 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiejun Zhao
DesignProbe: A Graphic Design Benchmark for Multimodal Large Language Models
Apr 23, 2024
A well-executed graphic design typically achieves harmony in two levels, from the fine-grained design elements (color, font and layout) to the overall design. This complexity makes the comprehension of graphic design challenging, for it needs the capability to both recognize the design elements and understand the design. With the rapid development of Multimodal Large Language Models (MLLMs), we establish the DesignProbe, a benchmark to investigate the capability of MLLMs in design. Our benchmark includes eight tasks in total, across both the fine-grained element level and the overall design level. At design element level, we consider both the attribute recognition and semantic understanding tasks. At overall design level, we include style and metaphor. 9 MLLMs are tested and we apply GPT-4 as evaluator. Besides, further experiments indicates that refining prompts can enhance the performance of MLLMs. We first rewrite the prompts by different LLMs and found increased performances appear in those who self-refined by their own LLMs. We then add extra task knowledge in two different ways (text descriptions and image examples), finding that adding images boost much more performance over texts.
Dual Instruction Tuning with Large Language Models for Mathematical Reasoning
Mar 27, 2024
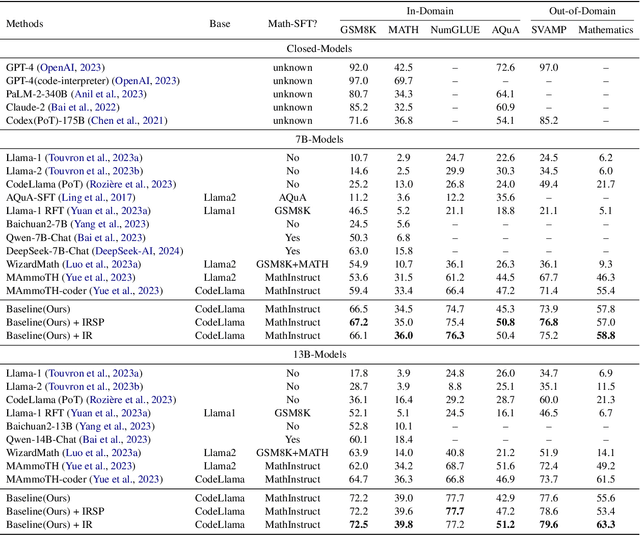

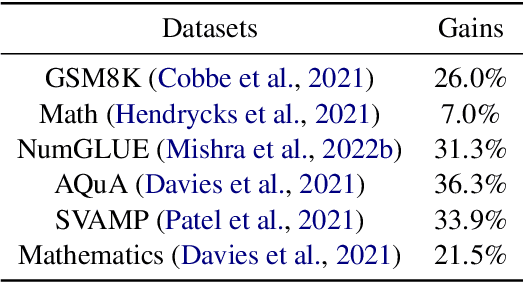
Recent advancements highlight the success of instruction tuning with large language models (LLMs) utilizing Chain-of-Thought (CoT) data for mathematical reasoning tasks. Despite the fine-tuned LLMs, challenges persist, such as incorrect, missing, and redundant steps in CoT generation leading to inaccuracies in answer predictions. To alleviate this problem, we propose a dual instruction tuning strategy to meticulously model mathematical reasoning from both forward and reverse directions. This involves introducing the Intermediate Reasoning State Prediction task (forward reasoning) and the Instruction Reconstruction task (reverse reasoning) to enhance the LLMs' understanding and execution of instructions. Training instances for these tasks are constructed based on existing mathematical instruction tuning datasets. Subsequently, LLMs undergo multi-task fine-tuning using both existing mathematical instructions and the newly created data. Comprehensive experiments validate the effectiveness and domain generalization of the dual instruction tuning strategy across various mathematical reasoning tasks.
Self-Evaluation of Large Language Model based on Glass-box Features
Mar 07, 2024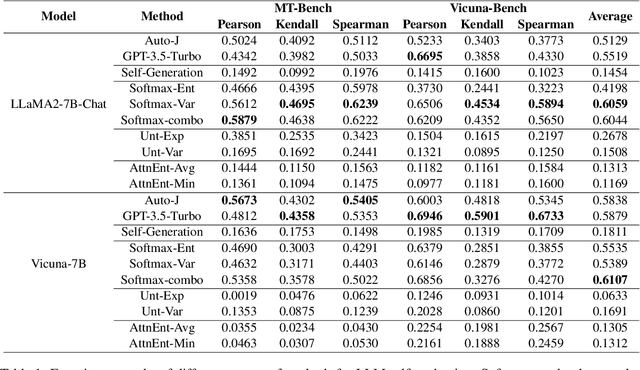

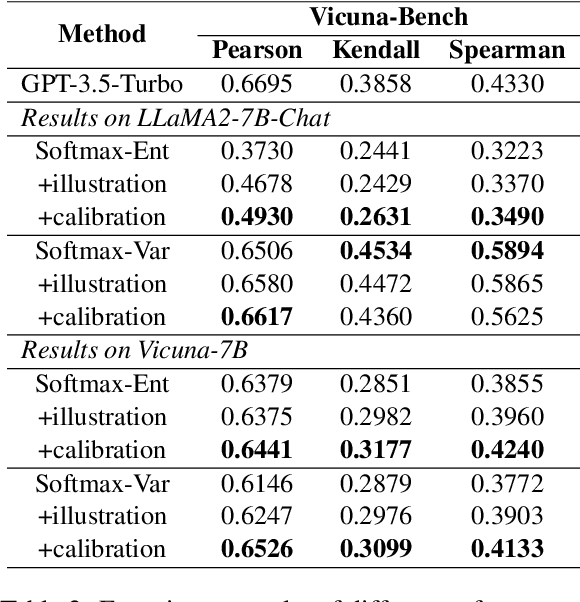

The proliferation of open-source Large Language Models (LLMs) underscores the pressing need for evaluation methods. Existing works primarily rely on external evaluators, focusing on training and prompting strategies. However, a crucial aspect - model-aware glass-box features - is overlooked. In this study, we explore the utility of glass-box features under the scenario of self-evaluation, namely applying an LLM to evaluate its own output. We investigate various glass-box feature groups and discovered that the softmax distribution serves as a reliable indicator for quality evaluation. Furthermore, we propose two strategies to enhance the evaluation by incorporating features derived from references. Experimental results on public benchmarks validate the feasibility of self-evaluation of LLMs using glass-box features.
An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers
Mar 05, 2024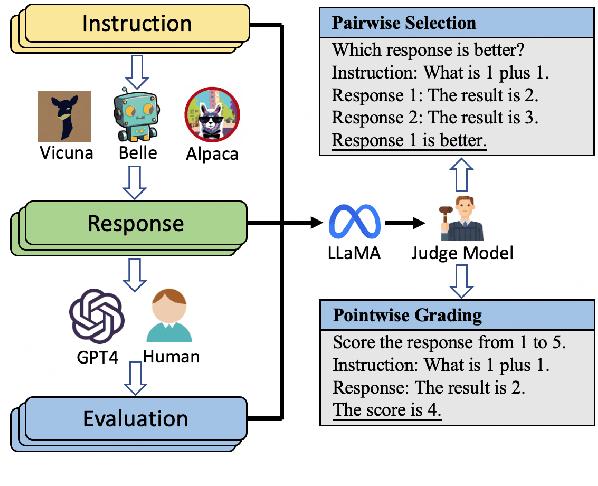
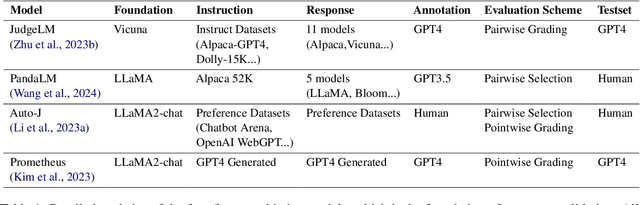
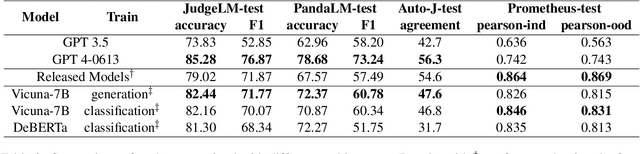

Recently, there has been a growing trend of utilizing Large Language Model (LLM) to evaluate the quality of other LLMs. Many studies have employed proprietary close-source models, especially GPT4, as the evaluator. Alternatively, other works have fine-tuned judge models based on open-source LLMs as the evaluator. In this study, we conduct an empirical study of different judge models on their evaluation capability. Our findings indicate that although the fine-tuned judge models achieve high accuracy on in-domain test sets, even surpassing GPT4, they are inherently task-specific classifiers, and their generalizability and fairness severely underperform GPT4.
LoRA-drop: Efficient LoRA Parameter Pruning based on Output Evaluation
Feb 12, 2024Low-Rank Adaptation (LoRA) introduces auxiliary parameters for each layer to fine-tune the pre-trained model under limited computing resources. But it still faces challenges of resource consumption when scaling up to larger models. Previous studies employ pruning techniques by evaluating the importance of LoRA parameters for different layers to address the problem. However, these efforts only analyzed parameter features to evaluate their importance. Indeed, the output of LoRA related to the parameters and data is the factor that directly impacts the frozen model. To this end, we propose LoRA-drop which evaluates the importance of the parameters by analyzing the LoRA output. We retain LoRA for important layers and the LoRA of the other layers share the same parameters. Abundant experiments on NLU and NLG tasks demonstrate the effectiveness of LoRA-drop.
Spot the Error: Non-autoregressive Graphic Layout Generation with Wireframe Locator
Jan 29, 2024Layout generation is a critical step in graphic design to achieve meaningful compositions of elements. Most previous works view it as a sequence generation problem by concatenating element attribute tokens (i.e., category, size, position). So far the autoregressive approach (AR) has achieved promising results, but is still limited in global context modeling and suffers from error propagation since it can only attend to the previously generated tokens. Recent non-autoregressive attempts (NAR) have shown competitive results, which provides a wider context range and the flexibility to refine with iterative decoding. However, current works only use simple heuristics to recognize erroneous tokens for refinement which is inaccurate. This paper first conducts an in-depth analysis to better understand the difference between the AR and NAR framework. Furthermore, based on our observation that pixel space is more sensitive in capturing spatial patterns of graphic layouts (e.g., overlap, alignment), we propose a learning-based locator to detect erroneous tokens which takes the wireframe image rendered from the generated layout sequence as input. We show that it serves as a complementary modality to the element sequence in object space and contributes greatly to the overall performance. Experiments on two public datasets show that our approach outperforms both AR and NAR baselines. Extensive studies further prove the effectiveness of different modules with interesting findings. Our code will be available at https://github.com/ffffatgoose/SpotError.
HopPG: Self-Iterative Program Generation for Multi-Hop Question Answering over Heterogeneous Knowledge
Sep 10, 2023

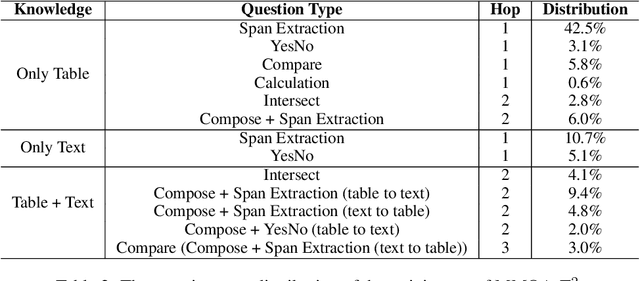

The semantic parsing-based method is an important research branch for knowledge-based question answering. It usually generates executable programs lean upon the question and then conduct them to reason answers over a knowledge base. Benefit from this inherent mechanism, it has advantages in the performance and the interpretability. However, traditional semantic parsing methods usually generate a complete program before executing it, which struggles with multi-hop question answering over heterogeneous knowledge. On one hand, generating a complete multi-hop program relies on multiple heterogeneous supporting facts, and it is difficult for generators to understand these facts simultaneously. On the other hand, this way ignores the semantic information of the intermediate answers at each hop, which is beneficial for subsequent generation. To alleviate these challenges, we propose a self-iterative framework for multi-hop program generation (HopPG) over heterogeneous knowledge, which leverages the previous execution results to retrieve supporting facts and generate subsequent programs hop by hop. We evaluate our model on MMQA-T^2, and the experimental results show that HopPG outperforms existing semantic-parsing-based baselines, especially on the multi-hop questions.
Learning and Evaluating Human Preferences for Conversational Head Generation
Aug 02, 2023
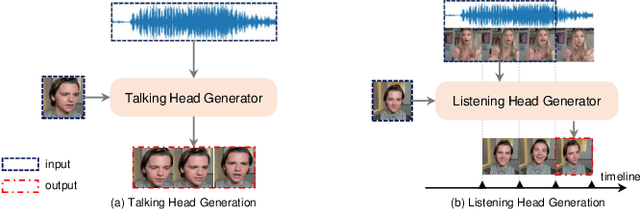
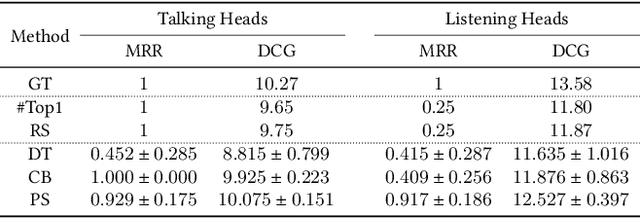
A reliable and comprehensive evaluation metric that aligns with manual preference assessments is crucial for conversational head video synthesis methods development. Existing quantitative evaluations often fail to capture the full complexity of human preference, as they only consider limited evaluation dimensions. Qualitative evaluations and user studies offer a solution but are time-consuming and labor-intensive. This limitation hinders the advancement of conversational head generation algorithms and systems. In this paper, we propose a novel learning-based evaluation metric named Preference Score (PS) for fitting human preference according to the quantitative evaluations across different dimensions. PS can serve as a quantitative evaluation without the need for human annotation. Experimental results validate the superiority of Preference Score in aligning with human perception, and also demonstrate robustness and generalizability to unseen data, making it a valuable tool for advancing conversation head generation. We expect this metric could facilitate new advances in conversational head generation. Project Page: https://https://github.com/dc3ea9f/PreferenceScore.
Interactive Conversational Head Generation
Jul 05, 2023
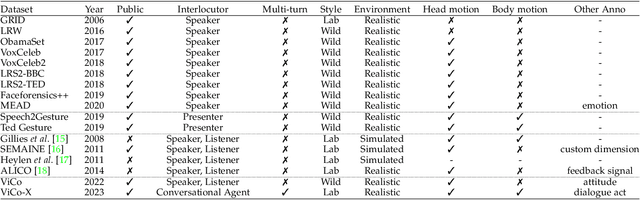
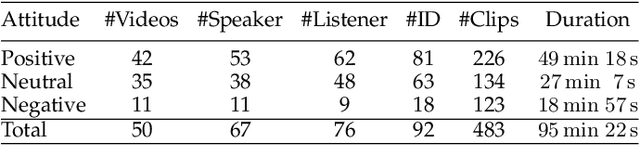

We introduce a new conversation head generation benchmark for synthesizing behaviors of a single interlocutor in a face-to-face conversation. The capability to automatically synthesize interlocutors which can participate in long and multi-turn conversations is vital and offer benefits for various applications, including digital humans, virtual agents, and social robots. While existing research primarily focuses on talking head generation (one-way interaction), hindering the ability to create a digital human for conversation (two-way) interaction due to the absence of listening and interaction parts. In this work, we construct two datasets to address this issue, ``ViCo'' for independent talking and listening head generation tasks at the sentence level, and ``ViCo-X'', for synthesizing interlocutors in multi-turn conversational scenarios. Based on ViCo and ViCo-X, we define three novel tasks targeting the interaction modeling during the face-to-face conversation: 1) responsive listening head generation making listeners respond actively to the speaker with non-verbal signals, 2) expressive talking head generation guiding speakers to be aware of listeners' behaviors, and 3) conversational head generation to integrate the talking/listening ability in one interlocutor. Along with the datasets, we also propose corresponding baseline solutions to the three aforementioned tasks. Experimental results show that our baseline method could generate responsive and vivid agents that can collaborate with real person to fulfil the whole conversation. Project page: https://vico.solutions/.
Visual-Aware Text-to-Speech
Jun 21, 2023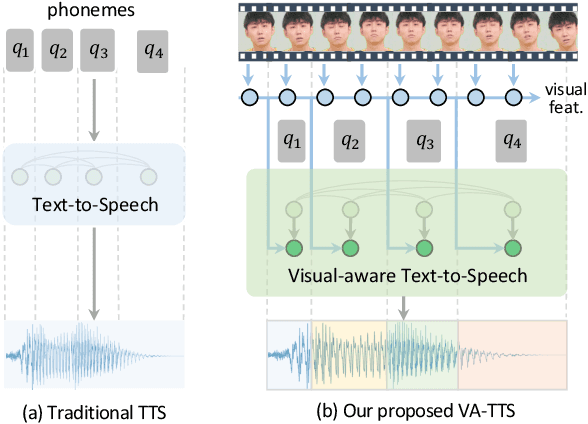
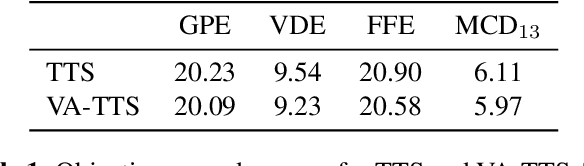

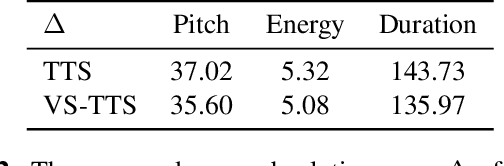
Dynamically synthesizing talking speech that actively responds to a listening head is critical during the face-to-face interaction. For example, the speaker could take advantage of the listener's facial expression to adjust the tones, stressed syllables, or pauses. In this work, we present a new visual-aware text-to-speech (VA-TTS) task to synthesize speech conditioned on both textual inputs and sequential visual feedback (e.g., nod, smile) of the listener in face-to-face communication. Different from traditional text-to-speech, VA-TTS highlights the impact of visual modality. On this newly-minted task, we devise a baseline model to fuse phoneme linguistic information and listener visual signals for speech synthesis. Extensive experiments on multimodal conversation dataset ViCo-X verify our proposal for generating more natural audio with scenario-appropriate rhythm and prosody.
* accepted as oral and top 3% paper by ICASSP 2023