 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianhao Zhang
BBScore: A Brownian Bridge Based Metric for Assessing Text Coherence
Dec 28, 2023
Measuring the coherence of text is a vital aspect of evaluating the quality of written content. Recent advancements in neural coherence modeling have demonstrated their efficacy in capturing entity coreference and discourse relations, thereby enhancing coherence evaluation. However, many existing methods heavily depend on static embeddings or focus narrowly on nearby context, constraining their capacity to measure the overarching coherence of long texts. In this paper, we posit that coherent texts inherently manifest a sequential and cohesive interplay among sentences, effectively conveying the central theme, purpose, or standpoint. To explore this abstract relationship, we introduce the "BBScore," a novel reference-free metric grounded in Brownian bridge theory for assessing text coherence. Our findings showcase that when synergized with a simple additional classification component, this metric attains a performance level comparable to state-of-the-art techniques on standard artificial discrimination tasks. We also establish in downstream tasks that this metric effectively differentiates between human-written documents and text generated by large language models under a specific domain. Furthermore, we illustrate the efficacy of this approach in detecting written styles attributed to diverse large language models, underscoring its potential for generalizability. In summary, we present a novel Brownian bridge coherence metric capable of measuring both local and global text coherence, while circumventing the need for end-to-end model training. This flexibility allows for its application in various downstream tasks.
Out-of-distribution Object Detection through Bayesian Uncertainty Estimation
Oct 29, 2023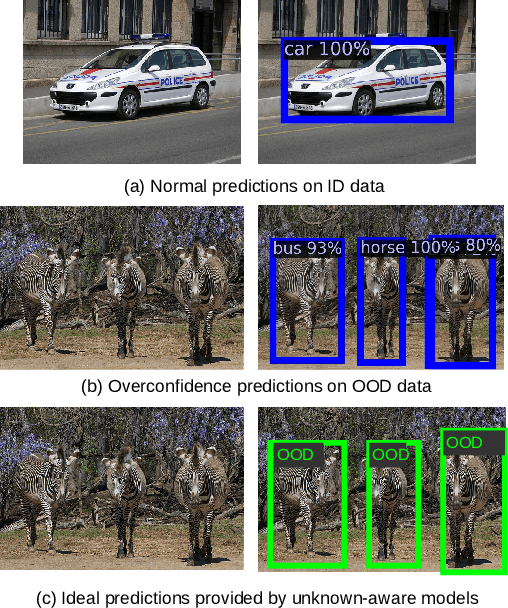
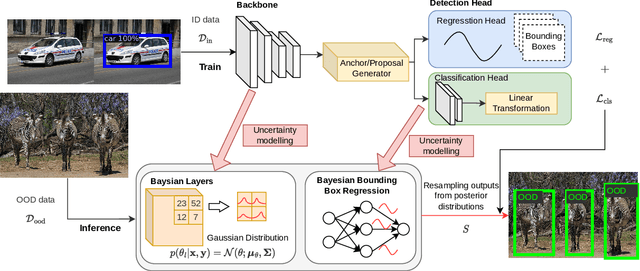

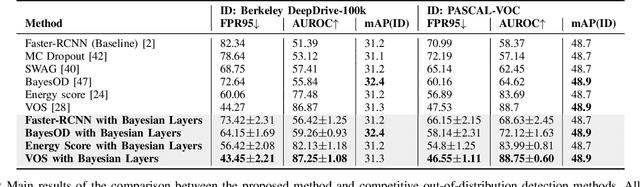
The superior performance of object detectors is often established under the condition that the test samples are in the same distribution as the training data. However, in many practical applications, out-of-distribution (OOD) instances are inevitable and usually lead to uncertainty in the results. In this paper, we propose a novel, intuitive, and scalable probabilistic object detection method for OOD detection. Unlike other uncertainty-modeling methods that either require huge computational costs to infer the weight distributions or rely on model training through synthetic outlier data, our method is able to distinguish between in-distribution (ID) data and OOD data via weight parameter sampling from proposed Gaussian distributions based on pre-trained networks. We demonstrate that our Bayesian object detector can achieve satisfactory OOD identification performance by reducing the FPR95 score by up to 8.19% and increasing the AUROC score by up to 13.94% when trained on BDD100k and VOC datasets as the ID datasets and evaluated on COCO2017 dataset as the OOD dataset.
MRET: Multi-resolution Transformer for Video Quality Assessment
Mar 29, 2023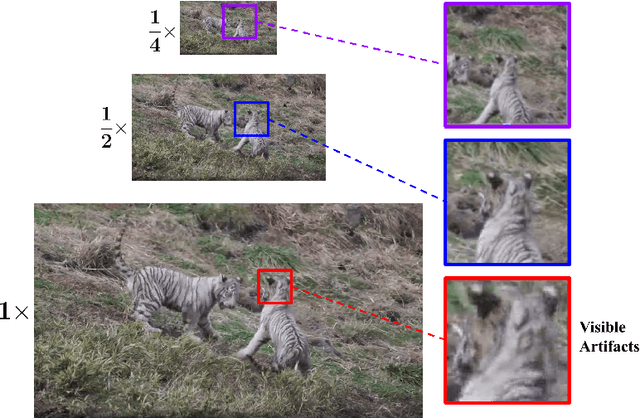
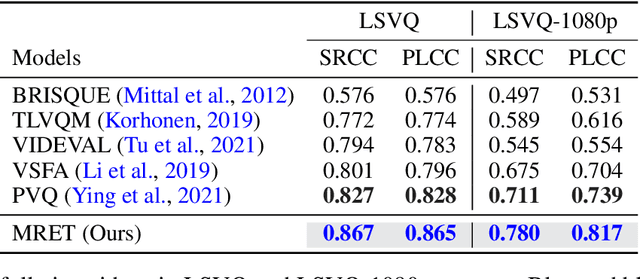
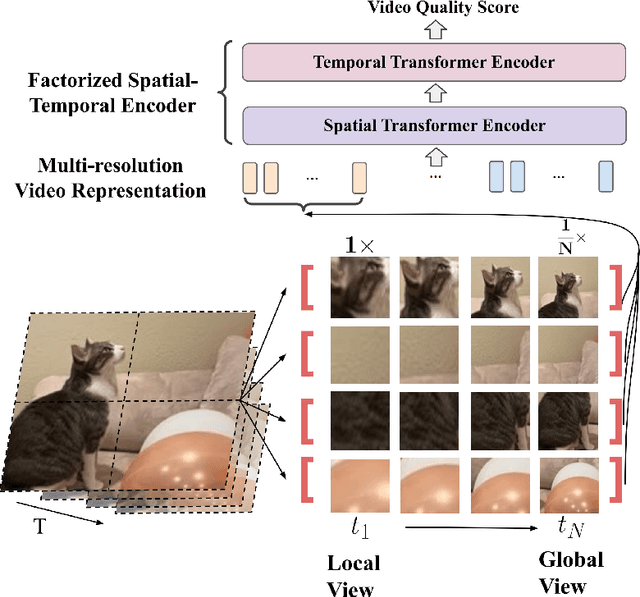
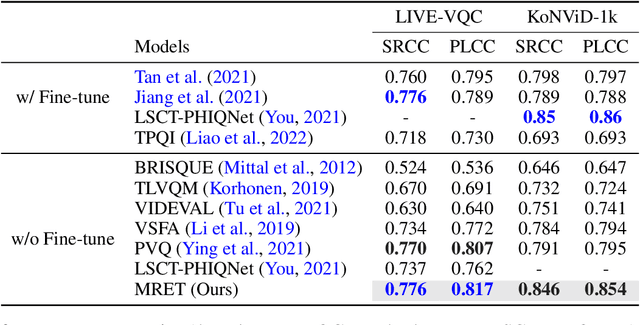
No-reference video quality assessment (NR-VQA) for user generated content (UGC) is crucial for understanding and improving visual experience. Unlike video recognition tasks, VQA tasks are sensitive to changes in input resolution. Since large amounts of UGC videos nowadays are 720p or above, the fixed and relatively small input used in conventional NR-VQA methods results in missing high-frequency details for many videos. In this paper, we propose a novel Transformer-based NR-VQA framework that preserves the high-resolution quality information. With the multi-resolution input representation and a novel multi-resolution patch sampling mechanism, our method enables a comprehensive view of both the global video composition and local high-resolution details. The proposed approach can effectively aggregate quality information across different granularities in spatial and temporal dimensions, making the model robust to input resolution variations. Our method achieves state-of-the-art performance on large-scale UGC VQA datasets LSVQ and LSVQ-1080p, and on KoNViD-1k and LIVE-VQC without fine-tuning.
MACC: Cross-Layer Multi-Agent Congestion Control with Deep Reinforcement Learning
Jun 04, 2022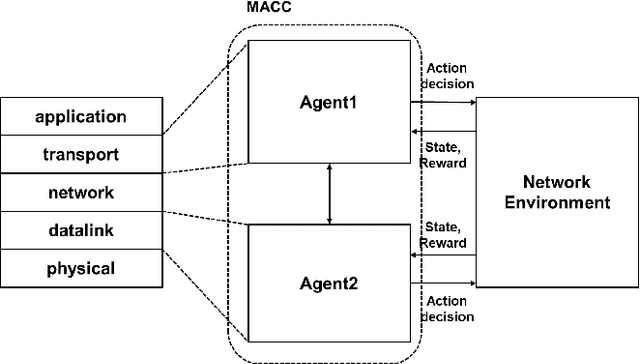
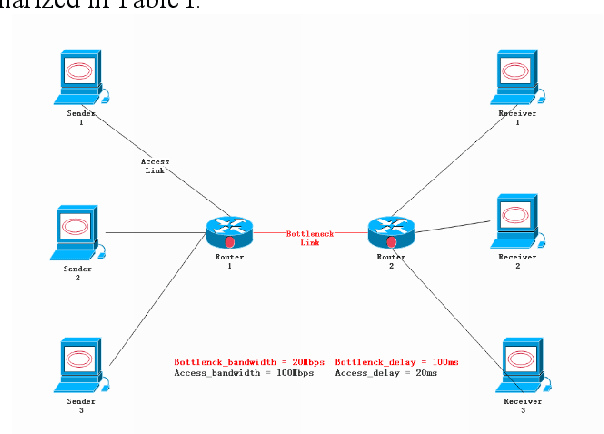
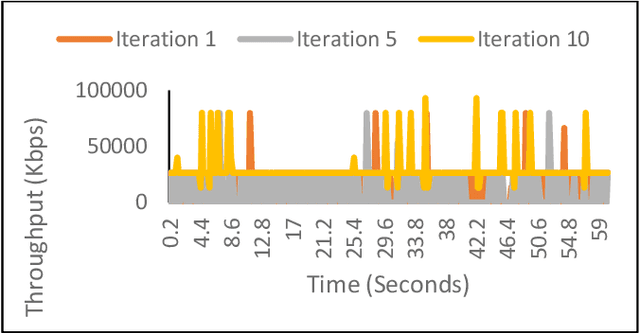
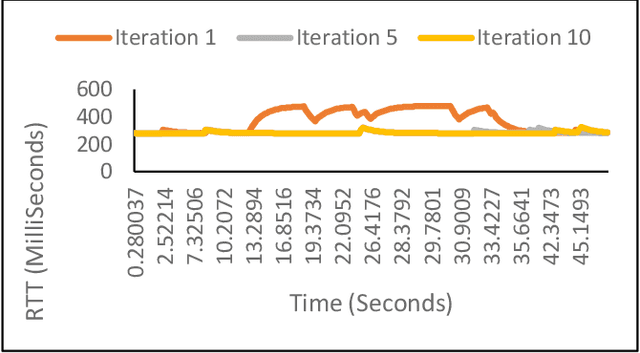
Congestion Control (CC), as the core networking task to efficiently utilize network capacity, received great attention and widely used in various Internet communication applications such as 5G, Internet-of-Things, UAN, and more. Various CC algorithms have been proposed both on network and transport layers such as Active Queue Management (AQM) algorithm and Transmission Control Protocol (TCP) congestion control mechanism. But it is hard to model dynamic AQM/TCP system and cooperate two algorithms to obtain excellent performance under different communication scenarios. In this paper, we explore the performance of multi-agent reinforcement learning-based cross-layer congestion control algorithms and present cooperation performance of two agents, known as MACC (Multi-agent Congestion Control). We implement MACC in NS3. The simulation results show that our scheme outperforms other congestion control combination in terms of throughput and delay, etc. Not only does it proves that networking protocols based on multi-agent deep reinforcement learning is efficient for communication managing, but also verifies that networking area can be used as new playground for machine learning algorithms.
Exploring Semantic Relationships for Unpaired Image Captioning
Jun 20, 2021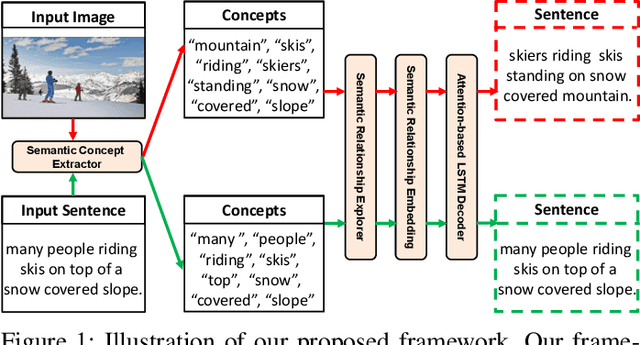
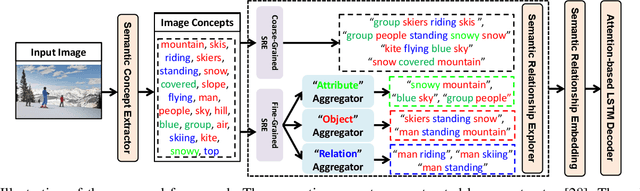
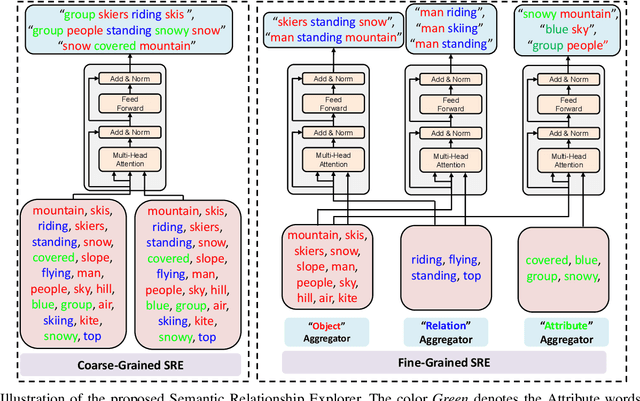

Recently, image captioning has aroused great interest in both academic and industrial worlds. Most existing systems are built upon large-scale datasets consisting of image-sentence pairs, which, however, are time-consuming to construct. In addition, even for the most advanced image captioning systems, it is still difficult to realize deep image understanding. In this work, we achieve unpaired image captioning by bridging the vision and the language domains with high-level semantic information. The motivation stems from the fact that the semantic concepts with the same modality can be extracted from both images and descriptions. To further improve the quality of captions generated by the model, we propose the Semantic Relationship Explorer, which explores the relationships between semantic concepts for better understanding of the image. Extensive experiments on MSCOCO dataset show that we can generate desirable captions without paired datasets. Furthermore, the proposed approach boosts five strong baselines under the paired setting, where the most significant improvement in CIDEr score reaches 8%, demonstrating that it is effective and generalizes well to a wide range of models.
Decentralized Circle Formation Control for Fish-like Robots in the Real-world via Reinforcement Learning
Mar 09, 2021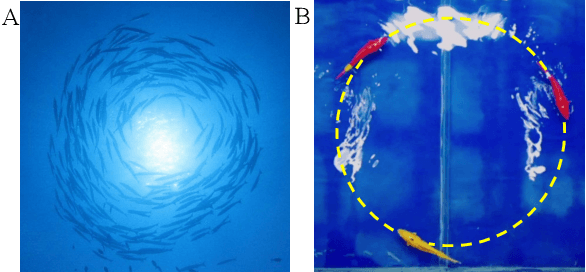
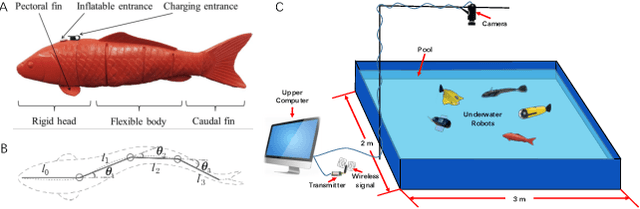
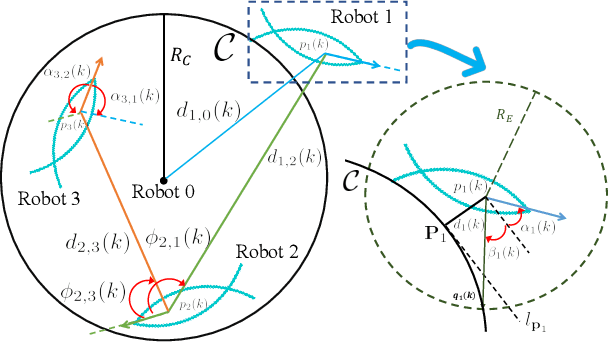
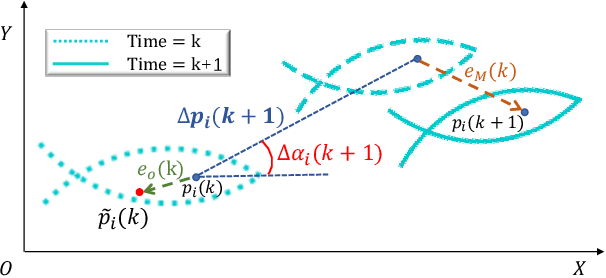
In this paper, the circle formation control problem is addressed for a group of cooperative underactuated fish-like robots involving unknown nonlinear dynamics and disturbances. Based on the reinforcement learning and cognitive consistency theory, we propose a decentralized controller without the knowledge of the dynamics of the fish-like robots. The proposed controller can be transferred from simulation to reality. It is only trained in our established simulation environment, and the trained controller can be deployed to real robots without any manual tuning. Simulation results confirm that the proposed model-free robust formation control method is scalable with respect to the group size of the robots and outperforms other representative RL algorithms. Several experiments in the real world verify the effectiveness of our RL-based approach for circle formation control.
Text as Neural Operator: Image Manipulation by Text Instruction
Aug 12, 2020
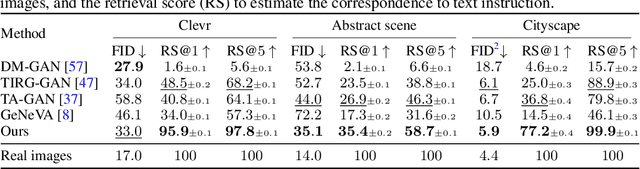
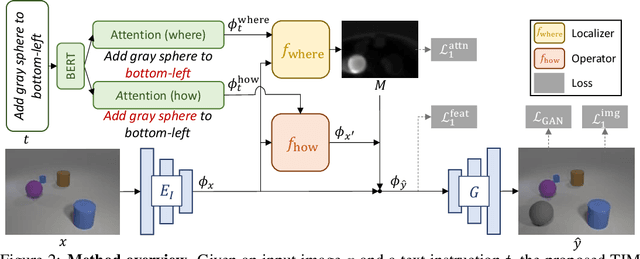
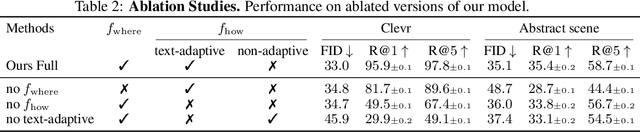
In this paper, we study a new task that allows users to edit an input image using language instructions. In this image generation task, the inputs are a reference image and a text instruction that describes desired modifications to the input image. We propose a GAN-based method to tackle this problem. The key idea is to treat language as neural operators to locally modify the image feature. To this end, our model decomposes the generation process into finding where (spatial region) and how (text operators) to apply modifications. We show that the proposed model performs favorably against recent baselines on three datasets.
Multimodal Image Synthesis with Conditional Implicit Maximum Likelihood Estimation
Apr 07, 2020



Many tasks in computer vision and graphics fall within the framework of conditional image synthesis. In recent years, generative adversarial nets (GANs) have delivered impressive advances in quality of synthesized images. However, it remains a challenge to generate both diverse and plausible images for the same input, due to the problem of mode collapse. In this paper, we develop a new generic multimodal conditional image synthesis method based on Implicit Maximum Likelihood Estimation (IMLE) and demonstrate improved multimodal image synthesis performance on two tasks, single image super-resolution and image synthesis from scene layouts. We make our implementation publicly available.