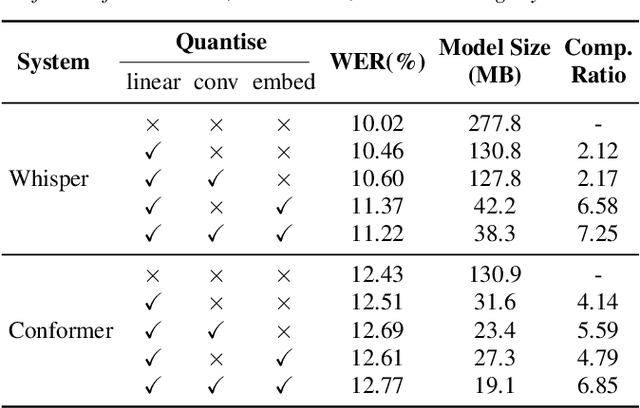
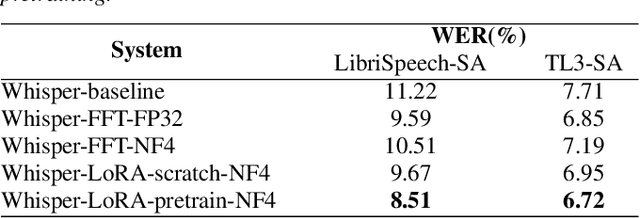
Recent end-to-end automatic speech recognition (ASR) models have become increasingly larger, making them particularly challenging to be deployed on resource-constrained devices. Model quantisation is an effective solution that sometimes causes the word error rate (WER) to increase. In this paper, a novel strategy of personalisation for a quantised model (PQM) is proposed, which combines speaker adaptive training (SAT) with model quantisation to improve the performance of heavily compressed models. Specifically, PQM uses a 4-bit NormalFloat Quantisation (NF4) approach for model quantisation and low-rank adaptation (LoRA) for SAT. Experiments have been performed on the LibriSpeech and the TED-LIUM 3 corpora. Remarkably, with a 7x reduction in model size and 1% additional speaker-specific parameters, 15.1% and 23.3% relative WER reductions were achieved on quantised Whisper and Conformer-based attention-based encoder-decoder ASR models respectively, comparing to the original full precision models.
How Speech is Recognized to Be Emotional - A Study Based on Information Decomposition
Nov 24, 2021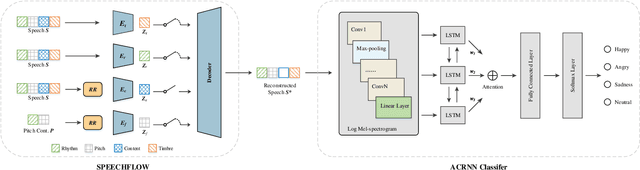
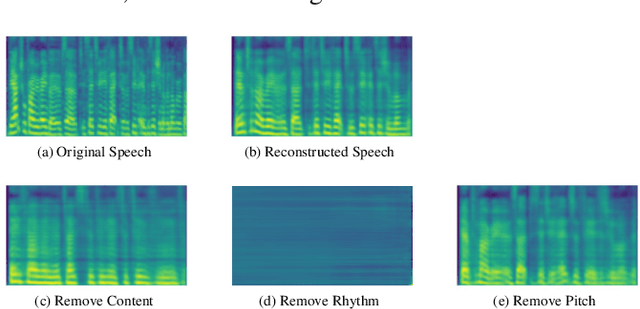
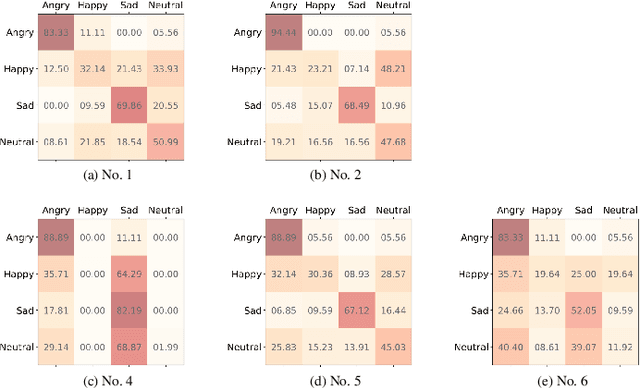
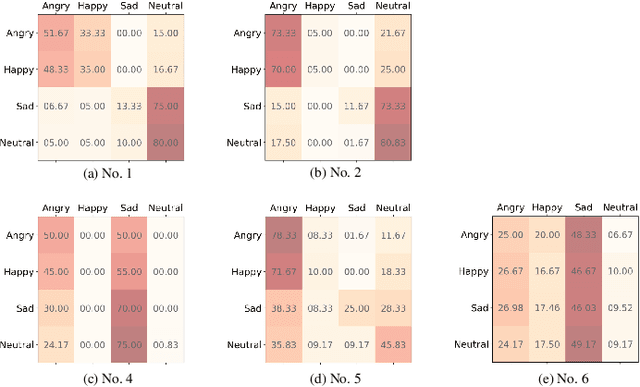
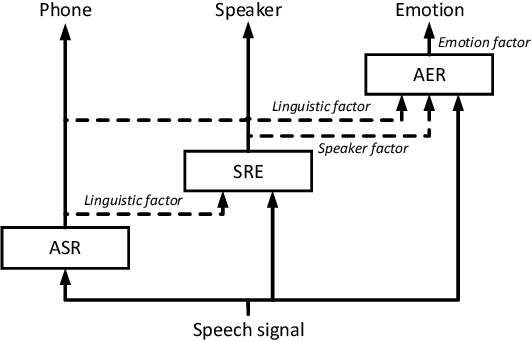
The way that humans encode their emotion into speech signals is complex. For instance, an angry man may increase his pitch and speaking rate, and use impolite words. In this paper, we present a preliminary study on various emotional factors and investigate how each of them impacts modern emotion recognition systems. The key tool of our study is the SpeechFlow model presented recently, by which we are able to decompose speech signals into separate information factors (content, pitch, rhythm). Based on this decomposition, we carefully studied the performance of each information component and their combinations. We conducted the study on three different speech emotion corpora and chose an attention-based convolutional RNN as the emotion classifier. Our results show that rhythm is the most important component for emotional expression. Moreover, the cross-corpus results are very bad (even worse than guess), demonstrating that the present speech emotion recognition model is rather weak. Interestingly, by removing one or several unimportant components, the cross-corpus results can be improved. This demonstrates the potential of the decomposition approach towards a generalizable emotion recognition.
A Multi-Resolution Front-End for End-to-End Speech Anti-Spoofing
Oct 11, 2021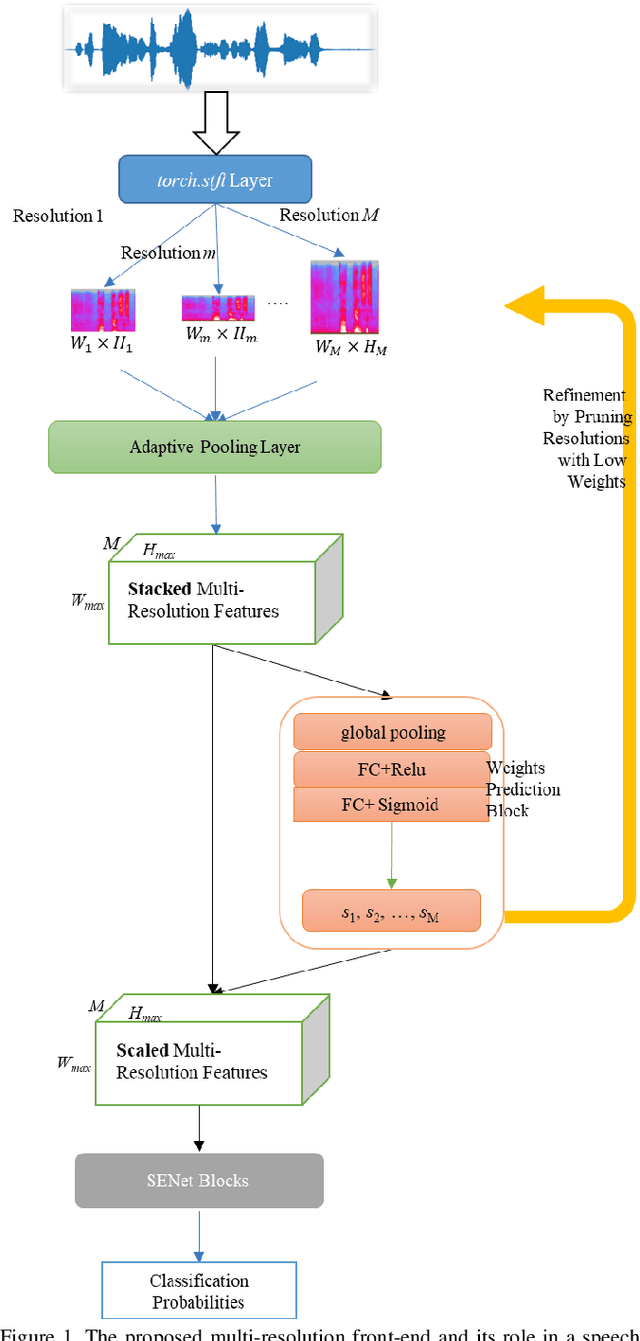
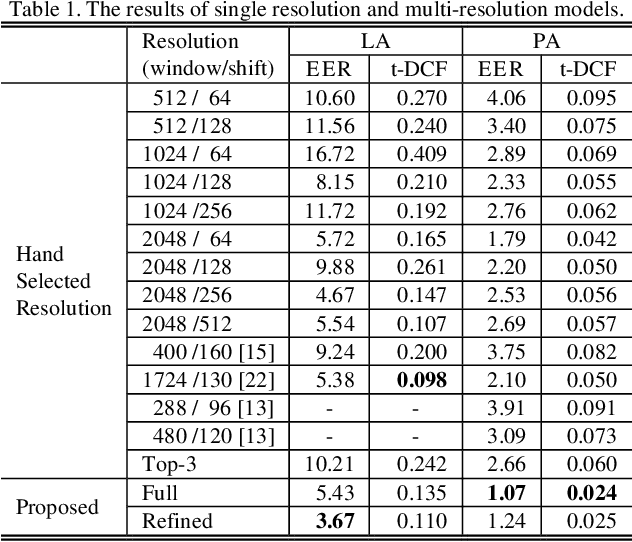
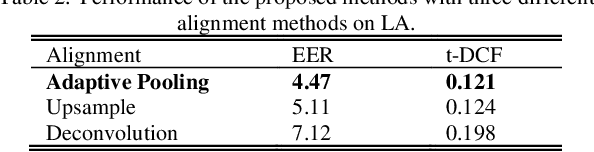
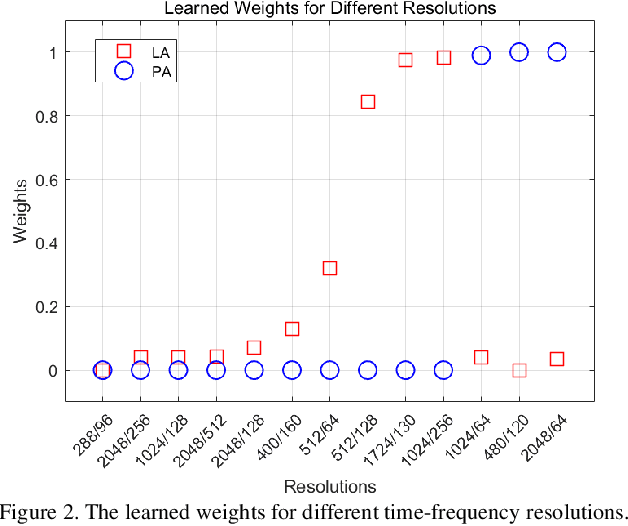
The choice of an optimal time-frequency resolution is usually a difficult but important step in tasks involving speech signal classification, e.g., speech anti-spoofing. The variations of the performance with different choices of timefrequency resolutions can be as large as those with different model architectures, which makes it difficult to judge what the improvement actually comes from when a new network architecture is invented and introduced as the classifier. In this paper, we propose a multi-resolution front-end for feature extraction in an end-to-end classification framework. Optimal weighted combinations of multiple time-frequency resolutions will be learned automatically given the objective of a classification task. Features extracted with different time-frequency resolutions are weighted and concatenated as inputs to the successive networks, where the weights are predicted by a learnable neural network inspired by the weighting block in squeeze-and-excitation networks (SENet). Furthermore, the refinement of the chosen timefrequency resolutions is investigated by pruning the ones with relatively low importance, which reduces the complexity and size of the model. The proposed method is evaluated on the tasks of speech anti-spoofing in ASVSpoof 2019 and its superiority has been justified by comparing with similar baselines.
Attack on practical speaker verification system using universal adversarial perturbations
May 19, 2021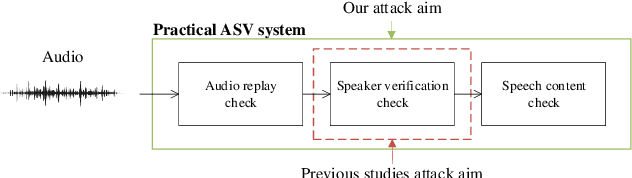
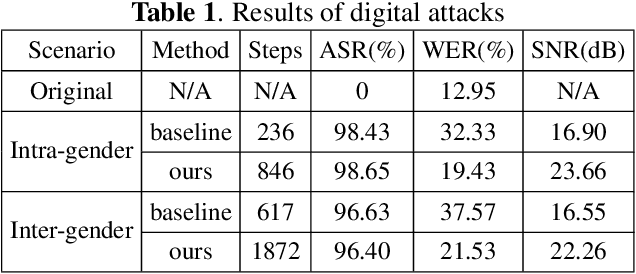
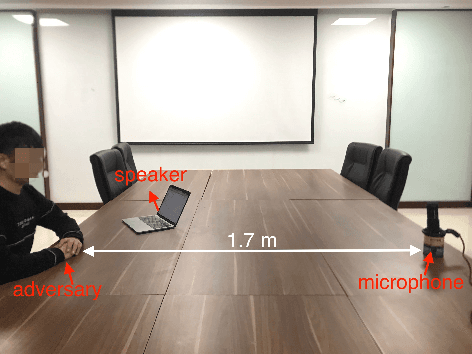
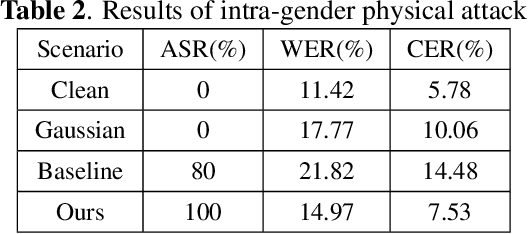
In authentication scenarios, applications of practical speaker verification systems usually require a person to read a dynamic authentication text. Previous studies played an audio adversarial example as a digital signal to perform physical attacks, which would be easily rejected by audio replay detection modules. This work shows that by playing our crafted adversarial perturbation as a separate source when the adversary is speaking, the practical speaker verification system will misjudge the adversary as a target speaker. A two-step algorithm is proposed to optimize the universal adversarial perturbation to be text-independent and has little effect on the authentication text recognition. We also estimated room impulse response (RIR) in the algorithm which allowed the perturbation to be effective after being played over the air. In the physical experiment, we achieved targeted attacks with success rate of 100%, while the word error rate (WER) on speech recognition was only increased by 3.55%. And recorded audios could pass replay detection for the live person speaking.
CN-Celeb: multi-genre speaker recognition
Dec 23, 2020
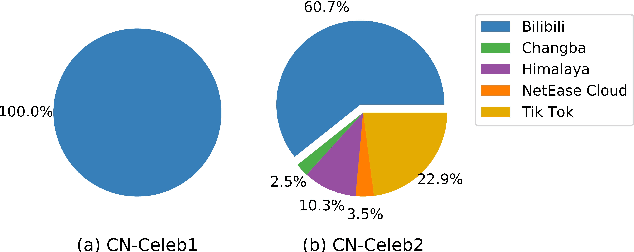
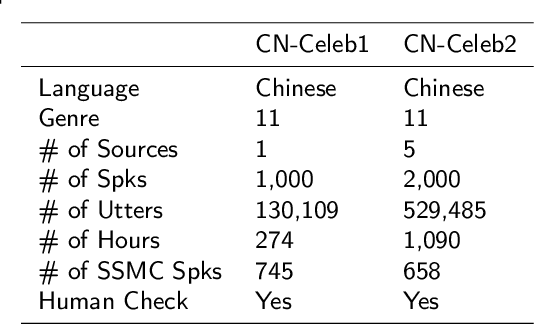
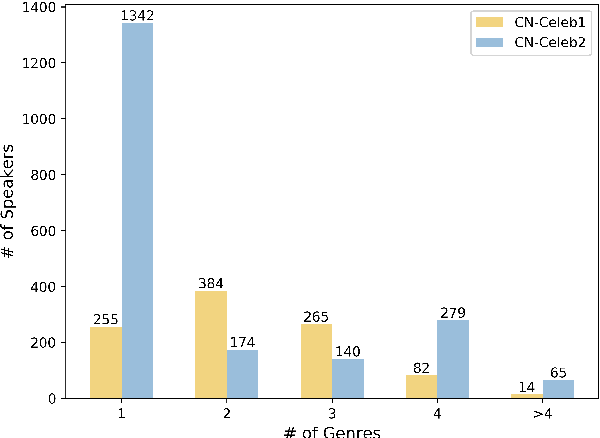
Research on speaker recognition is extending to address the vulnerability in the wild conditions, among which genre mismatch is perhaps the most challenging, for instance, enrollment with reading speech while testing with conversational or singing audio. This mismatch leads to complex and composite inter-session variations, both intrinsic (i.e., speaking style, physiological status) and extrinsic (i.e., recording device, background noise). Unfortunately, the few existing multi-genre corpora are not only limited in size but are also recorded under controlled conditions, which cannot support conclusive research on the multi-genre problem. In this work, we firstly publish CN-Celeb, a large-scale multi-genre corpus that includes in-the-wild speech utterances of 3,000 speakers in 11 different genres. Secondly, using this dataset, we conduct a comprehensive study on the multi-genre phenomenon, in particular the impact of the multi-genre challenge on speaker recognition, and on how to utilize the valuable multi-genre data more efficiently.
Squeezing value of cross-domain labels: a decoupled scoring approach for speaker verification
Oct 27, 2020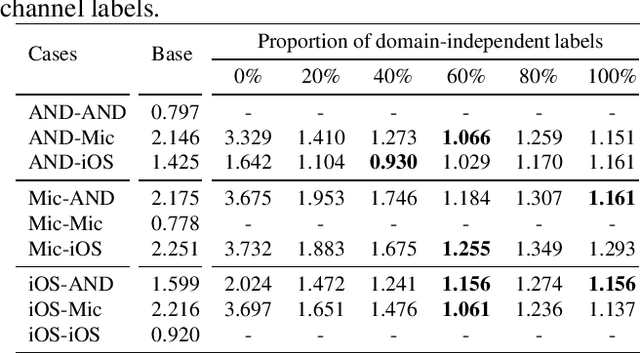
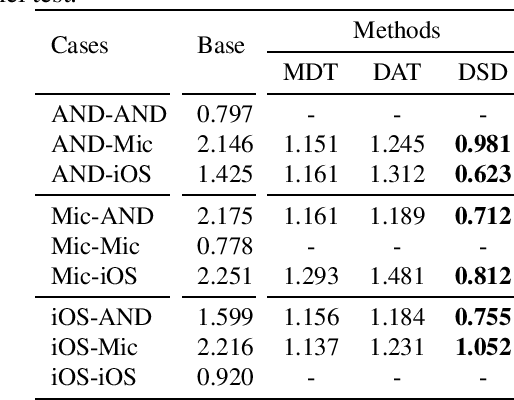
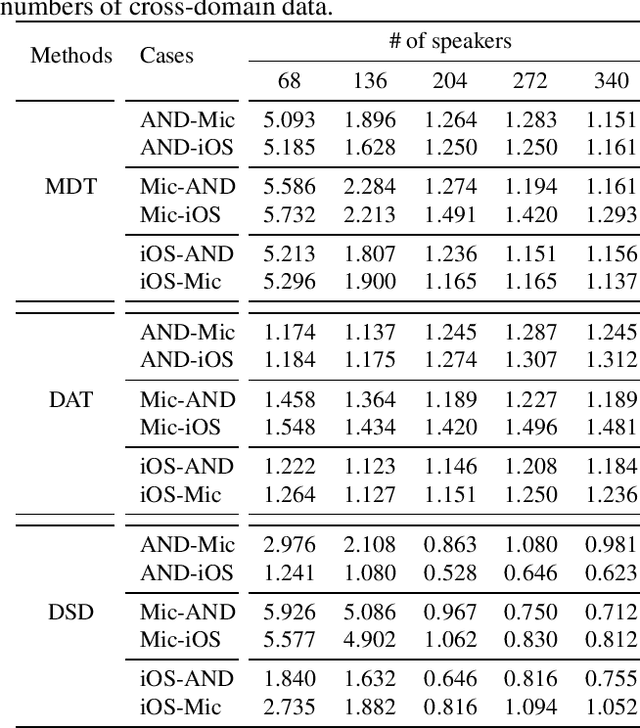
Domain mismatch often occurs in real applications and causes serious performance reduction on speaker verification systems. The common wisdom is to collect cross-domain data and train a multi-domain PLDA model, with the hope to learn a domain-independent speaker subspace. In this paper, we firstly present an empirical study to show that simply adding cross-domain data does not help performance in conditions with enrollment-test mismatch. Careful analysis shows that this striking result is caused by the incoherent statistics between the enrollment and test conditions. Based on this analysis, we present a decoupled scoring approach that can maximally squeeze the value of cross-domain labels and obtain optimal verification scores when the enrollment and test are mismatched. When the statistics are coherent, the new formulation falls back to the conventional PLDA. Experimental results on cross-channel test show that the proposed approach is highly effective and is a principle solution to domain mismatch.
Deep generative factorization for speech signal
Oct 27, 2020
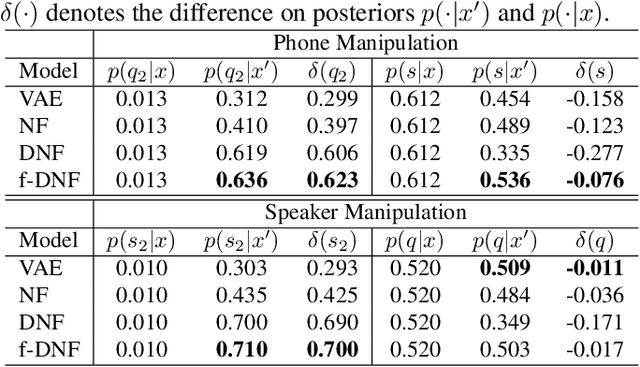
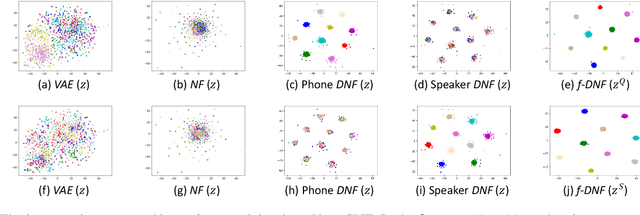
Various information factors are blended in speech signals, which forms the primary difficulty for most speech information processing tasks. An intuitive idea is to factorize speech signal into individual information factors (e.g., phonetic content and speaker trait), though it turns out to be highly challenging. This paper presents a speech factorization approach based on a novel factorial discriminative normalization flow model (factorial DNF). Experiments conducted on a two-factor case that involves phonetic content and speaker trait demonstrates that the proposed factorial DNF has powerful capability to factorize speech signals and outperforms several comparative models in terms of information representation and manipulation.
Deep factorization for speech signal
Feb 27, 2018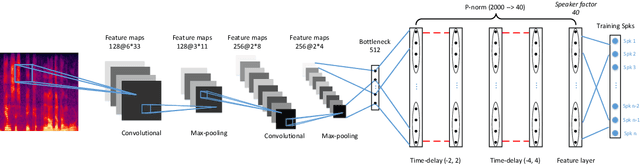
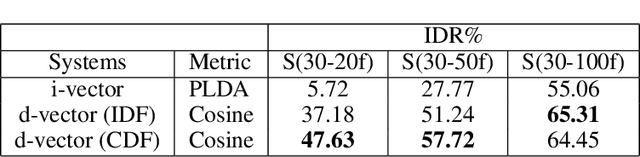
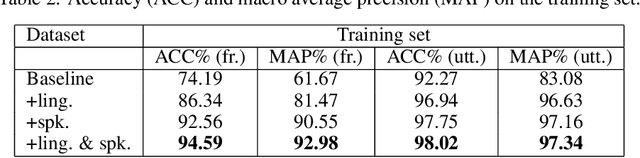
Various informative factors mixed in speech signals, leading to great difficulty when decoding any of the factors. An intuitive idea is to factorize each speech frame into individual informative factors, though it turns out to be highly difficult. Recently, we found that speaker traits, which were assumed to be long-term distributional properties, are actually short-time patterns, and can be learned by a carefully designed deep neural network (DNN). This discovery motivated a cascade deep factorization (CDF) framework that will be presented in this paper. The proposed framework infers speech factors in a sequential way, where factors previously inferred are used as conditional variables when inferring other factors. We will show that this approach can effectively factorize speech signals, and using these factors, the original speech spectrum can be recovered with a high accuracy. This factorization and reconstruction approach provides potential values for many speech processing tasks, e.g., speaker recognition and emotion recognition, as will be demonstrated in the paper.
Full-info Training for Deep Speaker Feature Learning
Feb 27, 2018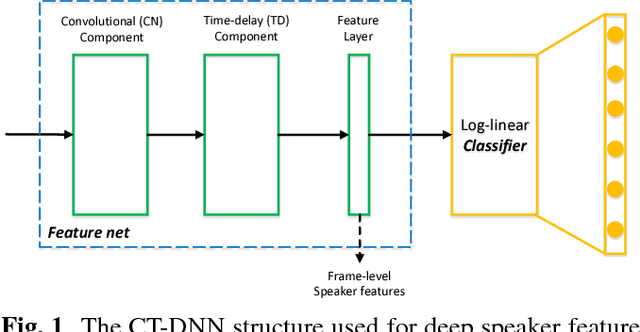
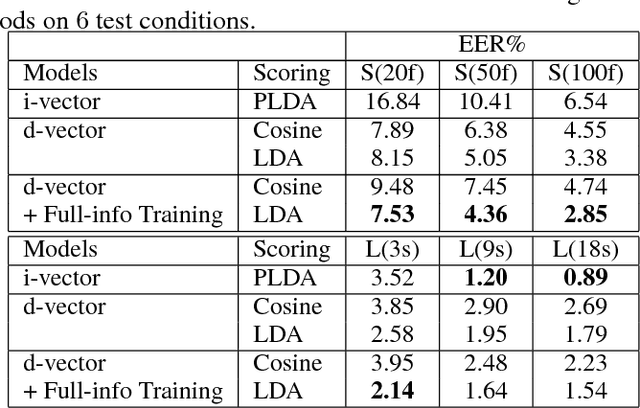
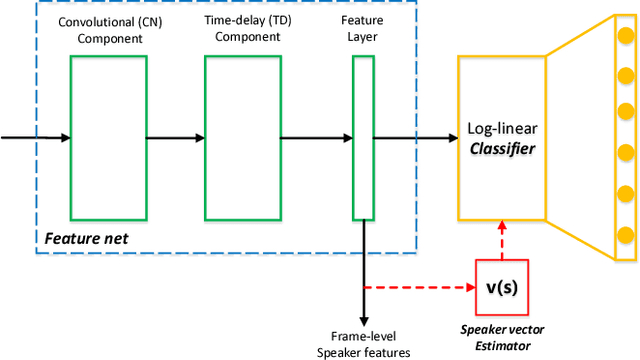
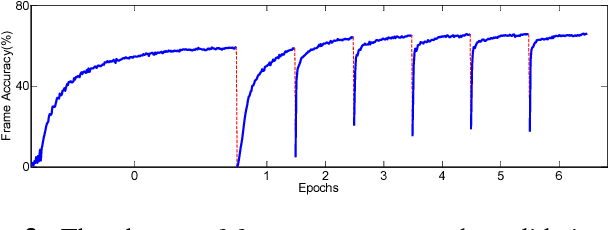
In recent studies, it has shown that speaker patterns can be learned from very short speech segments (e.g., 0.3 seconds) by a carefully designed convolutional & time-delay deep neural network (CT-DNN) model. By enforcing the model to discriminate the speakers in the training data, frame-level speaker features can be derived from the last hidden layer. In spite of its good performance, a potential problem of the present model is that it involves a parametric classifier, i.e., the last affine layer, which may consume some discriminative knowledge, thus leading to `information leak' for the feature learning. This paper presents a full-info training approach that discards the parametric classifier and enforces all the discriminative knowledge learned by the feature net. Our experiments on the Fisher database demonstrate that this new training scheme can produce more coherent features, leading to consistent and notable performance improvement on the speaker verification task.
Enhanced Neural Machine Translation by Learning from Draft
Oct 04, 2017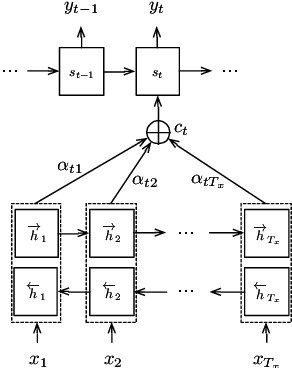
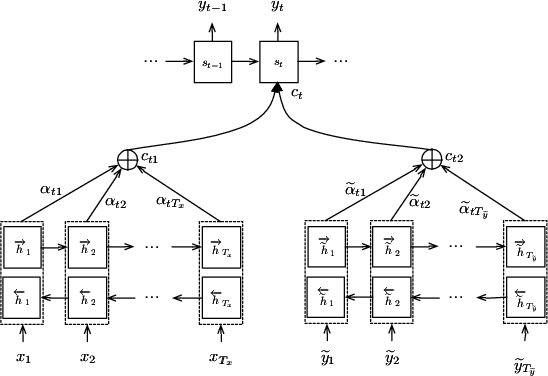
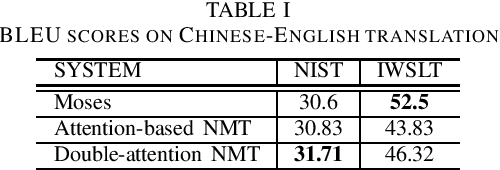
Neural machine translation (NMT) has recently achieved impressive results. A potential problem of the existing NMT algorithm, however, is that the decoding is conducted from left to right, without considering the right context. This paper proposes an two-stage approach to solve the problem. In the first stage, a conventional attention-based NMT system is used to produce a draft translation, and in the second stage, a novel double-attention NMT system is used to refine the translation, by looking at the original input as well as the draft translation. This drafting-and-refinement can obtain the right-context information from the draft, hence producing more consistent translations. We evaluated this approach using two Chinese-English translation tasks, one with 44k pairs and 1M pairs respectively. The experiments showed that our approach achieved positive improvements over the conventional NMT system: the improvements are 2.4 and 0.9 BLEU points on the small-scale and large-scale tasks, respectively.