 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianying Ji
ACE : Off-Policy Actor-Critic with Causality-Aware Entropy Regularization
Feb 22, 2024
The varying significance of distinct primitive behaviors during the policy learning process has been overlooked by prior model-free RL algorithms. Leveraging this insight, we explore the causal relationship between different action dimensions and rewards to evaluate the significance of various primitive behaviors during training. We introduce a causality-aware entropy term that effectively identifies and prioritizes actions with high potential impacts for efficient exploration. Furthermore, to prevent excessive focus on specific primitive behaviors, we analyze the gradient dormancy phenomenon and introduce a dormancy-guided reset mechanism to further enhance the efficacy of our method. Our proposed algorithm, ACE: Off-policy Actor-critic with Causality-aware Entropy regularization, demonstrates a substantial performance advantage across 29 diverse continuous control tasks spanning 7 domains compared to model-free RL baselines, which underscores the effectiveness, versatility, and efficient sample efficiency of our approach. Benchmark results and videos are available at https://ace-rl.github.io/.
DrM: Mastering Visual Reinforcement Learning through Dormant Ratio Minimization
Oct 30, 2023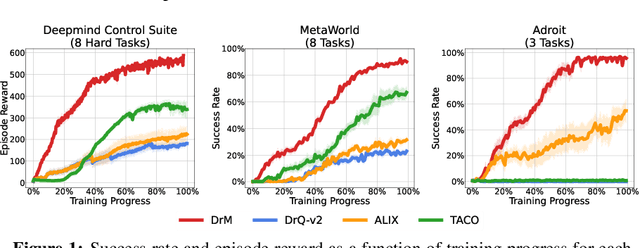

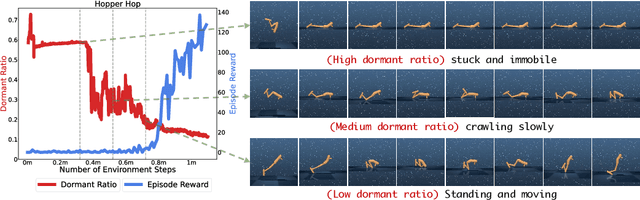

Visual reinforcement learning (RL) has shown promise in continuous control tasks. Despite its progress, current algorithms are still unsatisfactory in virtually every aspect of the performance such as sample efficiency, asymptotic performance, and their robustness to the choice of random seeds. In this paper, we identify a major shortcoming in existing visual RL methods that is the agents often exhibit sustained inactivity during early training, thereby limiting their ability to explore effectively. Expanding upon this crucial observation, we additionally unveil a significant correlation between the agents' inclination towards motorically inactive exploration and the absence of neuronal activity within their policy networks. To quantify this inactivity, we adopt dormant ratio as a metric to measure inactivity in the RL agent's network. Empirically, we also recognize that the dormant ratio can act as a standalone indicator of an agent's activity level, regardless of the received reward signals. Leveraging the aforementioned insights, we introduce DrM, a method that uses three core mechanisms to guide agents' exploration-exploitation trade-offs by actively minimizing the dormant ratio. Experiments demonstrate that DrM achieves significant improvements in sample efficiency and asymptotic performance with no broken seeds (76 seeds in total) across three continuous control benchmark environments, including DeepMind Control Suite, MetaWorld, and Adroit. Most importantly, DrM is the first model-free algorithm that consistently solves tasks in both the Dog and Manipulator domains from the DeepMind Control Suite as well as three dexterous hand manipulation tasks without demonstrations in Adroit, all based on pixel observations.
H2O+: An Improved Framework for Hybrid Offline-and-Online RL with Dynamics Gaps
Sep 22, 2023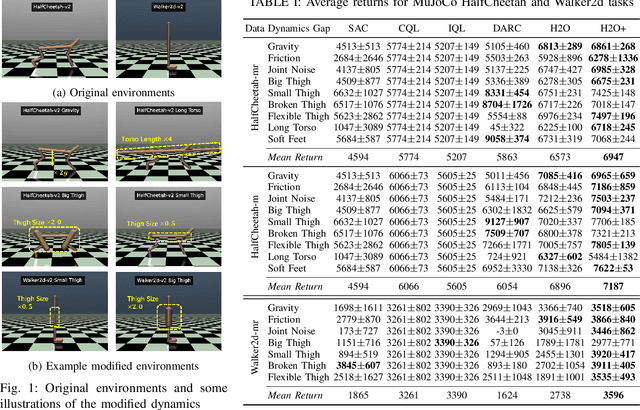
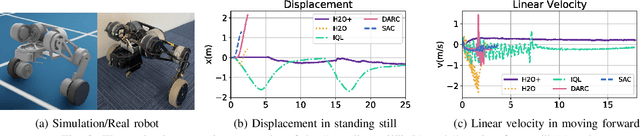
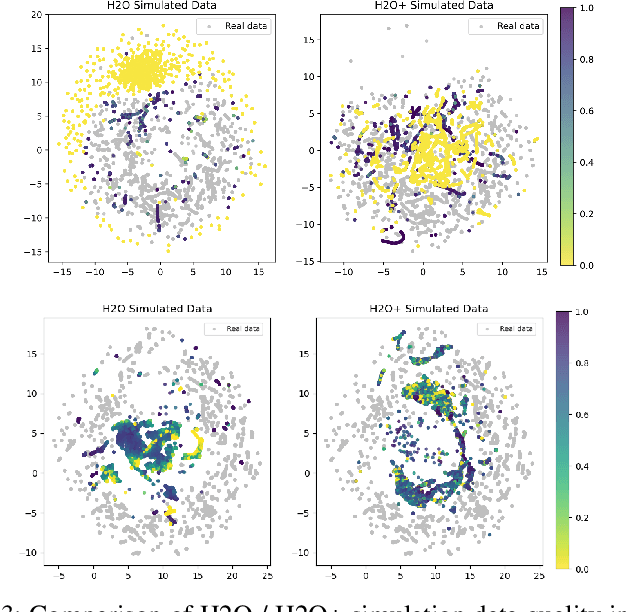
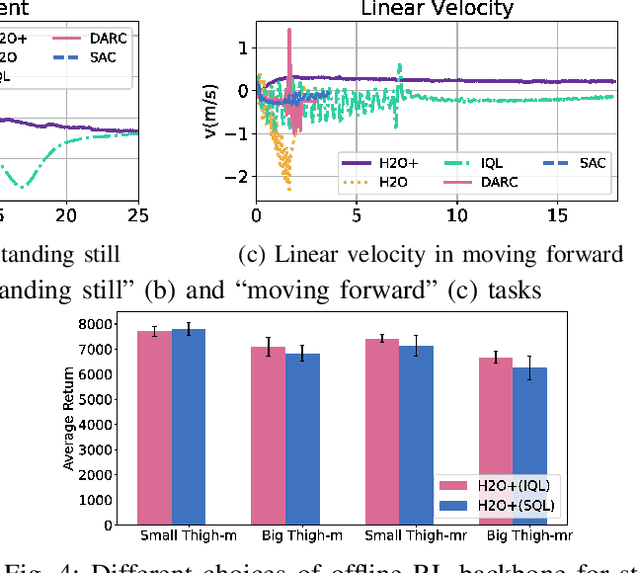
Solving real-world complex tasks using reinforcement learning (RL) without high-fidelity simulation environments or large amounts of offline data can be quite challenging. Online RL agents trained in imperfect simulation environments can suffer from severe sim-to-real issues. Offline RL approaches although bypass the need for simulators, often pose demanding requirements on the size and quality of the offline datasets. The recently emerged hybrid offline-and-online RL provides an attractive framework that enables joint use of limited offline data and imperfect simulator for transferable policy learning. In this paper, we develop a new algorithm, called H2O+, which offers great flexibility to bridge various choices of offline and online learning methods, while also accounting for dynamics gaps between the real and simulation environment. Through extensive simulation and real-world robotics experiments, we demonstrate superior performance and flexibility over advanced cross-domain online and offline RL algorithms.
Seizing Serendipity: Exploiting the Value of Past Success in Off-Policy Actor-Critic
Jun 06, 2023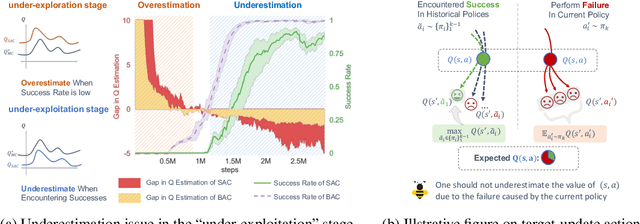
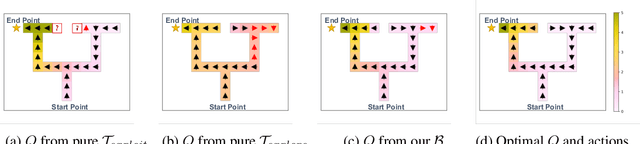
Learning high-quality Q-value functions plays a key role in the success of many modern off-policy deep reinforcement learning (RL) algorithms. Previous works focus on addressing the value overestimation issue, an outcome of adopting function approximators and off-policy learning. Deviating from the common viewpoint, we observe that Q-values are indeed underestimated in the latter stage of the RL training process, primarily related to the use of inferior actions from the current policy in Bellman updates as compared to the more optimal action samples in the replay buffer. We hypothesize that this long-neglected phenomenon potentially hinders policy learning and reduces sample efficiency. Our insight to address this issue is to incorporate sufficient exploitation of past successes while maintaining exploration optimism. We propose the Blended Exploitation and Exploration (BEE) operator, a simple yet effective approach that updates Q-value using both historical best-performing actions and the current policy. The instantiations of our method in both model-free and model-based settings outperform state-of-the-art methods in various continuous control tasks and achieve strong performance in failure-prone scenarios and real-world robot tasks.
When to Update Your Model: Constrained Model-based Reinforcement Learning
Oct 15, 2022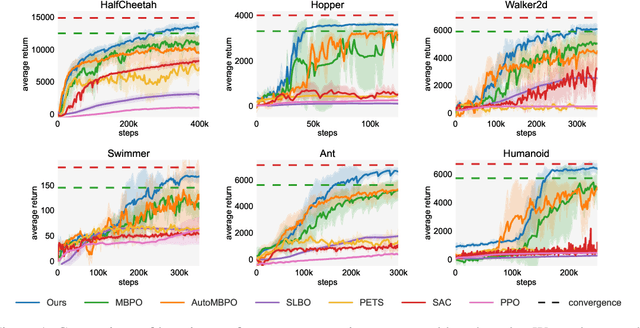

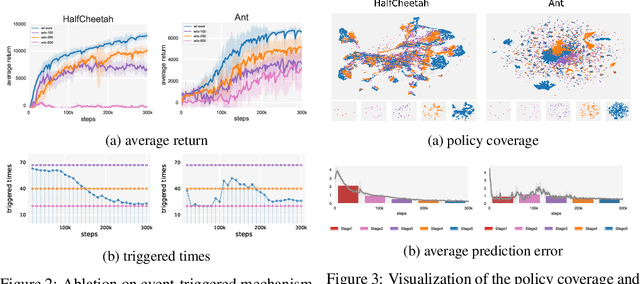
Designing and analyzing model-based RL (MBRL) algorithms with guaranteed monotonic improvement has been challenging, mainly due to the interdependence between policy optimization and model learning. Existing discrepancy bounds generally ignore the impacts of model shifts, and their corresponding algorithms are prone to degrade performance by drastic model updating. In this work, we first propose a novel and general theoretical scheme for a non-decreasing performance guarantee of MBRL. Our follow-up derived bounds reveal the relationship between model shifts and performance improvement. These discoveries encourage us to formulate a constrained lower-bound optimization problem to permit the monotonicity of MBRL. A further example demonstrates that learning models from a dynamically-varying number of explorations benefit the eventual returns. Motivated by these analyses, we design a simple but effective algorithm CMLO (Constrained Model-shift Lower-bound Optimization), by introducing an event-triggered mechanism that flexibly determines when to update the model. Experiments show that CMLO surpasses other state-of-the-art methods and produces a boost when various policy optimization methods are employed.
A Robust Tube-Based Smooth-MPC for Robot Manipulator Planning
Mar 17, 2021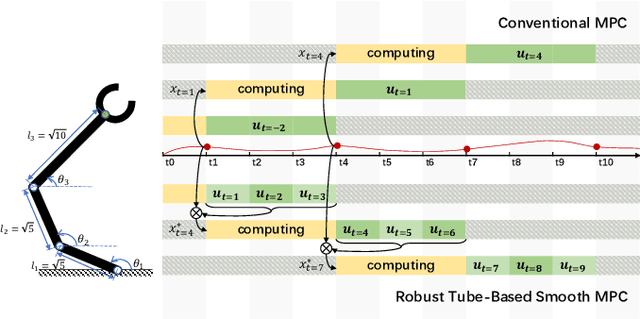
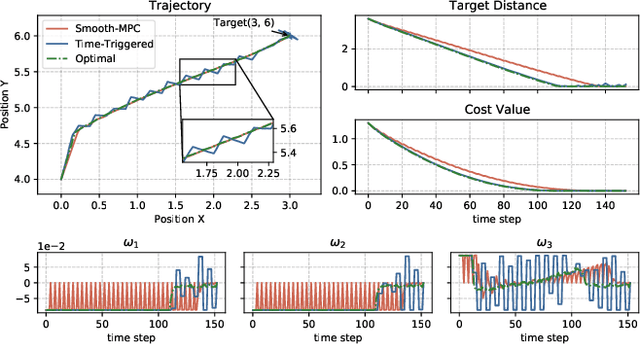

Model Predictive Control (MPC) has shown the great performance of target optimization and constraint satisfaction. However, the heavy computation of the Optimal Control Problem (OCP) at each triggering instant brings the serious delay from state sampling to the control signals, which limits the applications of MPC in resource-limited robot manipulator systems over complicated tasks. In this paper, we propose a novel robust tube-based smooth-MPC strategy for nonlinear robot manipulator planning systems with disturbances and constraints. Based on piecewise linearization and state prediction, our control strategy improves the smoothness and optimizes the delay of the control process. By deducing the deviation of the real system states and the nominal system states, we can predict the next real state set at the current instant. And by using this state set as the initial condition, we can solve the next OCP ahead and store the optimal controls based on the nominal system states, which eliminates the delay. Furthermore, we linearize the nonlinear system with a given upper bound of error, reducing the complexity of the OCP and improving the response speed. Based on the theoretical framework of tube MPC, we prove that the control strategy is recursively feasible and closed-loop stable with the constraints and disturbances. Numerical simulations have verified the efficacy of the designed approach compared with the conventional MPC.