 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTian Liu
Learning using granularity statistical invariants for classification
Mar 29, 2024

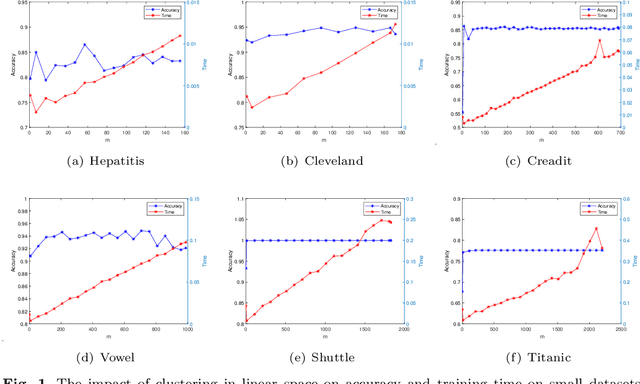
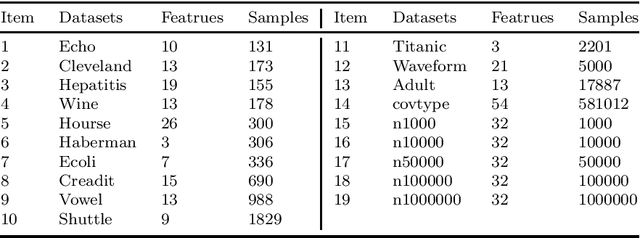
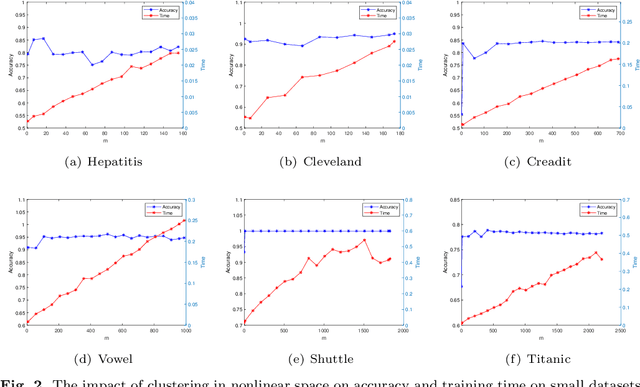
Learning using statistical invariants (LUSI) is a new learning paradigm, which adopts weak convergence mechanism, and can be applied to a wider range of classification problems. However, the computation cost of invariant matrices in LUSI is high for large-scale datasets during training. To settle this issue, this paper introduces a granularity statistical invariant for LUSI, and develops a new learning paradigm called learning using granularity statistical invariants (LUGSI). LUGSI employs both strong and weak convergence mechanisms, taking a perspective of minimizing expected risk. As far as we know, it is the first time to construct granularity statistical invariants. Compared to LUSI, the introduction of this new statistical invariant brings two advantages. Firstly, it enhances the structural information of the data. Secondly, LUGSI transforms a large invariant matrix into a smaller one by maximizing the distance between classes, achieving feasibility for large-scale datasets classification problems and significantly enhancing the training speed of model operations. Experimental results indicate that LUGSI not only exhibits improved generalization capabilities but also demonstrates faster training speed, particularly for large-scale datasets.
The Neglected Tails of Vision-Language Models
Feb 02, 2024Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
Technical Report: On the Convergence of Gossip Learning in the Presence of Node Inaccessibility
Jan 17, 2024Gossip learning (GL), as a decentralized alternative to federated learning (FL), is more suitable for resource-constrained wireless networks, such as FANETs that are formed by unmanned aerial vehicles (UAVs). GL can significantly enhance the efficiency and extend the battery life of UAV networks. Despite the advantages, the performance of GL is strongly affected by data distribution, communication speed, and network connectivity. However, how these factors influence the GL convergence is still unclear. Existing work studied the convergence of GL based on a virtual quantity for the sake of convenience, which fail to reflect the real state of the network when some nodes are inaccessible. In this paper, we formulate and investigate the impact of inaccessible nodes to GL under a dynamic network topology. We first decompose the weight divergence by whether the node is accessible or not. Then, we investigate the GL convergence under the dynamic of node accessibility and theoretically provide how the number of inaccessible nodes, data non-i.i.d.-ness, and duration of inaccessibility affect the convergence. Extensive experiments are carried out in practical settings to comprehensively verify the correctness of our theoretical findings.
Cross-Shaped Windows Transformer with Self-supervised Pretraining for Clinically Significant Prostate Cancer Detection in Bi-parametric MRI
Apr 30, 2023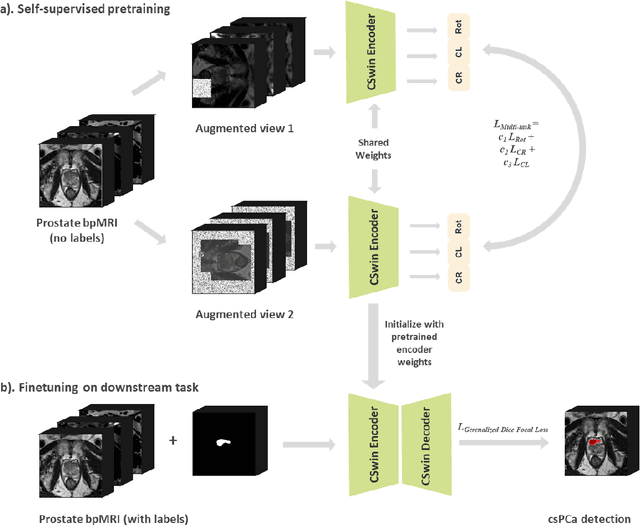
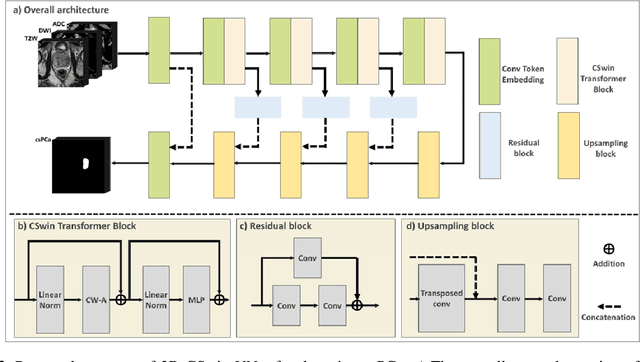

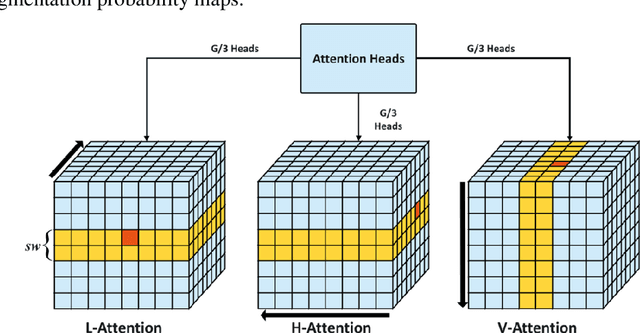
Multiparametric magnetic resonance imaging (mpMRI) has demonstrated promising results in prostate cancer (PCa) detection using deep convolutional neural networks (CNNs). Recently, transformers have achieved competitive performance compared to CNNs in computer vision. Large-scale transformers need abundant annotated data for training, which are difficult to obtain in medical imaging. Self-supervised learning can effectively leverage unlabeled data to extract useful semantic representations without annotation and its associated costs. This can improve model performance on downstream tasks with limited labelled data and increase generalizability. We introduce a novel end-to-end Cross-Shaped windows (CSwin) transformer UNet model, CSwin UNet, to detect clinically significant prostate cancer (csPCa) in prostate bi-parametric MR imaging (bpMRI) and demonstrate the effectiveness of our proposed self-supervised pre-training framework. Using a large prostate bpMRI dataset with 1500 patients, we first pre-train CSwin transformer using multi-task self-supervised learning to improve data-efficiency and network generalizability. We then finetuned using lesion annotations to perform csPCa detection. Five-fold cross validation shows that self-supervised CSwin UNet achieves 0.888 AUC and 0.545 Average Precision (AP), significantly outperforming four state-of-the-art models (Swin UNETR, DynUNet, Attention UNet, UNet). Using a separate bpMRI dataset with 158 patients, we evaluated our model robustness to external hold-out data. Self-supervised CSwin UNet achieves 0.79 AUC and 0.45 AP, still outperforming all other comparable methods and demonstrating generalization to a dataset shift.
Cycle-guided Denoising Diffusion Probability Model for 3D Cross-modality MRI Synthesis
Apr 28, 2023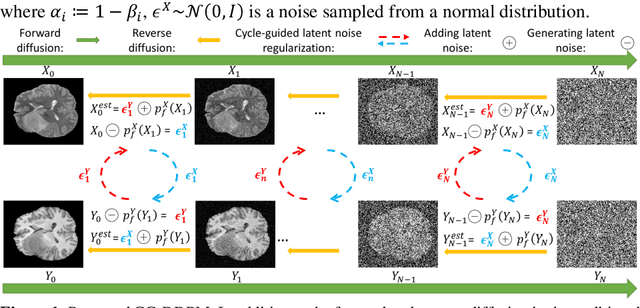
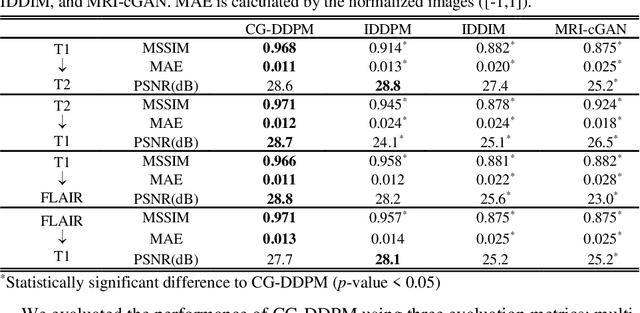
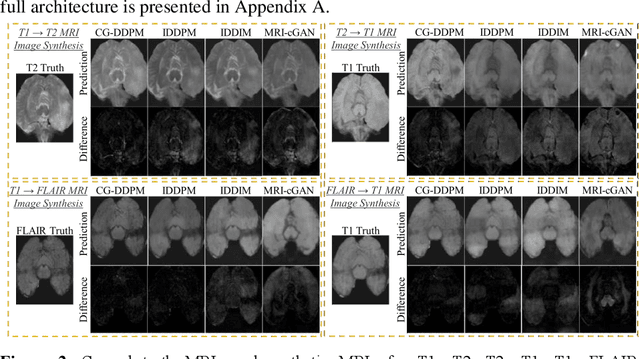
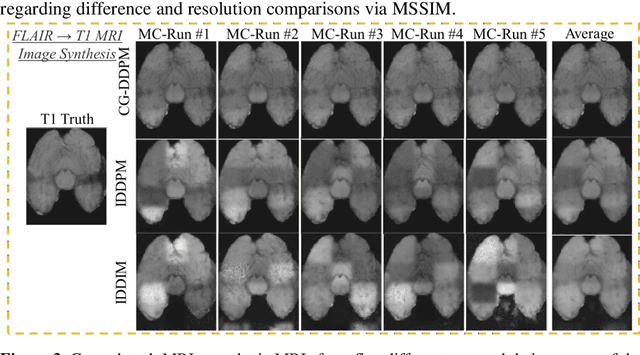
This study aims to develop a novel Cycle-guided Denoising Diffusion Probability Model (CG-DDPM) for cross-modality MRI synthesis. The CG-DDPM deploys two DDPMs that condition each other to generate synthetic images from two different MRI pulse sequences. The two DDPMs exchange random latent noise in the reverse processes, which helps to regularize both DDPMs and generate matching images in two modalities. This improves image-to-image translation ac-curacy. We evaluated the CG-DDPM quantitatively using mean absolute error (MAE), multi-scale structural similarity index measure (MSSIM), and peak sig-nal-to-noise ratio (PSNR), as well as the network synthesis consistency, on the BraTS2020 dataset. Our proposed method showed high accuracy and reliable consistency for MRI synthesis. In addition, we compared the CG-DDPM with several other state-of-the-art networks and demonstrated statistically significant improvements in the image quality of synthetic MRIs. The proposed method enhances the capability of current multimodal MRI synthesis approaches, which could contribute to more accurate diagnosis and better treatment planning for patients by synthesizing additional MRI modalities.
Deep Learning-based Multi-Organ CT Segmentation with Adversarial Data Augmentation
Feb 25, 2023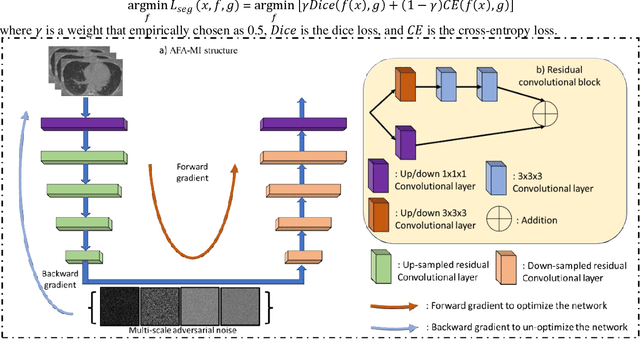
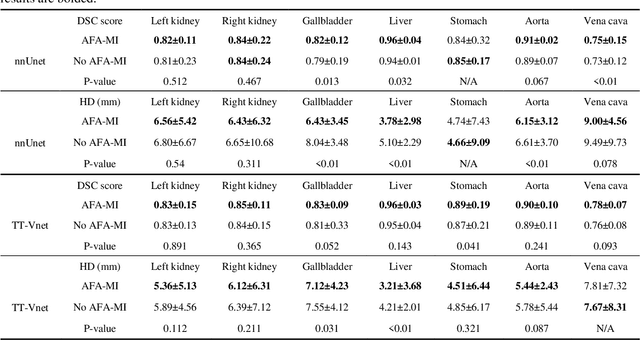
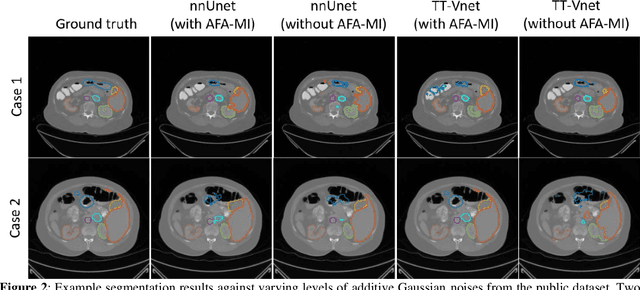
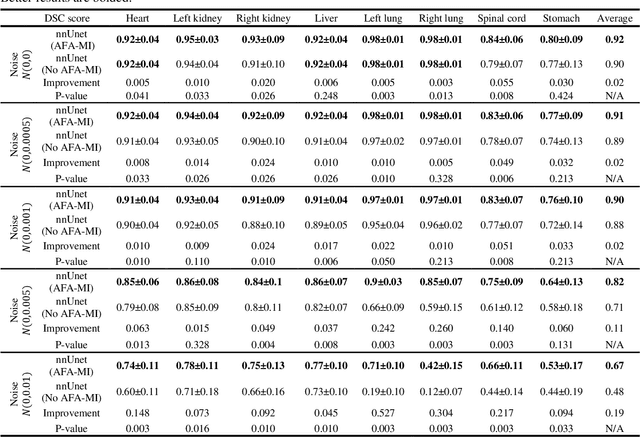
In this work, we propose an adversarial attack-based data augmentation method to improve the deep-learning-based segmentation algorithm for the delineation of Organs-At-Risk (OAR) in abdominal Computed Tomography (CT) to facilitate radiation therapy. We introduce Adversarial Feature Attack for Medical Image (AFA-MI) augmentation, which forces the segmentation network to learn out-of-distribution statistics and improve generalization and robustness to noises. AFA-MI augmentation consists of three steps: 1) generate adversarial noises by Fast Gradient Sign Method (FGSM) on the intermediate features of the segmentation network's encoder; 2) inject the generated adversarial noises into the network, intentionally compromising performance; 3) optimize the network with both clean and adversarial features. Experiments are conducted segmenting the heart, left and right kidney, liver, left and right lung, spinal cord, and stomach. We first evaluate the AFA-MI augmentation using nnUnet and TT-Vnet on the test data from a public abdominal dataset and an institutional dataset. In addition, we validate how AFA-MI affects the networks' robustness to the noisy data by evaluating the networks with added Gaussian noises of varying magnitudes to the institutional dataset. Network performance is quantitatively evaluated using Dice Similarity Coefficient (DSC) for volume-based accuracy. Also, Hausdorff Distance (HD) is applied for surface-based accuracy. On the public dataset, nnUnet with AFA-MI achieves DSC = 0.85 and HD = 6.16 millimeters (mm); and TT-Vnet achieves DSC = 0.86 and HD = 5.62 mm. AFA-MI augmentation further improves all contour accuracies up to 0.217 DSC score when tested on images with Gaussian noises. AFA-MI augmentation is therefore demonstrated to improve segmentation performance and robustness in CT multi-organ segmentation.
Landmark Tracking in Liver US images Using Cascade Convolutional Neural Networks with Long Short-Term Memory
Sep 14, 2022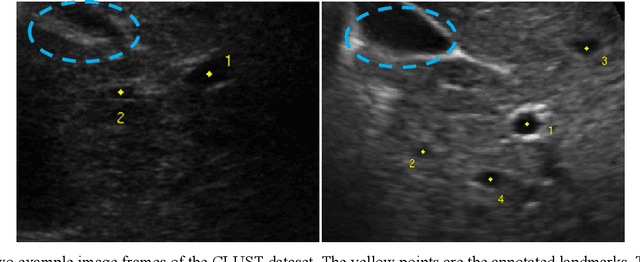
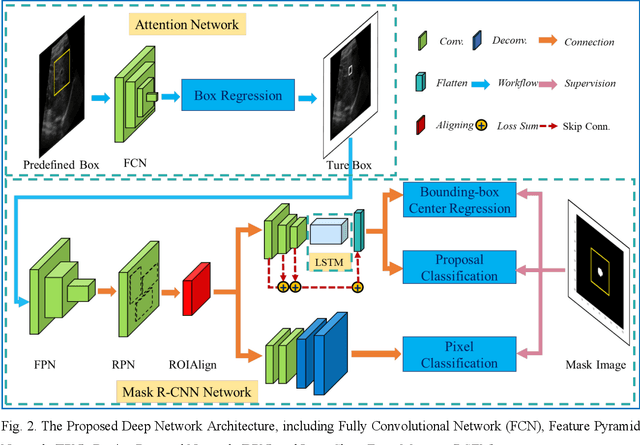
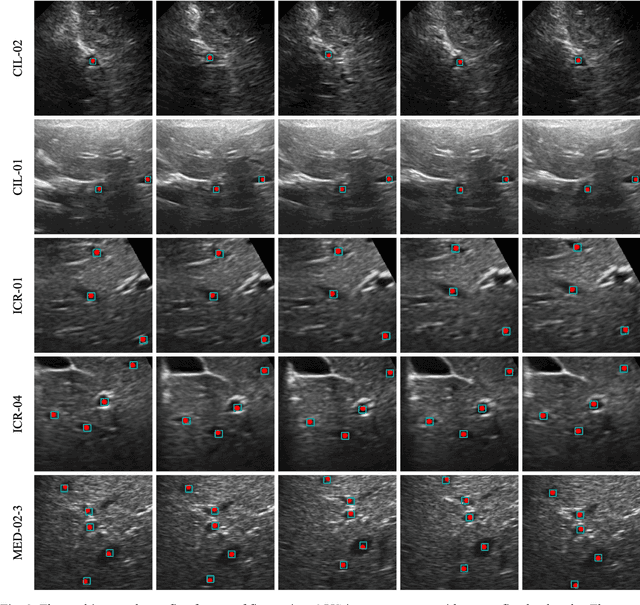
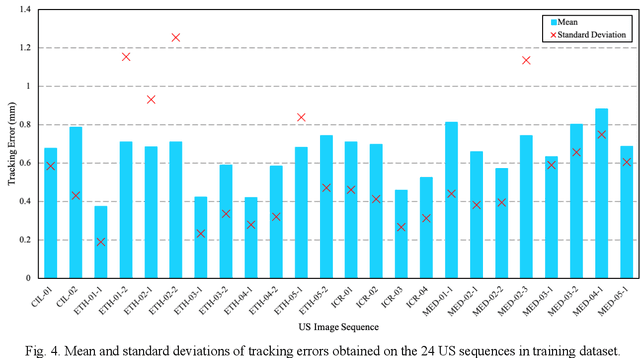
This study proposed a deep learning-based tracking method for ultrasound (US) image-guided radiation therapy. The proposed cascade deep learning model is composed of an attention network, a mask region-based convolutional neural network (mask R-CNN), and a long short-term memory (LSTM) network. The attention network learns a mapping from a US image to a suspected area of landmark motion in order to reduce the search region. The mask R-CNN then produces multiple region-of-interest (ROI) proposals in the reduced region and identifies the proposed landmark via three network heads: bounding box regression, proposal classification, and landmark segmentation. The LSTM network models the temporal relationship among the successive image frames for bounding box regression and proposal classification. To consolidate the final proposal, a selection method is designed according to the similarities between sequential frames. The proposed method was tested on the liver US tracking datasets used in the Medical Image Computing and Computer Assisted Interventions (MICCAI) 2015 challenges, where the landmarks were annotated by three experienced observers to obtain their mean positions. Five-fold cross-validation on the 24 given US sequences with ground truths shows that the mean tracking error for all landmarks is 0.65+/-0.56 mm, and the errors of all landmarks are within 2 mm. We further tested the proposed model on 69 landmarks from the testing dataset that has a similar image pattern to the training pattern, resulting in a mean tracking error of 0.94+/-0.83 mm. Our experimental results have demonstrated the feasibility and accuracy of our proposed method in tracking liver anatomic landmarks using US images, providing a potential solution for real-time liver tracking for active motion management during radiation therapy.
Deformable Image Registration using Unsupervised Deep Learning for CBCT-guided Abdominal Radiotherapy
Aug 29, 2022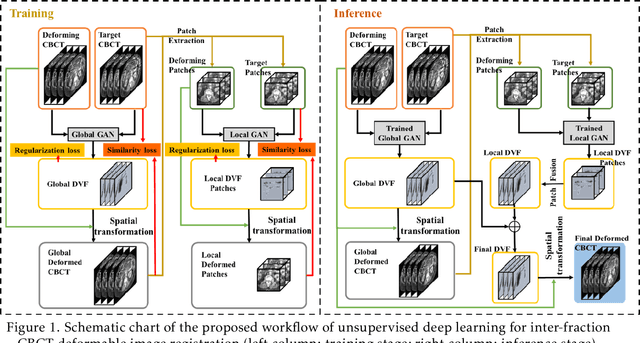
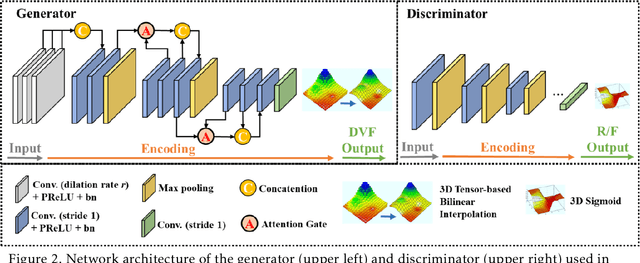
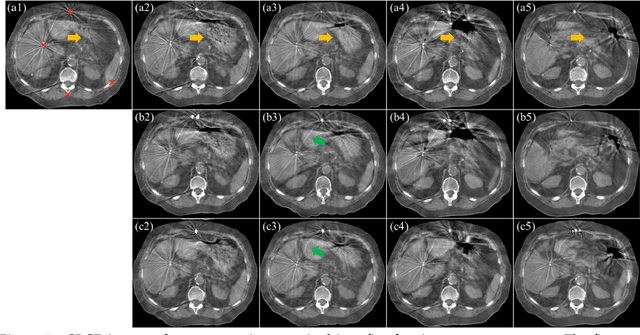
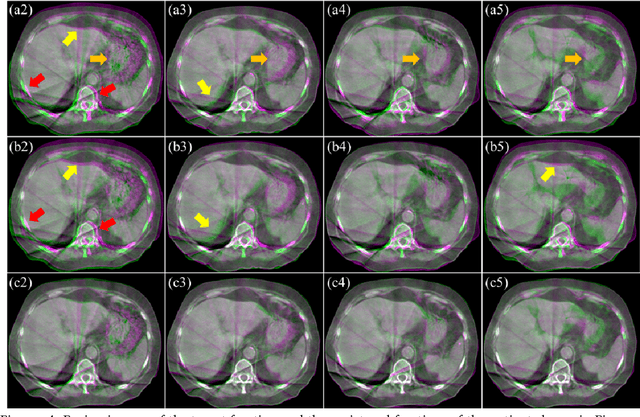
CBCTs in image-guided radiotherapy provide crucial anatomy information for patient setup and plan evaluation. Longitudinal CBCT image registration could quantify the inter-fractional anatomic changes. The purpose of this study is to propose an unsupervised deep learning based CBCT-CBCT deformable image registration. The proposed deformable registration workflow consists of training and inference stages that share the same feed-forward path through a spatial transformation-based network (STN). The STN consists of a global generative adversarial network (GlobalGAN) and a local GAN (LocalGAN) to predict the coarse- and fine-scale motions, respectively. The network was trained by minimizing the image similarity loss and the deformable vector field (DVF) regularization loss without the supervision of ground truth DVFs. During the inference stage, patches of local DVF were predicted by the trained LocalGAN and fused to form a whole-image DVF. The local whole-image DVF was subsequently combined with the GlobalGAN generated DVF to obtain final DVF. The proposed method was evaluated using 100 fractional CBCTs from 20 abdominal cancer patients in the experiments and 105 fractional CBCTs from a cohort of 21 different abdominal cancer patients in a holdout test. Qualitatively, the registration results show great alignment between the deformed CBCT images and the target CBCT image. Quantitatively, the average target registration error (TRE) calculated on the fiducial markers and manually identified landmarks was 1.91+-1.11 mm. The average mean absolute error (MAE), normalized cross correlation (NCC) between the deformed CBCT and target CBCT were 33.42+-7.48 HU, 0.94+-0.04, respectively. This promising registration method could provide fast and accurate longitudinal CBCT alignment to facilitate inter-fractional anatomic changes analysis and prediction.
Technical Report: Assisting Backdoor Federated Learning with Whole Population Knowledge Alignment
Jul 25, 2022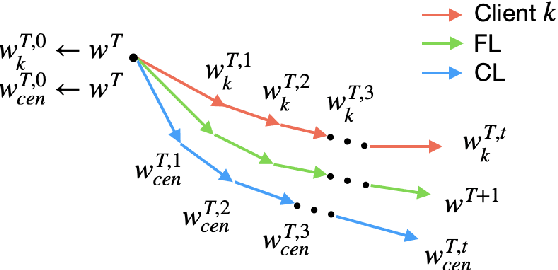

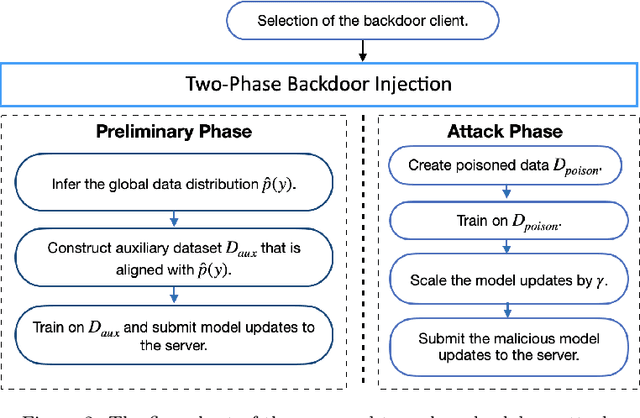
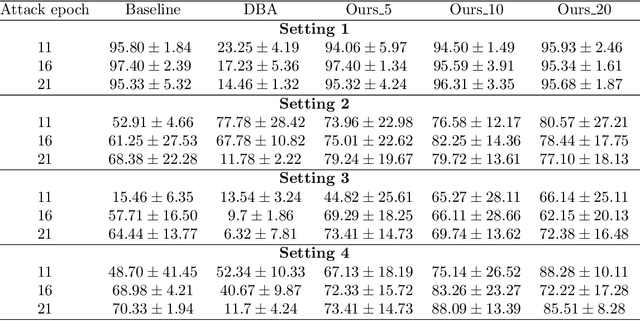
Due to the distributed nature of Federated Learning (FL), researchers have uncovered that FL is vulnerable to backdoor attacks, which aim at injecting a sub-task into the FL without corrupting the performance of the main task. Single-shot backdoor attack achieves high accuracy on both the main task and backdoor sub-task when injected at the FL model convergence. However, the early-injected single-shot backdoor attack is ineffective because: (1) the maximum backdoor effectiveness is not reached at injection because of the dilution effect from normal local updates; (2) the backdoor effect decreases quickly as the backdoor will be overwritten by the newcoming normal local updates. In this paper, we strengthen the early-injected single-shot backdoor attack utilizing FL model information leakage. We show that the FL convergence can be expedited if the client trains on a dataset that mimics the distribution and gradients of the whole population. Based on this observation, we proposed a two-phase backdoor attack, which includes a preliminary phase for the subsequent backdoor attack. In the preliminary phase, the attacker-controlled client first launches a whole population distribution inference attack and then trains on a locally crafted dataset that is aligned with both the gradient and inferred distribution. Benefiting from the preliminary phase, the later injected backdoor achieves better effectiveness as the backdoor effect will be less likely to be diluted by the normal model updates. Extensive experiments are conducted on MNIST dataset under various data heterogeneity settings to evaluate the effectiveness of the proposed backdoor attack. Results show that the proposed backdoor outperforms existing backdoor attacks in both success rate and longevity, even when defense mechanisms are in place.