 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimothee Mickus
I Have an Attention Bridge to Sell You: Generalization Capabilities of Modular Translation Architectures
Apr 30, 2024
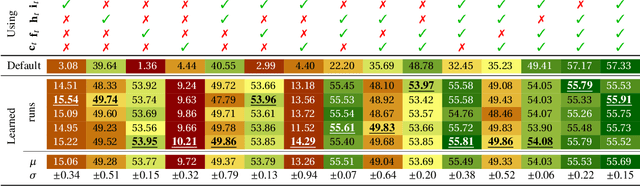
Modularity is a paradigm of machine translation with the potential of bringing forth models that are large at training time and small during inference. Within this field of study, modular approaches, and in particular attention bridges, have been argued to improve the generalization capabilities of models by fostering language-independent representations. In the present paper, we study whether modularity affects translation quality; as well as how well modular architectures generalize across different evaluation scenarios. For a given computational budget, we find non-modular architectures to be always comparable or preferable to all modular designs we study.
Can Machine Translation Bridge Multilingual Pretraining and Cross-lingual Transfer Learning?
Mar 25, 2024Multilingual pretraining and fine-tuning have remarkably succeeded in various natural language processing tasks. Transferring representations from one language to another is especially crucial for cross-lingual learning. One can expect machine translation objectives to be well suited to fostering such capabilities, as they involve the explicit alignment of semantically equivalent sentences from different languages. This paper investigates the potential benefits of employing machine translation as a continued training objective to enhance language representation learning, bridging multilingual pretraining and cross-lingual applications. We study this question through two lenses: a quantitative evaluation of the performance of existing models and an analysis of their latent representations. Our results show that, contrary to expectations, machine translation as the continued training fails to enhance cross-lingual representation learning in multiple cross-lingual natural language understanding tasks. We conclude that explicit sentence-level alignment in the cross-lingual scenario is detrimental to cross-lingual transfer pretraining, which has important implications for future cross-lingual transfer studies. We furthermore provide evidence through similarity measures and investigation of parameters that this lack of positive influence is due to output separability -- which we argue is of use for machine translation but detrimental elsewhere.
SemEval-2024 Shared Task 6: SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes
Mar 20, 2024

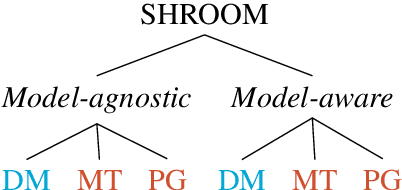
This paper presents the results of the SHROOM, a shared task focused on detecting hallucinations: outputs from natural language generation (NLG) systems that are fluent, yet inaccurate. Such cases of overgeneration put in jeopardy many NLG applications, where correctness is often mission-critical. The shared task was conducted with a newly constructed dataset of 4000 model outputs labeled by 5 annotators each, spanning 3 NLP tasks: machine translation, paraphrase generation and definition modeling. The shared task was tackled by a total of 58 different users grouped in 42 teams, out of which 27 elected to write a system description paper; collectively, they submitted over 300 prediction sets on both tracks of the shared task. We observe a number of key trends in how this approach was tackled -- many participants rely on a handful of model, and often rely either on synthetic data for fine-tuning or zero-shot prompting strategies. While a majority of the teams did outperform our proposed baseline system, the performances of top-scoring systems are still consistent with a random handling of the more challenging items.
MAMMOTH: Massively Multilingual Modular Open Translation @ Helsinki
Mar 12, 2024



NLP in the age of monolithic large language models is approaching its limits in terms of size and information that can be handled. The trend goes to modularization, a necessary step into the direction of designing smaller sub-networks and components with specialized functionality. In this paper, we present the MAMMOTH toolkit: a framework designed for training massively multilingual modular machine translation systems at scale, initially derived from OpenNMT-py and then adapted to ensure efficient training across computation clusters. We showcase its efficiency across clusters of A100 and V100 NVIDIA GPUs, and discuss our design philosophy and plans for future information. The toolkit is publicly available online.
Isotropy, Clusters, and Classifiers
Feb 05, 2024Whether embedding spaces use all their dimensions equally, i.e., whether they are isotropic, has been a recent subject of discussion. Evidence has been accrued both for and against enforcing isotropy in embedding spaces. In the present paper, we stress that isotropy imposes requirements on the embedding space that are not compatible with the presence of clusters -- which also negatively impacts linear classification objectives. We demonstrate this fact empirically and use it to shed light on previous results from the literature.
Grounded and Well-rounded: A Methodological Approach to the Study of Cross-modal and Cross-lingual Grounding
Oct 18, 2023Grounding has been argued to be a crucial component towards the development of more complete and truly semantically competent artificial intelligence systems. Literature has divided into two camps: While some argue that grounding allows for qualitatively different generalizations, others believe it can be compensated by mono-modal data quantity. Limited empirical evidence has emerged for or against either position, which we argue is due to the methodological challenges that come with studying grounding and its effects on NLP systems. In this paper, we establish a methodological framework for studying what the effects are - if any - of providing models with richer input sources than text-only. The crux of it lies in the construction of comparable samples of populations of models trained on different input modalities, so that we can tease apart the qualitative effects of different input sources from quantifiable model performances. Experiments using this framework reveal qualitative differences in model behavior between cross-modally grounded, cross-lingually grounded, and ungrounded models, which we measure both at a global dataset level as well as for specific word representations, depending on how concrete their semantics is.
Why bother with geometry? On the relevance of linear decompositions of Transformer embeddings
Oct 10, 2023A recent body of work has demonstrated that Transformer embeddings can be linearly decomposed into well-defined sums of factors, that can in turn be related to specific network inputs or components. There is however still a dearth of work studying whether these mathematical reformulations are empirically meaningful. In the present work, we study representations from machine-translation decoders using two of such embedding decomposition methods. Our results indicate that, while decomposition-derived indicators effectively correlate with model performance, variation across different runs suggests a more nuanced take on this question. The high variability of our measurements indicate that geometry reflects model-specific characteristics more than it does sentence-specific computations, and that similar training conditions do not guarantee similar vector spaces.
"Definition Modeling: To model definitions." Generating Definitions With Little to No Semantics
Jun 14, 2023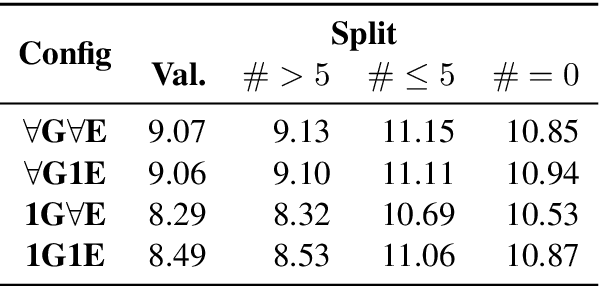
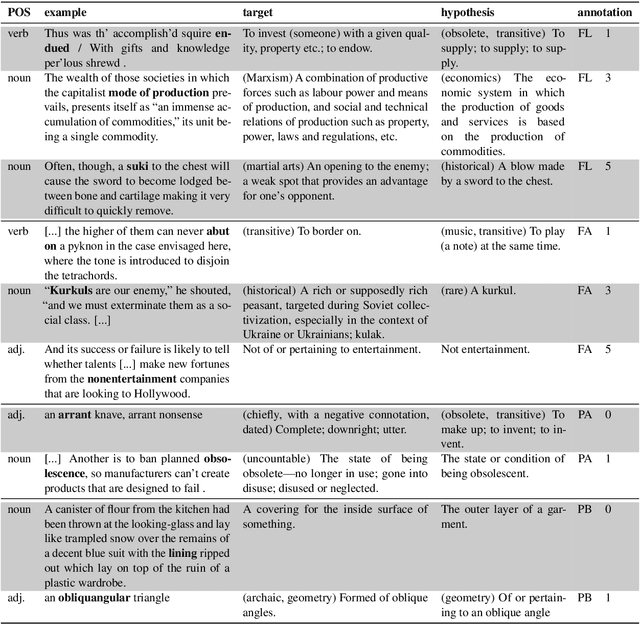

Definition Modeling, the task of generating definitions, was first proposed as a means to evaluate the semantic quality of word embeddings-a coherent lexical semantic representations of a word in context should contain all the information necessary to generate its definition. The relative novelty of this task entails that we do not know which factors are actually relied upon by a Definition Modeling system. In this paper, we present evidence that the task may not involve as much semantics as one might expect: we show how an earlier model from the literature is both rather insensitive to semantic aspects such as explicit polysemy, as well as reliant on formal similarities between headwords and words occurring in its glosses, casting doubt on the validity of the task as a means to evaluate embeddings.
How to Dissect a Muppet: The Structure of Transformer Embedding Spaces
Jun 07, 2022
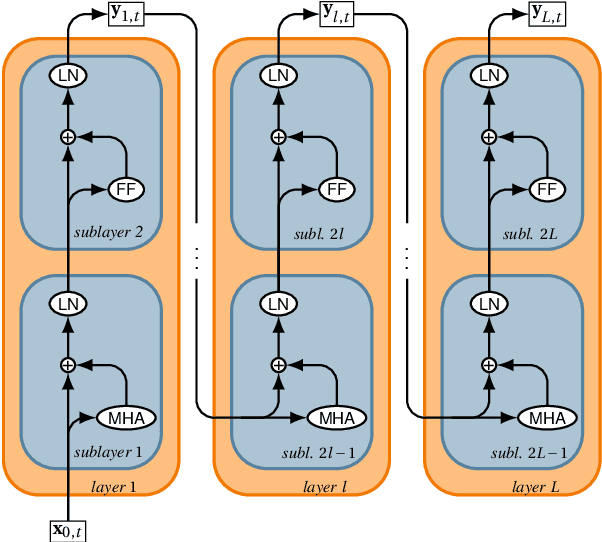
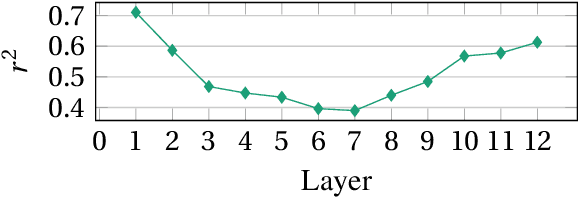
Pretrained embeddings based on the Transformer architecture have taken the NLP community by storm. We show that they can mathematically be reframed as a sum of vector factors and showcase how to use this reframing to study the impact of each component. We provide evidence that multi-head attentions and feed-forwards are not equally useful in all downstream applications, as well as a quantitative overview of the effects of finetuning on the overall embedding space. This approach allows us to draw connections to a wide range of previous studies, from vector space anisotropy to attention weights.
Semeval-2022 Task 1: CODWOE -- Comparing Dictionaries and Word Embeddings
May 27, 2022



Word embeddings have advanced the state of the art in NLP across numerous tasks. Understanding the contents of dense neural representations is of utmost interest to the computational semantics community. We propose to focus on relating these opaque word vectors with human-readable definitions, as found in dictionaries. This problem naturally divides into two subtasks: converting definitions into embeddings, and converting embeddings into definitions. This task was conducted in a multilingual setting, using comparable sets of embeddings trained homogeneously.